 基于Ceph對象存儲的混合云機制的深度解讀
基于Ceph對象存儲的混合云機制的深度解讀
1.背景
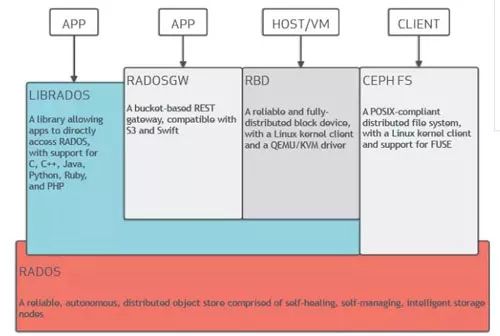
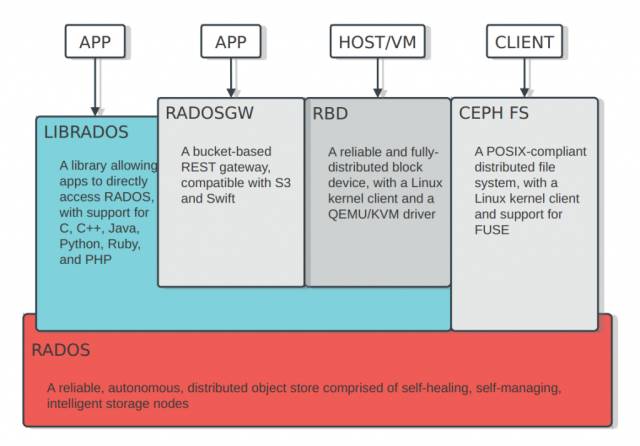
毫無疑問,乘著云計算發展的東風,Ceph已經是當今最火熱的軟件定義存儲開源項目。如下圖所示,它在同一底層平臺之上可以對外提供三種存儲接口,分別是文件存儲、對象存儲以及塊存儲,本文主要關注的是對象存儲即radosgw。
基于Ceph可方便快捷地搭建安全性好、可用性高、擴展性好的私有化存儲平臺。私有化存儲平臺雖然以其安全性的優勢受到越來越多的關注,但私有化存儲平臺也存在諸多弊端。 例如在如下場景中,某跨國公司需要在國外訪問本地的業務數據,我們該如何支持這種遠距離的數據訪問需求呢。如果僅僅是在私有化環境下,無非以下兩種解決方案:
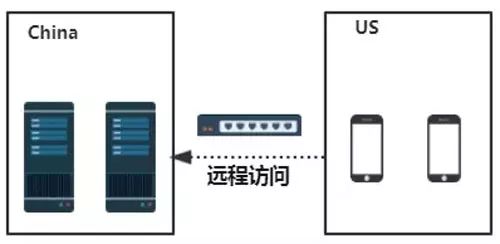
直接跨地域去訪問本地數據中心中的數據,毫無疑問,這種解決方案會帶來較高的訪問延遲。
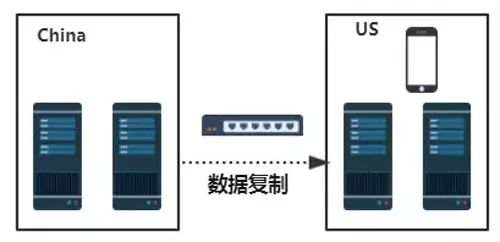
在國外自建數據中心,不斷將本地的數據異步復制到遠程數據中心,這種解決方案的缺點是成本太高。
在這種場景下,單純的私有云存儲平臺并不能很好的解決的上面的問題。但是,通過采用混合云解決方案卻能較好地滿足上述需求。對于前文所述遠距離數據訪問的場景,我們完全能借助公有云在遠程的數據中心節點作為存儲點,將本地數據中心的數據異步復制到公有云,再通過終端直接訪問公有云中的數據,這種方式在綜合成本和快捷性方面具備較大優勢,適合這種遠距離的數據訪問需求。
2.發展現狀:RGW Cloud Sync發展歷程
基于Ceph對象存儲的混合云機制是對Ceph生態的良好補充, 基于此,社區將在Mimic這個版本上發布RGW Cloud Sync特性,初步支持將RGW中的數據導出到支持s3協議的公有云對象存儲平臺,比如我們測試中使用的騰訊云COS,同Mulsite中的其他插件一樣,RGW Cloud Sync這個特性也是做成了一個全新的同步插件(目前稱之為aws sync module),能兼容支持S3協議。RGW Cloud Sync特性的整體發展歷程如下:
Suse公司貢獻了初始版本,這個版本僅支持簡單上傳;
Red Hat在這個初始版本之上實現了完整語義的支持,比如multipart上傳、刪除等,考慮到同步大文件的時候可能會造成內存爆炸的問題,還實現了流式上傳。
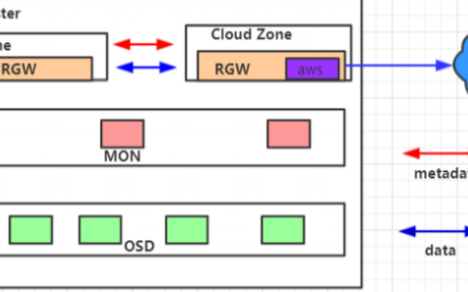
對于Ceph社區即將在M版本發布的這個公有云同步特性,進行了實際落地測試使用,并根據其中存在的問題進行了反饋及開發。在實際測試過程中,我們搭建了如下所示的運行環境:
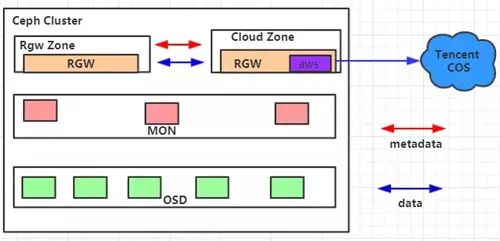
其中,Cloud Zone內部包含一個公有云同步插件,它被配置為只讀zone,用以將Rgw Zone中寫入的數據跨地域同步至騰訊云公有云對象存儲平臺COS之上。順利實現將數據從RGW中同步備份至公有云平臺,并且支持自由定制來實現將數據導入至不同云端路徑,同時我們還完善了同步狀態顯示功能,能較快監測到同步過程中發生的錯誤以及當前落后的數據等。
