 基于Keras搭建的深度學習網絡示例
基于Keras搭建的深度學習網絡示例
Python軟件基金會成員(Contibuting Member)Vihar Kurama簡明扼要地介紹了深度學習的基本概念,同時提供了一個基于Keras搭建的深度學習網絡示例。
深度學習背后的主要想法是,人工智能應該借鑒人腦。這一觀點帶來了“神經網絡”這一術語的興起。大腦包含數十億神經元,這些神經元之間有數萬連接。深度學習算法在很多情況下復現了大腦,大腦和深度學習模型都牽涉大量計算單元(神經元),這些神經元自身并不如何智能,但當它們互相交互時,變得智能起來。
我覺得人們需要了解深度學習在幕后讓很多事情變得更好。Google搜索和圖像搜索已經使用了深度學習技術;它允許你使用“擁抱”之類的詞搜索圖像。
—— Geoffrey Hinton
神經元
神經網絡的基本構件是人工神經元,人工神經元模擬人腦神經元。它們是簡單而強大的計算單元,基于加權的輸入信號,使用激活函數產出輸出信號。神經元遍布神經網絡的各層。
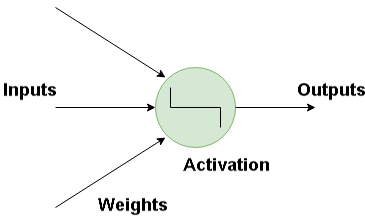
人工神經網絡如何工作?
深度學習包含建模人腦中的神經網絡的人工神經網絡。當數據流經這一人工網絡時,每層處理數據的一個方面,過濾離散值,識別類似實體,并產生最終輸出。
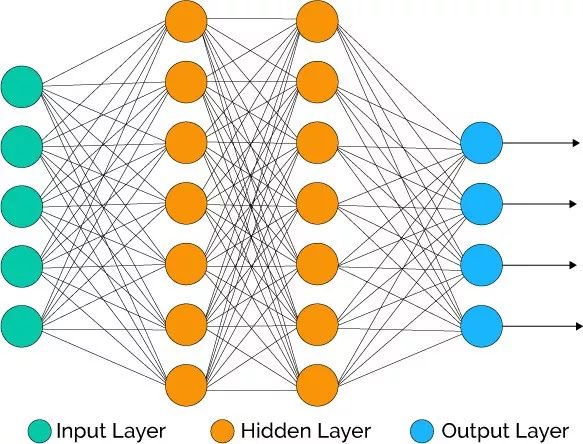
輸入層(Input Layer)這一層包含的神經元僅僅接受輸入并將其傳給其他層。輸入層中的神經元數目應當等于數據集的屬性數或特征數。
輸出層(Output Layer)輸出層輸出預測的特征,基本上,它取決于構建的具體模型類別。
隱藏層(Hidden Layer)在輸入層和輸出層之間的是隱藏層。在訓練網絡的過程中,隱藏層的權重得到更新,以提升其預測能力。
神經元權重
權重指兩個神經元之間的連接的強度,如果你熟悉線性回歸,你可以將輸入的權重想象成回歸公式中的系數。權重通常使用較小的隨機值初始化,例如0到1之間的值。
前饋深度網絡
前饋監督神經網絡是最早也是最成功的神經網絡模型之一。它們有時也稱為多層感知器(Multi-Layer Perceptron,MLP),或者簡單地直接稱為神經網絡。
輸入沿著激活神經元流經整個網絡直至生成輸出值。這稱為網絡的前向傳播(forward pass)。
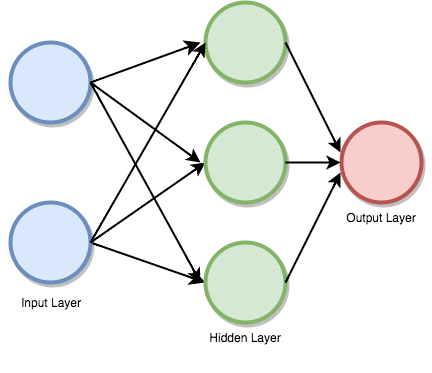
激活函數
激活函數將輸入的加權和映射至神經元的輸出。之所以被稱為激活函數,是因為它控制激活哪些神經元,以及輸出信號的強度。
有許多激活函數,其中最常用的是ReLU、tanh、SoftPlus。
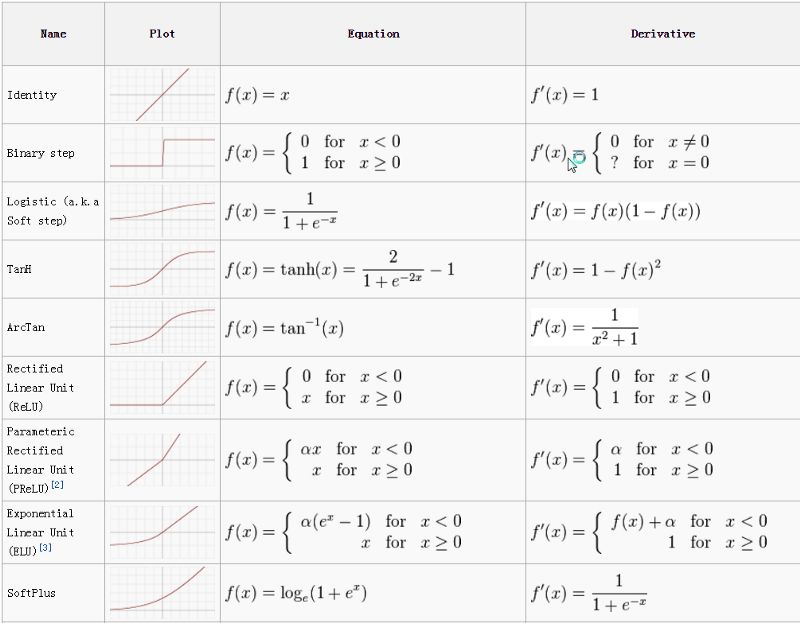
圖片來源:ml-cheatsheet
反向傳播
比較網絡的預測值和期望輸出,通過一個函數計算誤差。接著在整個網絡上反向傳播誤差,每次一層,權重根據其對誤差的貢獻作相應程度的更新。這稱為反向傳播(Back-Propagation)算法。在訓練集的所有樣本上重復這一過程。為整個訓練數據集更新網絡稱為epoch。網絡可能需要訓練幾十個、幾百個、幾千個epoch。
代價函數和梯度下降
代價函數衡量神經網絡在給定的訓練輸入和期望輸出上“有多好”。它也可能取決于權重或偏置等參數。
