 關于支持向量機(SVMs)
關于支持向量機(SVMs)
Content:
8.1 Optimization Objection
8.2 Large margin intuition
8.3 Mathematics Behind Large Margin Classification
8.4 Kernels
8.5 Using a SVM
8.5.1 Multi-class Classification
8.5.2 Logistic Regression vs. SVMs
8.1 Optimization Objection
支持向量機(Support Vector Machine: SVM)是一種非常有用的監督式機器學習算法。首先回顧一下Logistic回歸,根據log()函數以及Sigmoid函數的性質,有:
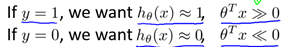
同時,Logistic回歸的代價函數(未正則化)如下:
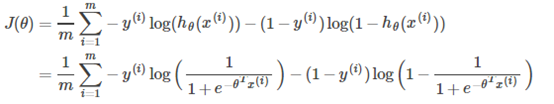
為得到SVM的代價函數,我們作如下修改:
因此,對比Logistic的優化目標
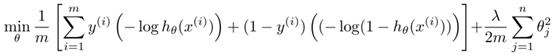
SVM的優化目標如下:
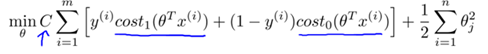
注1:事實上,上述公式中的Cost0與Cost1函數是一種稱為hinge損失的替代損失(surrogate loss)函數,其他常見的替代損失函數有指數損失和對率損失
注2:注意參數C和λ的對應關系: C與(1 / λ)成正相關。
8.2 Large margin intuition
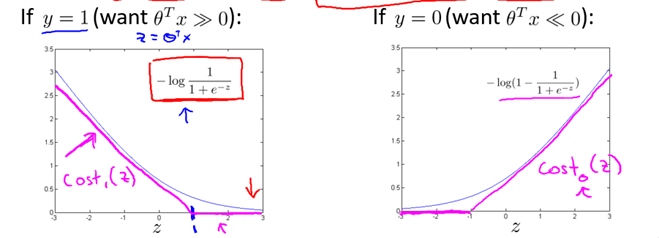
根據8.1中的代價函數,為使代價函數最小,有如下結論:
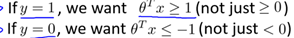
現假設C很大(如C=100000),為使代價函數最小,我們希望
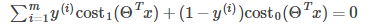
所以代價函數就變為:
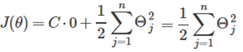
所以問題就變成:
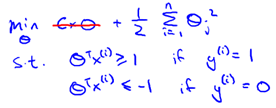
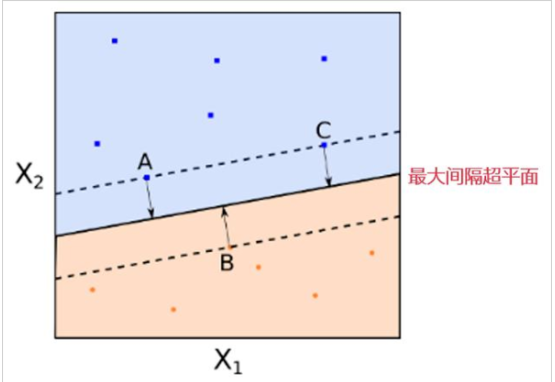
該問題最后的優化結果是找到具有"最大間隔"(maximum margin)的劃分超平面,所以支持向量機又稱大間距分類器(large margin classifier)。那么什么是間隔? 為什么這樣優化就可以找到最大間隔?首先,我們通過圖8-1所示的二維的0/1線性分類情況來直觀感受。
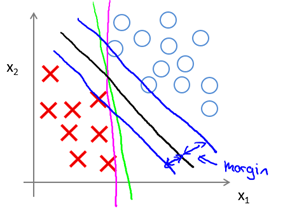
圖8-1 SVM Decision Boundary: Linearly separable case
直觀上,應該去找位于兩類訓練樣本"正中間"的劃分超平面,即圖8-1的黑色直線(二維),因為該劃分超平面對訓練樣本局部擾動的"容忍"性最好。例如,圖中的粉色和綠色直線,一旦輸入數據稍有變化,將會得到錯誤的預測。換言之,這個劃分超平面所產生的分類結果是最魯棒的,對要預測數據集的泛化能力最強。而兩條藍色直線之間的距離就稱為間隔(margin)。下一節將從數學角度來解釋間隔與最大間隔的優化原理。
8.3 Mathematics Behind Large Margin Classification
首先介紹一些數學知識。
2-范數(2-norm): 也可稱長度(length),是二維或三維空間向量長度的推廣,向量u記為||u||。例如,對于向量u = [ u1, u2, u3, u4],||u|| = sqrt(u1^2 + u2^2 + u3^2 + u4^2)
向量內積(Vector Inner Product): 設向量a = [a1, a2, … , an],向量b = [b1, b2, … , bn],a和b的的內積定義為:a · b = a1b1 + a2b2 + … + anbn 。向量內積是幾何向量數量積(點積)的推廣,可以理解為向量a在向量b上的投影長度(范數)和向量b的長度的乘積。
所以有:
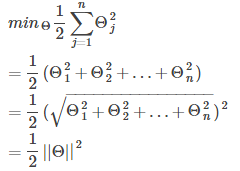
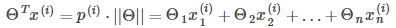
其中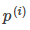 是
是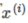 在
在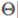 向量上的投影長度。
向量上的投影長度。
所以,8.2節得到的優化問題可以轉為如下形式:
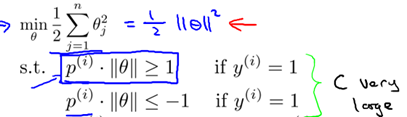
分界線為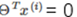 ,所以可知
,所以可知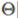 和分界線正交(垂直),并且當
和分界線正交(垂直),并且當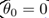 時,分界線過原點(歐式空間)。為使目標最優(取最小值)且滿足約束,
時,分界線過原點(歐式空間)。為使目標最優(取最小值)且滿足約束,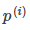 應該盡可能大,這樣就要求間距盡可能的大。直觀的如圖8-2所示,圖左為間距較小的情況,此時的
應該盡可能大,這樣就要求間距盡可能的大。直觀的如圖8-2所示,圖左為間距較小的情況,此時的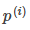 較小,為滿足約束,導致目標函數變大,圖右為最大間距的情況,此時的
較小,為滿足約束,導致目標函數變大,圖右為最大間距的情況,此時的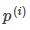 是最大的,所以目標可以盡可能的小。
是最大的,所以目標可以盡可能的小。
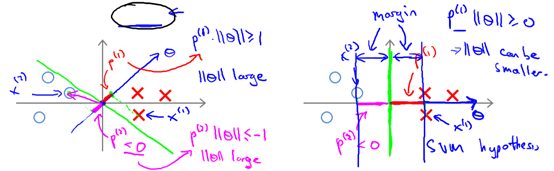
圖8-2 兩種不同間距的情況
8.4 Kernels
上述的討論都是基于線性可分的樣本,即存在一個劃分超平面可以將訓練樣本正確分類,然而現實世界存在大量復雜的,非線性分類問題(如4.4.2節的異或/同或問題)。Logistic回歸處理非線性問題可以通過引入多項式特征量作為新的特征量;神經網絡通過引入隱藏層,逐層進化解決非線性分類問題;而SVM是通過引入核函數(kernel function)來解決非線性問題。具體做法如下:
對于給定輸出x, 規定一定數量的landmarks,記為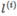 ;
;
將x,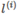 作為核函數的輸入,得到新的特征量
作為核函數的輸入,得到新的特征量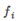 ,若將核函數記為similarity(),則有
,若將核函數記為similarity(),則有
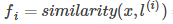 ,其中
,其中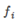 與
與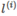 為一一對應;
為一一對應;
將新的特征量替代原有特征量,得到假設函數如下:
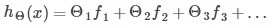
現在有兩個問題,
如何選擇landmarks?
用什么樣的核函數 ?
對于第一個問題,可以按照如下方式,即將訓練集的輸入作為landmarks
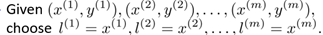
所以特征量的個數與訓練集的個數相等,即n = m,所以帶有核的SVM變為如下形式:

對于第二個問題,常用的核函數有線性核,高斯核,多項式核,Sigmoid核,拉普拉斯核等,現以常用的高斯核(Gaussian)為例。
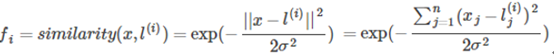
高斯核具有如下性質:
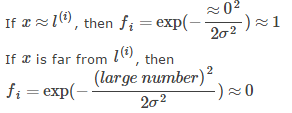
也就是說,如果x和landmark接近,那么核函數的值也就是新的特征量將會接近1,而如果x和landmark距離很遠,那么核函數的值將會接近0.
 是高斯核的參數,它的大小會影響核函數值的變化快慢,具體的,圖8-3是一個二維情況下的特殊例子,但是所含有的性質是可推廣的。即
是高斯核的參數,它的大小會影響核函數值的變化快慢,具體的,圖8-3是一個二維情況下的特殊例子,但是所含有的性質是可推廣的。即 越大,核函數變化(下降)越緩慢,反之,
越大,核函數變化(下降)越緩慢,反之, 越小,核函數變化越快。
越小,核函數變化越快。
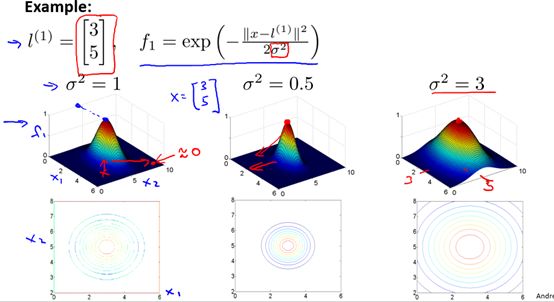
圖8-3 參數對高斯核的影響舉例
如何選擇參數?
下面對SVM的參數對偏差和方差的影響做簡要分析:
C: 由于C和(1 /λ)正相關,對λ的分析有:
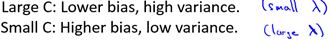