3.核心機制
Multisite
RGW Cloud Sync這個特性本質上是基于Multisite之上的一個全新的同步插件(aws sync module)。首先來看Multisite的一些核心機制。Multisite是RGW中數據遠程備份的一種解決方案,本質上來說它是一種基于日志的異步復制策略,下圖為一個Multisite的示意圖。
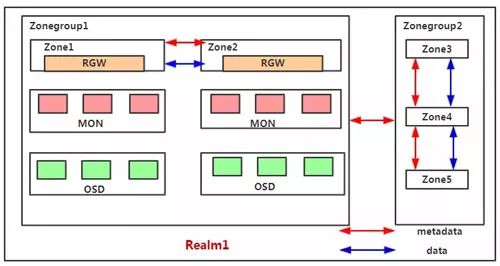
Multisite中主要有以下基本概念:
Zone:存在于一個獨立的Ceph集群,由一組rgw提供服務,對應一組后臺的pool;
Zonegroup:包含至少一個Zone,Zone之間同步數據和元數據;
Realm:一個獨立的命名空間,包含至少一個Zonegroup,Zonegroup之間同步元數據。
下面來看Multisite中的一些工作機制,分別是Data Sync、Async Framework、Sync Plugin這三部分。其中Data Sync部分主要分析Multisite中的數據同步流程,Async Framework部分會介紹Multisite中的協程框架,Sync Plugin部分會介紹Multisite中的一些同步插件。
Data Sync
Data Sync用以將一個Zonegroup內的數據進行備份,一個Zone內寫入的數據會最終同步到Zonegroup內所有Zone上,一個完整的Data Sync流程包含如下三步:
Init:將遠程的source zone與local zone建立日志分片對應關系,即將遠程的datalog映射到本地,后續通過datalog就知道有沒有數據需要更新;
Build Full Sync Map:獲取遠程bucket的元信息并建立映射關系來記錄bucket的同步狀態,如果配置multisite的時候source zone是沒有數據的,則這步會直接跳過;
Data Sync:開始object數據的同步,通過RGW api來獲取source zone的datalog并消費對應的bilog來同步數據。
下面以一個bucket中數據的增量同步來闡述Data Sync的工作機制。了解RGW的人都應該知道,一個bucket實例至少包含一個bucket shard,Data Sync是以bucket shard為單位來同步的,每個bucket shard有一個datalog shard 及bilog shard與之對應。
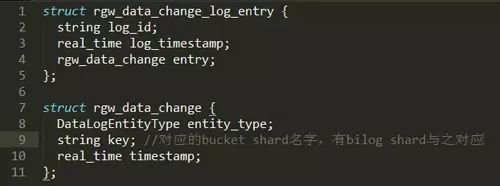
