") 簡單隨機搜索:無模型強化學習的高效途徑
簡單隨機搜索:無模型強化學習的高效途徑
現(xiàn)在人們對無模型強化學習的一個普遍看法是,這種基于隨機搜索策略的方法在參數(shù)空間中比那些探索行為空間的方法表現(xiàn)出更差的樣本復雜性。UC Berkeley的研究人員通過引入隨機搜索方法,推翻了這種說法。以下是論智對作者Benjamin Recht博文的編譯。
我們已經(jīng)看到,隨機搜索在簡單的線性問題上表現(xiàn)得很好,而且似乎比一些強化學習方法(例如策略梯度)更好。然而隨著問題難度增加,隨機搜索是否會崩潰?答案是否定的。但是,請繼續(xù)讀下去!
讓我們在強化學習社區(qū)感興趣的問題上應用隨機搜索。深度強化學習領(lǐng)域一直把大量時間和精力用于由OpenAI維護的、基于MuJoCo模擬器的一套基準測試中。這里,最優(yōu)控制問題指的是讓一個有腿機器人在一個方向上盡可能快地行走,越遠越好。其中一些任務非常簡單,但是有些任務很難,比如這種有22個自由度的復雜人形模型。有腿機器人的運動由Hamilton方程控制,但是從這些模型中計劃動作是非常具有挑戰(zhàn)性的,因為沒有設(shè)計目標函數(shù)的最佳方法,并且模型是分段線性的。只要機器人的任何部位碰到堅硬物體,模型就會變化,因此會出現(xiàn)此前沒有的作用于機器人的法向力。于是,讓機器人無需處理復雜的非凸非線性模型而正常工作,對強化學習來說是個有趣的挑戰(zhàn)。
最近,Salimans及其在OpenAI的合作者表示,隨機搜索在這些標準測試中表現(xiàn)的很好,尤其是加上幾個算法增強后很適合神經(jīng)網(wǎng)絡(luò)控制器。在另一項實驗中,Rajeswaran等人表示,自然策略梯度可以學習用于完成標準的先行策略。也就是說,他們證明靜態(tài)線性狀態(tài)的反饋——就像我們在LQR(Linear Quadratic Regulator)中使用的那樣——也足以控制這些復雜的機器人模擬器。但這仍然有一個問題:簡單隨機搜索能找到適合MuJoCo任務的線性控制器嗎?
我的學生Aurelia Guy和Horia Mania對此進行了測試,他們編寫了一個非常簡單的隨機搜索版本(是我之前發(fā)布的Iqrpols.py中的一個)。令人驚訝的是,這個簡單的算法學習了Swimmer-v1,Hopper-v1,Walker2d-v1和Ant-v1任務中的線性策略,這些策略實現(xiàn)了之前文章中提出的獎勵閾值。不錯!
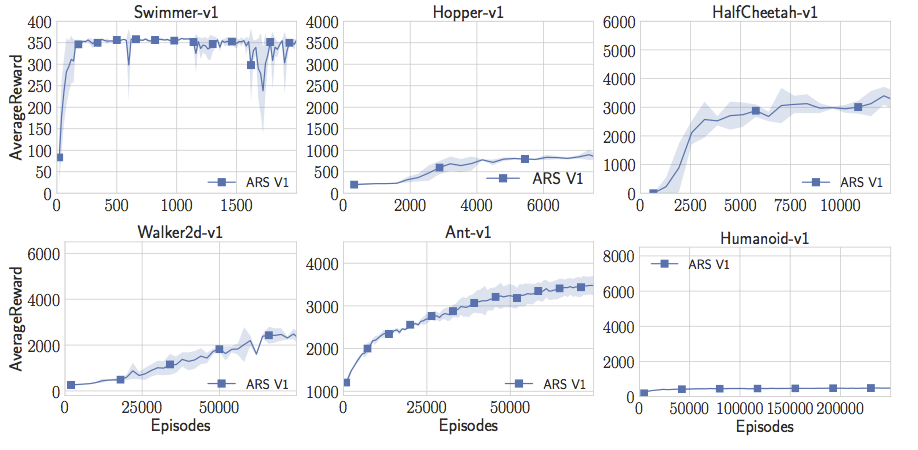
