 如何用深度學習做圖像分類?教給你教程和代碼
如何用深度學習做圖像分類?教給你教程和代碼
深度學習推動計算機視覺、自然語言處理等諸多領域的快速發展。在AI大熱和人才奇缺的今天,掌握深度學習成為進入AI領域研究和應用的必備技能。來自亞馬遜主任科學家李沐將以計算機視覺的經典問題——圖像分類為例,手把手地教導大家從0到1搭建深度神經網絡模型。對于初學者面臨的諸多疑問,提供了從環境設置,數據處理,模型訓練,效果調優的完整介紹和代碼演示,包括使模型快速獲得良好效果的常用方法——遷移學習。讓大家有一個全景和基礎的了解。
深度學習時代,網絡的加深使得對訓練數據集規模的依賴更勝以往。學術界較成功的大規模數據集通常圍繞基礎性的一般認知問題,離有日常有體感的應用場景較遠。時尚與人們日常生活息息相關,但行業大量內容仍然依賴人工編輯。通過引入人工智能技術來提升效率,讓機器來認知時尚將是一個有趣且有用的課題。
近期,阿里巴巴圖像和美團隊與香港理工大學紡織及制衣學系聯合舉辦了2018FashionAI全球挑戰賽,并在比賽中開放的FashionAI數據集,是首個圍繞衣食住行中的“衣”的大規模高質量數據集。該數據集包含八種不同服飾的圖片數據,選手們的任務之一就是設計一個算法對圖片中服飾的屬性做出準確判斷。例如其中的裙子類圖片,就分為不可見,短裙,中裙,七分裙,九分裙和長裙等總共六種屬性。我們可以將其視為經典的圖片分類問題,并通過卷積神經網絡來解決。
FashionAI數據集中使用的圖像數據,全部來源于電商真實場景,刻畫了在模型在真實場景應用會遇到的挑戰。在FashoinAI數據集上訓練的模型,既有學術研究價值,又能在未來實際應用,幫助識別服飾上的專業設計元素。對于計算機視覺研究者來說,不失為一個好的選擇。
本文將利用MXNet進行方法講解。MXNet是一個易安裝易上手的開源深度學習工具,它提供了一個python接口gluon,能夠讓大家很快地搭建起神經網絡,并進行高效訓練。接下來,我們將以比賽中的裙子任務為例,向大家展示如何用gluon從零開始,設計一個簡單而又效果好的卷積神經網絡算法。
亞馬遜主任科學家 李沐
環境配置
系統配置
對于深度學習訓練而言,用GPU加速訓練是很重要的。這次競賽的數據量雖然不算大,但是只用CPU計算可能還是會讓一次模型訓練花上好幾天的時間!因此我們建議大家使用至少一塊GPU來進行訓練。還沒有GPU的同學,可以參考如下兩種選擇:
根據自己的預算和需求入手(年輕人的第)一塊GPU。我們寫了一篇GPU購買指南[1],方便大家選購。
為了這次比賽租用亞馬遜云的GPU服務器。我們寫了一篇AWS的運行教程[2],幫助大家配置自己的云服務器。
配置好了硬件與系統之后,我們需要安裝Nvidia提供的CUDA與CUDNN,從而把我們的代碼與GPU硬件真正連接起來。這部分的安裝比較容易,可以參考這一部分[3]的指導。
如果選擇使用亞馬遜云服務器,那么我們建議在選擇系統鏡像時選擇Deep Learning AMI,這個鏡像把與GPU訓練相關的環境(CUDA,CUDNN)都已經配置好了,不需要做其他的配置了。
安裝MXNet
配置好了環境之后,我們就可以安裝MXNet了。有很多種方式可以安裝MXNet,如果要在Linux系統上為python安裝GPU版本,只需要執行:

就可以了。如果系統中安裝的是CUDA8.0,可以將代碼改成對應的mxnet-cu80。如果有同學想要使用其他的語言接口或者是操作系統,或者是自己從源碼編譯,都可以在官方的安裝說明[4]中找到符合自己情況的安裝步驟。在接下來的教程中,我們使用MXNet的python接口gluon帶領大家上手此次競賽。
數據處理
數據獲取
首先我們在當前目錄下新建data文件夾,然后從官網上將熱身數據集,訓練數據集和測試數據集下載到data中并解壓。比賽的數據可以從比賽官網[5]獲取,不過同學們要登錄天池賬號并注冊參加比賽之后才能下載。主要的數據集有三個:
fashionAI_attributes_train_20180222.tar是主要訓練數據,里面含有八個任務的帶標記訓練圖片。這份教程中我們只選用其中的裙子任務做演示。
fashionAI_attributes_test_a_20180222.tar是預測數據,里面含有八個任務的不帶標記訓練圖片,我們的目的就是訓練出模型之后在這份數據上給出分類預測。
warm_up_train_20180201.tar是熱身數據,里面含有與訓練集不重復的裙子訓練集圖片,是對訓練數據很重要的補充。在進一步運行前,請確認當前的目錄結構是這樣的:

注意事項:下載好的數據在解壓前與解壓后會各占用約8G的硬盤空間,在接下來的數據整理中我們會將數據復制為更方便的目錄結構,因此請預留足夠的硬盤空間。
因為圖片數據集通常很大,因此gluon不會一次性將所有圖片讀入內存,而是在訓練過程中不斷讀取硬盤上的圖片文件。請有條件的同學將圖片存在SSD硬盤上,這樣可以避免數據讀取成為瓶頸,從而大幅提高訓練速度。
首先,我們在data下新建一個目錄train_valid,作為所有整理后數據的目錄。

我們選用裙子數據的原因之一,就是熱身數據與訓練數據中都提供了它的訓練圖片,從而能讓我們能夠有更豐富的訓練資源。下面我們將分別從熱身數據欲訓練數據的標記文件中:
讀取每張圖片的路徑和標簽
將這張圖片按照它的標簽放入data/train_valid目錄下對應的類別目錄中
將前90%的數據用做訓練,后10%的數據用作驗證
第一步,讀取訓練圖片的路徑和標簽。
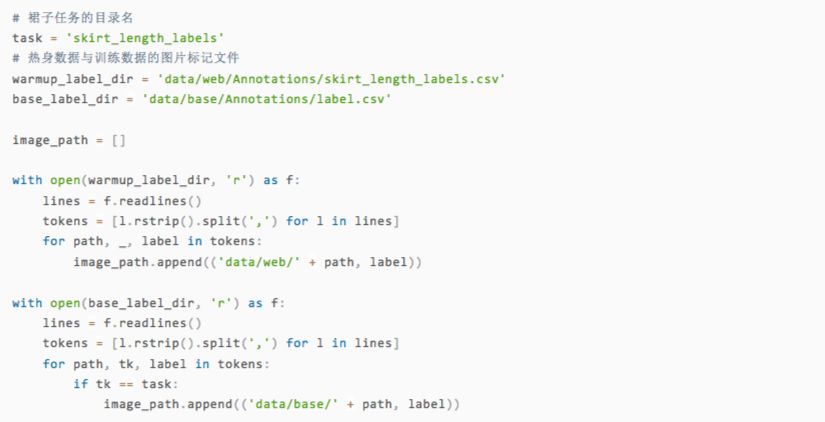
我們來檢查一下讀入的數據。image_path應該由路徑和圖片對應標簽組成,其中標簽是若干個n一個y組成的字符串,字母y出現的位置就是圖片對應的類型。