在建立完對應關系及進行完全量同步之后,本地Zone會記錄Sourcezone每個datalog 分片對應的sync_marker。此后local zone會定期將sync_marker與遠程datalog的max_marker比對,若仍有數據未同步,則通過rgw消費datalog entry,datalog entry中記錄了對應的bucket shard,消費bucket shard對應的bilog則可進行數據同步。如下面這個圖所示,遠程的datalog是以 gw_data_chang_log_entry這樣一種格式來存儲日志的,我們可發現,每條datalog entry中包含rgw_data_change這樣一個域,而rgw_data_change中包括的key這個域則是bucket shard的名字,之后就可以找到與之對應的bilog shard,從而消費bilog來進行增量同步。而全量同步其實就是沒有開始這個sync_marker,直接從頭開始消費datalog來進行數據同步。
Async Framework
RGW中使用的異步執行框架是基于boost::asio::coroutine這個庫來開發的,它是一個stackless coroutine,和常見的協程技術不同,Async Framework沒有使用ucontext技術來保存當前堆棧信息來支持協程,而是使用宏的技巧來達到類似效果,它通過 reenter/yield/fork 幾個偽關鍵字(宏)來實現協程。RGWCoroutine是RGW中定義的關于協程的抽象類,它本身也是boost::asio::coroutine 的子類,它是用于描述一個任務流的,包含一個待實現的隱式狀態機。RGWCoroutine可以call其他RGWCoroutine,也可以spawn一個并行的RGWCoroutine。
RGWCoroutine 類會包含一個 RGWCoroutinesStack成員,使用call調用其他RGWCoroutine的時候會將其對應的任務流都存儲在堆棧上,直到所有任務流完成之后控制權才會回到調用者處。然而,spawn一個新的RGWCoroutine時候會生成一個新的任務棧來存儲任務流,它不會阻塞當前正在執行的任務流。當一個協程需要執行一個異步IO操作的時候,它會標記自身為阻塞狀態,而這個IO事件會在任務管理器處注冊,一旦IO完成后任務管理器會解鎖當前堆棧,從而恢復這個協程的控制。下圖為一個簡單的協程使用例子,實現了一個有預定周期的請求處理器。
Sync Plugin
前文所述的數據同步過程是將數據從一個ceph zone同步到另一ceph zone,我們完全可以將過程抽象出來,使數據同步變得更加通用,方便添加不同的sync module來實現將數據遷移到不同的目的地。因為上層消費datalog的邏輯都是一致的,只有最后一步上層數據到目的地這步是不一樣的,因此我們只需實現數據同步和刪除的相關接口就可實現不同的同步插件,每個插件在RGW中都被稱為一個sync module,目前Ceph中有以下四個sync module:
rgw:默認sync module,用以在ceph zone之間同步數據
log:用于獲取object的擴展屬性并進行打印
elasticsearch:用于將數據的元信息同步至ES以支持一些搜索請求
aws:Mimic版本發布,用于導出RGW中的數據到支持S3協議的對象存儲平臺 4
RGW Cloud Sync
Streaming process