代價函數通常是標量,而不是向量,因為它評價的是網絡的整體表現。使用梯度下降(Gradient Descent)優化算法,權重在每個epoch后增量更新。
比如,誤差平方和(Sum of Squared Errors,SSE)就是一種常用的代價函數。
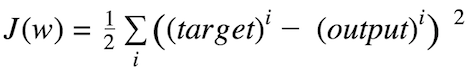
權重更新的幅度和方向通過計算代價梯度得出:
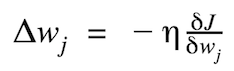
η為學習率
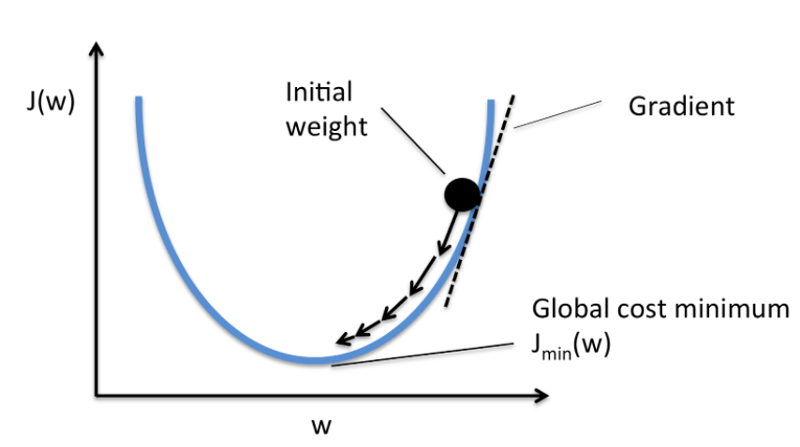
下為單個系數的代價函數梯度下降示意圖:
多層感知器(前向傳播)
多層感知器包含多層神經元,經常以前饋方式互相連接。每層中的每個神經元和下一層的神經元直接相連。在許多應用中,多層感知器使用sigmoid或ReLU激活函數。
現在讓我們來看一個例子。給定賬戶和家庭成員作為輸入,預測交易數。
首先我們需要創建一個多層感知器或者前饋神經網絡。我們的多層感知器將有一個輸入層、一個隱藏層、一個輸出層,其中,家庭成員數為2,賬戶數為3,如下圖所示:
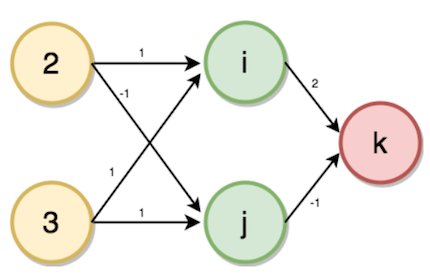
隱藏層(i、j)和輸出層(k)的值將使用如下的前向傳播過程計算:
i = (2 * 1) + (3 * 1) = 5
j = (2 * -1) + (3 * 1) = 1
k = (5 * 2) + (1 * -1) = 9
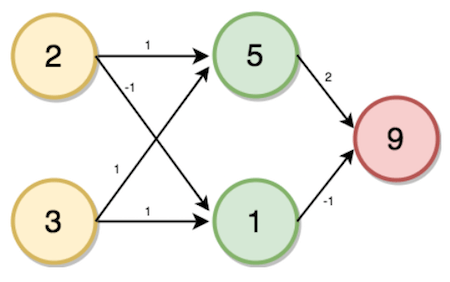
上面的計算過程沒有涉及激活函數,實際上,為了充分發揮神經網絡的預測能力,我們還需要使用激活函數,以引入非線性。
比如,使用ReLU激活函數:
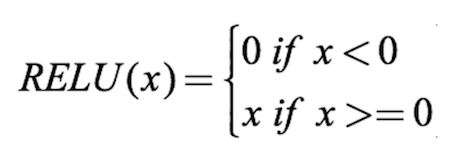
這一次,我們的輸入為[3, 4],權重分別為[2, 4], [4, -5], [2, 7]。
i = (3 * 2) + (4 * 4) = 22
i = relu(22) = 22
j = (3 * 4) + (4 * -5) = -8
j = relu(-8) = 0
k = (22 * 2) + (0 * 7) = 44
k = relu(44) = 44
基于Keras開發神經網絡
關于Keras
Keras是一個高層神經網絡API,基于Python,可以在TensorFlow、CNTK、Theano上運行。(譯者注:Theano已停止維護。)
運行以下命令可以使用pip安裝keras:
sudo pip install keras
在Keras中實現深度學習程序的步驟
加載數據
定義模型
編譯模型
訓練模型
評估模型
整合
開發Keras模型
keras使用Dense類描述全連接層。我們可以通過相應的參數指定層中的神經元數目,初始化方法,以及激活函數。定義模型之后,我們可以編譯(compile)模型。編譯過程將調用后端框架,比如TensorFlow。之后我們將在數據上運行模型。我們通過調用模型的fit()方法在數據上訓練模型。
from keras.models importSequential
from keras.layers importDense
import numpy
# 初始化隨機數值
seed = 7
numpy.random.seed(seed)