可以看出這張圖中的裙子是長裙,對應上官方的說明,可以發現與標記吻合。接下來,我們就準備好訓練集和測試集的目錄,以及6個裙子類別對應的子目錄。
運行后的目錄結構如下:
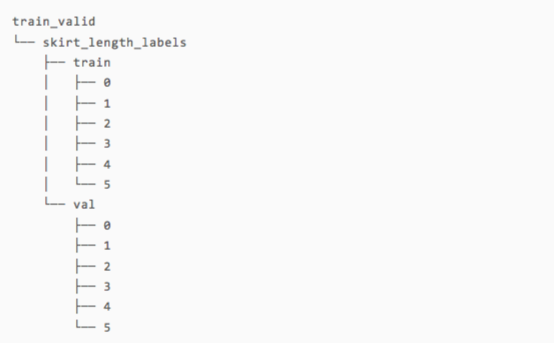
要想處理其他類型的服飾,只需要將task變量指定為對應的服飾類型名稱就行了。最后,我們將圖片復制到各自對應的目錄中。需要注意的是,這里我們刻意隨機打亂了圖片的順序,從而防止訓練集與測試集切分不均勻的情況出現。

遷移學習
數據準備完畢,接下來我們可以開始著手設計算法了。
服裝的識別可以被視作計算機視覺中的經典問題:圖片分類。一個典型的例子是ImageNet數據集與ILSVRC競賽,其中選手們要為分別從屬于1000個類別的逾1400萬張圖片設計算法,將它們準確分類。在服飾屬性判別競賽中,我們可以認為不同屬性的服飾從屬于不同的類別,于是便能參考ImageNet中的優勝算法來參賽。
在初賽階段,主辦方給每類服飾各提供了約一萬張圖片用來訓練,這樣的數據量還不足以讓我們從零開始訓練一個很棒的深度學習模型。于是我們可以借用遷移學習的想法,從一個在ImageNet數據集上被訓練好的模型出發,一點點把它改造成“更懂衣服”的模型。如下圖所示,左邊的是在ImageNet數據集上訓練好的網絡,右邊的是我們即將用來參賽的網絡,這兩個網絡主體結構一致,因此我們可以將主要的網絡權重都復制過來。因為兩個網絡在輸出層的分類個數與含義都不一樣,我們需要將輸出層重新定義并隨機初始化。
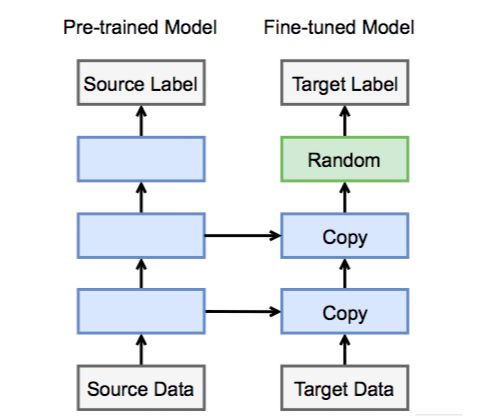
在ImageNet數據集上,大家主要用卷積神經網絡,而在過去的幾年中也出現了很多不同的網絡架構。gluon官方提供了許多不同的預訓練好的卷積神經網絡模型,我們在這個比賽中選擇效果比較好的resnet50_v2模型作為訓練的出發點。關于遷移學習更詳細的介紹可以參考gluon中文教程中的Fine-tuning:通過微調來遷移學習[6]一節。
首先,我們準備好需要用到的環境。

下面我們可以一句話導入預訓練好的resnet50_v2模型。如果是首次導入模型,代碼會需要一點時間下載預訓練好的模型。

在ImageNet上訓練的模型輸出是1000維的,我們需要定義一個新的resnet50_v2網絡,其中
輸出層之前的權重是預訓練好的
輸出是6維的,且輸出層的權重隨機初始化
之后,我們可以根據具體的機器環境選擇將網絡保存在CPU或者是GPU上。
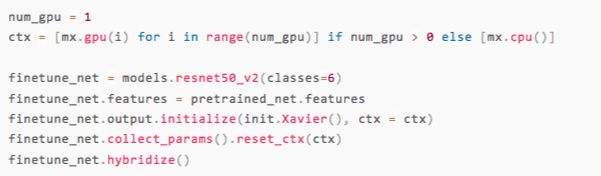
在上面代碼中的最后一行我們調用了hybridize,這是gluon的主要特性之一,能將命令式編程構建的模型在執行時把大部分運算轉成符號式來執行,這樣一方面提高了開發效率,同時也保證了運行速度。關于hybridize更詳細的介紹可以參考gluon中文教程中的Hybridize:更快和更好移植[7]一節。
接下來我們定義幾個輔助函數,它們分別是
計算AveragePrecision,官方的結果評價標準。
訓練集與驗證集的圖片增廣函數。
每輪訓練結束后在測試集上評估的函數
關于圖片增廣更詳細的介紹可以參考中文教程中的圖片增廣[8]一節。