8.5 Using a SVM
上文簡單的介紹了SVM的優化原理以及核函數的使用方式。在實際應用SVM中,我們不需要自己去實現SVM的訓練算法來得到參數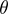 ,通常是使用現有的軟件包(如liblinear, libsvm)。
,通常是使用現有的軟件包(如liblinear, libsvm)。
但是下面的工作是我們需要做的:
選擇參數C的值
選擇并實現核函數
如果核函數帶參數,需要選擇核函數的參數,例如高斯核需要選擇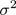
如果無核(選擇線性核),即給出線性分類器,適用于n大,m小的情況
選擇非線性核(如高斯核),適用于n小,m大的情況
下面是需要注意的地方:
在使用核函數之前要對特征量進行規范化
并不是所有的函數是有效的核函數,它們必須滿足Mercer定理。
如果想要通過訓練得到參數C或者核函數的參數,應該是在訓練集和交叉檢驗集上進行
8.5.1 Multi-class Classification

8.5.2 Logistic Regression vs. SVMs

-
向量機
+關注
關注
0文章
166瀏覽量
20924 -
機器學習
+關注
關注
66文章
8438瀏覽量
133080
原文標題:Stanford機器學習筆記-8. 支持向量機(SVMs)概述
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于支持向量機的預測函數控制
基于改進支持向量機的貨幣識別研究
基于支持向量機(SVM)的工業過程辨識
多分類孿生支持向量機研究進展
支持向量機的故障預測模型
機器學習-8. 支持向量機(SVMs)概述和計算
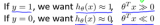
什么是支持向量機 什么是支持向量
介紹支持向量機的基礎概念






 工商網監
工商網監
評論