# 加載數據集(PIMA糖尿病數據集)
dataset = numpy.loadtxt('datasets/pima-indians-diabetes.csv', delimiter=",")
X = dataset[:, 0:8]
Y = dataset[:, 8]
# 定義模型
model = Sequential()
model.add(Dense(16, input_dim=8, init='uniform', activation='relu'))
model.add(Dense(8, init='uniform', activation='relu'))
model.add(Dense(1, init='uniform', activation='sigmoid'))
# 編譯模型
model.compile(loss='binary_crossentropy',
optimizer='adam', metrics=['accuracy'])
# 擬合模型
model.fit(X, Y, nb_epoch=150, batch_size=10)
# 評估
scores = model.evaluate(X, Y)
print("%s: %.2f%%" % (model.metrics_names[1], scores[1] * 100))
輸出:
$python keras_pima.py
768/768 [==============================] - 0s - loss: 0.6776 - acc: 0.6510
Epoch2/150
768/768 [==============================] - 0s - loss: 0.6535 - acc: 0.6510
Epoch3/150
768/768 [==============================] - 0s - loss: 0.6378 - acc: 0.6510
.
.
.
.
.
Epoch149/150
768/768 [==============================] - 0s - loss: 0.4666 - acc: 0.7786
Epoch150/150
768/768 [==============================] - 0s - loss: 0.4634 - acc: 0.773432/768
[>.............................] - ETA: 0sacc: 77.73%
我們訓練了150個epoch,最終達到了77.73%的精確度。
-
python
+關注
關注
56文章
4807瀏覽量
85037 -
深度學習
+關注
關注
73文章
5513瀏覽量
121549
原文標題:基于Python入門深度學習
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于 Python 的深度學習庫Keras入門知識
如何使用tensorflow快速搭建起一個深度學習項目
Nanopi深度學習之路(1)深度學習框架分析
【NanoPi K1 Plus試用體驗】搭建深度學習框架
使用keras搭建神經網絡實現基于深度學習算法的股票價格預測
深度學習框架Keras代碼解析
深度學習在各個領域有什么樣的作用深度學習網絡的使用示例分析






 工商網監
工商網監
評論