下面我們定義一些訓練參數。注意,在遷移學習中,我們一般認為整個網絡的參數不需要進行很大地改動,只需要在訓練數據上微調,因此我們的學習速率都設為一個比較小的值,比如0.001。
為了方便演示,我們只循環兩輪訓練,展示過程。

接下來我們可以讀入數據了。經過之前的整理,數據可以用接口gluon.data.DataLoader讀入

下面我們定義網絡的優化算法和損失函數。這次比賽中我們選用隨機梯度下降就能得到比較好的效果。分類問題一般用交叉熵作為損失函數,另外,我們除了mAP指標之外也關心模型的準確率。

至此萬事俱備,我們可以開始訓練了!再次提醒,這里為了快速演示,我們只做兩次循環,為了達到更好的訓練效果請記得將epochs調大。
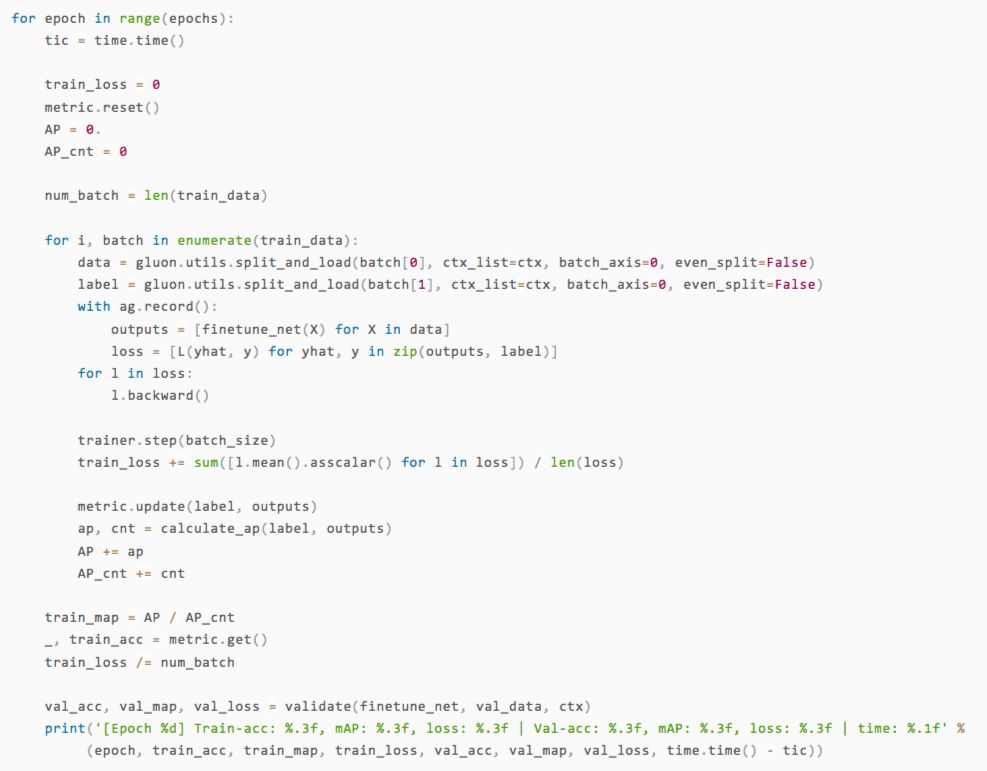