前文講到Suse公司貢獻了RGW Cloud Sync的初始版本,如下圖所示,它的一個同步流程邏輯上來說主要分為三步,第一通過aws sync module通過http connection將遠程的object拉取過來裝載至內存中,之后將這個object put到云端,之后云端會返回一個put result。
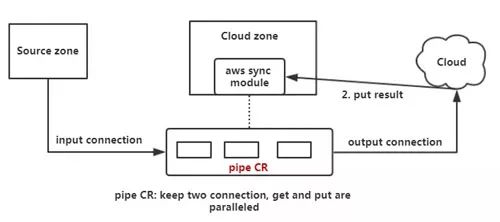
對于小文件來說,這個流程是沒問題的,但是如果這個object比較大的情況,全部load到內存中就有問題了,因此Red Hat在此基礎之上支持了Streaming process。本質上是使用了一個新的協程,這里稱之為pipe CR,它采用類似管道的機制,同時保持兩個http connection,一個用于拉取遠程object,一個用于上傳object,且這兩個過程是并行的,這樣可以有效防止內存爆炸,具體如下圖所示。
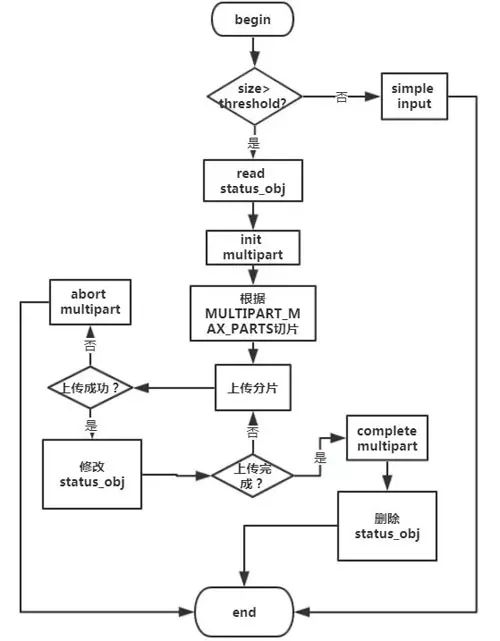
Multipart upload
Multipart upload是在Streaming process基礎之上用以支持大文件的分片上傳。它的整體流程如下:
Json config
公有云存儲環境相對來說比較復雜,需要更加復雜的配置來支持aws sync module的使用,因此Red Hat在這個插件上支持了json config。
相對其他插件來說主要增加了三個配置項,分別是host_style, acl_mapping,target_path,其中host_style是配置域名的使用格式,acl_mapping 是配置acl信息的同步方式,target_path是配置元數據在目的處的存放點。如下圖所示為一個實際使用的配置,它表示配置了aws zone,采用path-style這種域名格式,target_path是rgw加其所在zonegroup的名字并加上它的user_id,之后是它的bucket名字,最終這個object在云端的路徑就是target_path加上object名字。
5.關于RGW Cloud Sync方面的后續工作主要有以下四項:
同步狀態顯示的優化,比如顯示落后的datalog、bucket、object等,同時將一些同步過程中發生的錯誤上報至Monitor;
數據的反向同步,即支持將公有云的數據同步至RGW;
支持將RGW的數據導入更多的公有云平臺,而不是僅僅支持S3協議的平臺;
在此基礎之上以RGW為橋梁來實現不同云平臺之間的數據同步。
-
云計算
+關注
關注
39文章
7850瀏覽量
137875 -
存儲
+關注
關注
13文章
4355瀏覽量
86177
原文標題:深度解讀基于Ceph對象存儲的混合云機制
文章出處:【微信號:cunchujie,微信公眾號:存儲界】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于DPU的Ceph存儲解決方案
什么是對象存儲?
OC的消息轉發機制的深度解讀
深度解讀基于Ceph對象存儲的混合云機制
對象存儲的優勢有哪些?


數據存儲的全能俠——華為云對象存儲服務OBS
SDNLAB技術分享:Ceph在云英的實踐





 工商網監
工商網監
評論