但是只有隨機搜索還不夠完美。Aurelia和Horia完全不能用人形模型做出有趣的事。試了很多次參數(shù)調(diào)整后,他們決定改進隨機搜索,讓它訓練地更快。Horia注意到許多強化學習的論文利用狀態(tài)的統(tǒng)計數(shù)據(jù),并且在將狀態(tài)傳遞給神經(jīng)網(wǎng)絡(luò)之前能夠?qū)顟B(tài)白化。所以他開始保持在線估計狀態(tài),在將他們傳遞給線性控制器之前將它們白化。有了這個簡單的竅門,Aurelia和Horia現(xiàn)在可以讓人形機器人做出最佳表現(xiàn)。這實際上是Salimans等人在標準值上達到的“成功閾值”的兩倍。只需要線性控制器、隨機搜索和一個簡單的技巧。
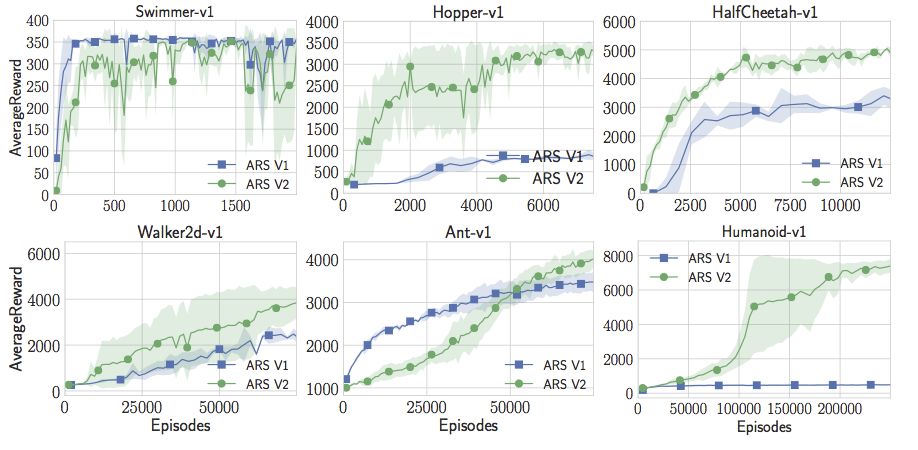
另外還有一件簡單的事情就是,代碼比OpenAI的進化策略論文中的要快15倍。我們可以用更少的計算獲得更高的獎勵。用戶可以在一小時內(nèi)在標準18核EC2實例上訓練一個高性能人形模型。
現(xiàn)在,隨著在線狀態(tài)的更新,隨機搜索不僅超過了人形模型的最佳水平,而且還超越了Swimmer-v1、Hopper-v1、HalfCheetah-v1。但在Walker2d-v1和Ant-v1上的表現(xiàn)還不是很好。但是我們可以再添加一個小技巧。我們可以放棄不會產(chǎn)生良好回報的采樣方向。這增加了一個超參數(shù),但有了這一額外的調(diào)整,隨機搜索實際上可能會達到或超過OpenAI的gym中所有MuJoCo標準的最佳性能。注意,這里并不限制與策略梯度的比較。就我所知,這些策略比任何無模型強化學習的應用結(jié)果要好,無論是Actor Critic Method還是Value Function Estimation Method等等更深奧的東西。對于這類MuJoCo問題,似乎純粹的隨機搜索優(yōu)于深度強化學習和神經(jīng)網(wǎng)絡(luò)。
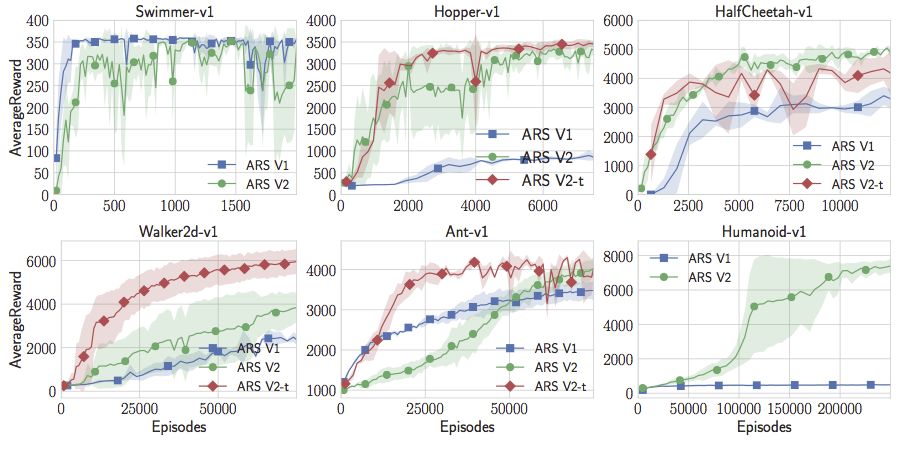
通過一些小調(diào)整得到的隨機搜索結(jié)果勝過了MuJoCo任務中的所有其他方法,并且速度更快。論文和代碼都已公布。
從隨機搜索中,我們有了以下幾點收獲:
基準很難
我認為所有這一切唯一合理的結(jié)論就是這些MuJoCo Demo很容易,毫無疑問。但是,用這些標準測試NIPS、ICML或ICLR中的論文可能不再合適。這就出現(xiàn)了一個重要的問題:什么是強化學習的良好標準?顯然,我們需要的不僅僅是Mountain Car。我認為具有未知動作的LQR是一個合理的任務,因為確定新實例并了解性能的限制是很容易的。但是該領(lǐng)域應該花更多時間了解如何建立有難度的標準。
不要在模擬器上抱太大希望
這些標準比較容易的一部分原因是MuJoCo不是一個完美的模擬器。MuJoCo非常快,并且對于概念驗證非常有用。但為了快速起見,它必須在接觸點周圍進行平滑處理(接觸的不連續(xù)是使腿部運動困難的原因)。因此,你只能讓其中一個模擬器走路,并不意味著你可以讓真正的機器人走路。的確,這里有四種讓獎勵可以達到6000的步態(tài),但看起來都不太現(xiàn)實:
即使是表現(xiàn)最好的模型(獎勵達到11600),如下圖所示,這種看起來很蠢的步態(tài)也不可能應用在現(xiàn)實中:
努力將算法簡化
在簡單算法中添加超參數(shù)和算法小部件,可以在足夠小的一組基準測試中提高其性能。我不確定是否放棄最好的方向或狀態(tài)歸一化會對新的隨機搜索問題起作用,但這對MuJoCo的標準和有用。通過添加更多可調(diào)參數(shù),甚至可以獲得更多回報。
使用之前先探索
注意,由于隨機搜索方法很快,我們可以評估它在許多隨機種子上的表現(xiàn)。這些無模型的方法在這些基準上都表現(xiàn)出驚人的巨大差異。例如,在人形任務中,即使我們提供了我們認為是好的參數(shù),模型的訓練時間也慢了四分之一。對于那些隨機種子,它會找到相當奇特的步態(tài)。如果將注意力限定在三個隨機種子上用于隨機搜索,通常具有誤導性,因為你可能會將性能調(diào)整為隨機數(shù)生成器的特性。
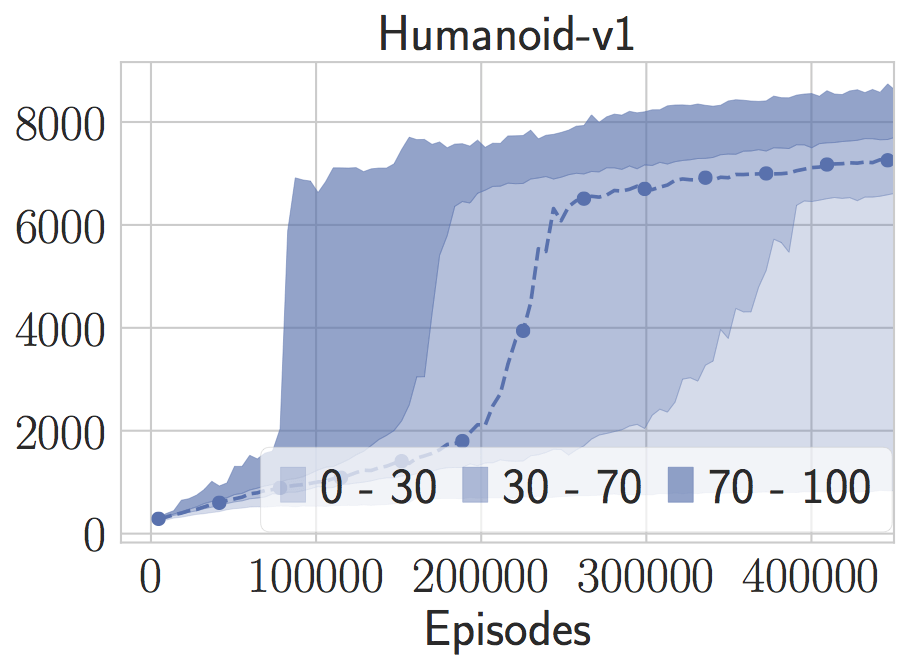
這種現(xiàn)象在LQR上也出現(xiàn)了。我們可以將算法向一些隨機種子進行微調(diào),然后在新的隨機種子上看到完全不同的行為。Henderson等人用深度強化學習方法觀察了這些現(xiàn)象,但我認為如此高的變量將成為所有無模型方法的通用癥狀。僅通過模擬就能解釋很多邊界情況。正如我在上一篇文章中所說的:“通過拋棄模型和知識,我們永遠不知道是否可以從少數(shù)實例和隨機種子中學到足夠的東西進行概括。”
-
強化學習
+關(guān)注
關(guān)注
4文章
268瀏覽量
11302
原文標題:簡單隨機搜索:強化學習的高效途徑
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
螞蟻集團收購邊塞科技,吳翼出任強化學習實驗室首席科學家
如何使用 PyTorch 進行強化學習
AI大模型與深度學習的關(guān)系
AI大模型與傳統(tǒng)機器學習的區(qū)別
谷歌AlphaChip強化學習工具發(fā)布,聯(lián)發(fā)科天璣芯片率先采用
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
【《大語言模型應用指南》閱讀體驗】+ 基礎(chǔ)知識學習
【《大語言模型應用指南》閱讀體驗】+ 基礎(chǔ)篇
深度學習中的無監(jiān)督學習方法綜述
tensorflow簡單的模型訓練
深度學習中的模型權(quán)重
通過強化學習策略進行特征選擇

【大語言模型:原理與工程實踐】揭開大語言模型的面紗
名單公布!【書籍評測活動NO.30】大規(guī)模語言模型:從理論到實踐
一文詳解Transformer神經(jīng)網(wǎng)絡(luò)模型






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論