訓練結束了,那效果怎么樣呢?我們可以直接拿幾張測試集的圖片出來,用人眼對比一下看看預測的類型是否準確。
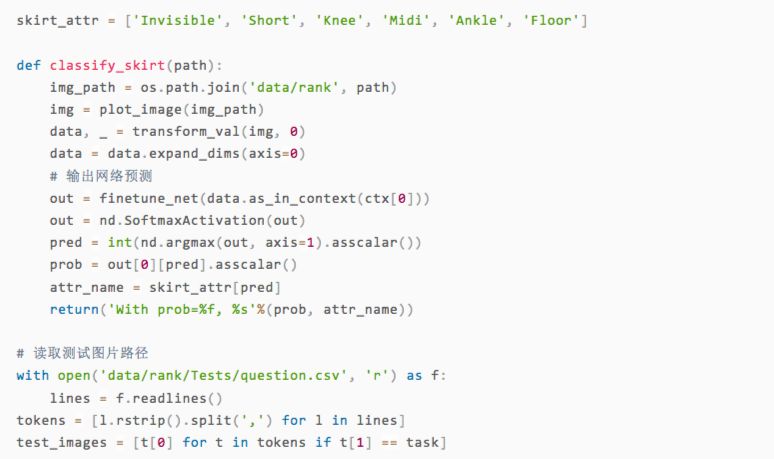


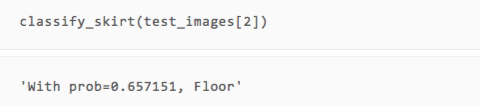
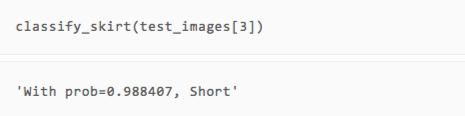
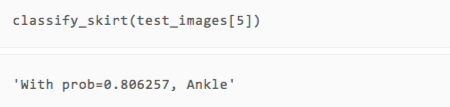
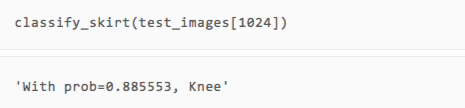
可以看到,雖然只有兩輪訓練,但我們的模型在展示的幾張圖片上都做出了正確的預測。
總結
至此,我們展示了從數據整理直到作出預測的樣例代碼。你可以從這里開始,不斷地改進代碼,向著更好的結果出發。也建議大家去下載FashoinAI數據集,直接用實踐本文中所學習到的技巧。下面我們給出一些可以改進的方向,你可以從他們開始著手:
1.調整參數,比如學習速率,批量大小,訓練循環次數等。
參數之間是有互相影響的,比如更小的學習速率可能意味著更多的循環次數。
建議以驗證集上的結果來選擇參數
不同數據的最佳參數可能是不一樣的,建議對每個任務選取相應的最佳參數
2.選擇模型。除了ResNet模型之外,gluon還提供很多其他流行的卷積神經網絡模型,可以到官方文檔根據它們在ImageNet上的表現進行選擇。
在計算資源有限的情況下,可以考慮選用占內存更小、計算速度更快的模型。
3.更全面的圖片增廣可以考慮在訓練時加上更多的圖片操作。image.CreateAugmenter函數有很多其他的參數,不妨分別試試效果。
在預測時將預測圖片做不同的裁剪/微調并分別預測,最后以平均預測值為最后答案,可以得到更穩健的結果。
特別感謝:作者/亞馬遜主任科學家 李沐
-
神經網絡
+關注
關注
42文章
4780瀏覽量
101174 -
AI
+關注
關注
87文章
31530瀏覽量
270342 -
深度學習
+關注
關注
73文章
5515瀏覽量
121553
原文標題:MXNet 作者李沐:用深度學習做圖像分類,教程+代碼
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
討論紋理分析在圖像分類中的重要性及其在深度學習中使用紋理分析
什么是深度學習?使用FPGA進行深度學習的好處?
圖像分類的方法之深度學習與傳統機器學習
基于數據挖掘的醫學圖像分類方法
一種新的目標分類特征深度學習模型
Xilinx FPGA如何通過深度學習圖像分類加速機器學習
深度學習中圖像分割的方法和應用
詳解深度學習之圖像分割
基于深度學習的圖像修復模型及實驗對比

OpenCV使用深度學習做邊緣檢測的流程






 工商網監
工商網監
評論