 機器學習中的特征選擇的5點詳細資料概述
機器學習中的特征選擇的5點詳細資料概述
1 特征選擇問題的概念
我們能用很多屬性描述一個客觀世界中的對象,例如對于描述一個人來說,可以獲取到身高、體重、年齡、性別、學歷、收入等等,但對于評判一個人的信用級別來說,往往只需要獲取他的年齡、學歷、收入這些信息。換言之,對一個學習任務來說,給定屬性集,其中有些屬性可能很關鍵、很有用,另一些屬性則可能沒什么用。我們將屬性稱為“特征” (feature),對當前學習任務有用的屬性稱為“相關特征” (relevant feature)、沒什么用的屬性稱為“無關特征” (irrelevant feature)。從給定的特征集合中選擇出相關特征子集的過程,稱為“特征選擇” (feature selection)。
特征選擇是一個重要的“數據預處理” (data preprocessing) 過程,在現實機器學習任務中,獲得數據之后通常先進行特征選擇,此后再訓練學習器。那么,為什么要進行特征選擇呢?
有兩個很重要的原因:
我們在現實任務中經常會遇到維數災難問題,這是由于屬性過多造成的,若能從中選擇出重要的特征,使得后續學習過程僅需在一部分特征上構建模型,則維數災難問題會大為減輕。
去除不相關特征往往會降低學習任務的難度,這就像偵探破案一樣,若將紛繁復雜的因素抽絲剝繭,只留下關鍵因素,則真相往往更易看清。
需要注意的是,特征選擇過程必須確保不丟失重要特征,否則后續學習過程會因為重要信息的缺失而無法獲得更好的性能。給定數據集,若學習任務不同,則相關特征很可能不同,因此,特征選擇中所謂的“無關特征”是指與當前學習任務無關。有一類特征稱為“冗余特征” (redundant feature),它們所包含的信息能從其他特征中推演出來。例如,考慮立方體對象,若已有特征“底面長”和“底面寬”,則“底面積”是冗余特征,因為它能從前二者得到。冗余特征在很多時候不起作用,去除它們會減輕學習過程的負擔。但有時冗余特征會降低學習任務的難度,例如若學習目標是估算立方體的體積,則“底面積”這個冗余特征的存在將使得體積的估算更容易;更確切地說,若某個冗余特征恰好對應了完成學習任務所需的“中間概念”,則該冗余特征是有益的。
2 子集搜索與評價
欲從初始的特征集合中選取一個包含了所有重要信息的特征子集,若沒有任何領域知識作為先驗假設,那就只好遍歷所有可能的子集了;然而這在計算上卻是不可行的,因為這樣做會遭遇組合爆炸,特征個數稍多就無法進行。可行的做法是產生一個“候選子集”,評價出它的好壞,基于評價結果產生下一個候選子集,在對其進行評價,…… 這個過程持續進行下去,直至無法找到更好的候選子集為止。顯然,這里涉及兩個關鍵環節:如何根據評價結果獲取下一個候選特征子集?如何評價候選特征子集的好壞?
第一個環節是“子集搜索” (subset search) 問題。給定特征集合{a1,a2,…,ad},我們可將每個特征看作一個候選子集,對這d個候選單特征子集進行評價,假定{a2}最優,于是將{a2}作為第一輪的選定集;然后,在上一輪的選定集中加入一個特征,構成包含兩個特征的候選子集,假定在這d?1個候選兩特征子集中{a2,a4}最優,且優于{a2},于是將{a2,a4}作為本輪的選定集;…… 假定在第k+1輪時,最優的候選(k+1)特征子集不如上一輪的選定集,則停止生成候選子集,并將上一輪選定的k特征集合作為特征選擇結果。這樣逐漸增加相關特征的策略稱為“前向” (forward) 搜索。類似的,若我們從完整的特征集合開始,每次嘗試去掉一個無關特征,這樣逐漸減少特征的策略稱為“后向” (backward) 搜索。還可將前向與后向搜索結合起來,每一輪逐漸增加選定相關特征 (這些特征在后續輪中將確定不會被去除)、同時減少無關特征,這樣的策略稱為“雙向” (bidirectional) 搜索。
顯然,上述策略都是貪心的,因為它們僅考慮了使本輪選定集最優,例如在第三輪假定選擇a5優于a6,于是選定集為{a2,a4,a5},然而在第四輪中卻可能是{a2,a4,a6,a8}比所有的{a2,a4,a5,ai}都更優。遺憾的是,若不進行窮舉搜索,則這樣的問題無法避免。
第二個環節是“子集評價” (subset evaluation) 問題。給定數據集DD,假定D中第i類樣本所占的比例為pi(i=1,2,…,∣Y∣)。為便于討論,假定樣本屬性均為離散型。對于屬性子集A,假定根據其取值將D分成了V個子集{D1,D1,…,DV},每個子集中的樣本在A上取值相同,于是我們可計算屬性子集A的信息增益:
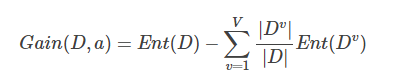
其中信息熵定義為:
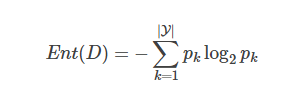
信息增益越大,意味著特征子集A包含的有助于分類的信息越多。于是,對每個候選特征子集,我們可基于訓練數據集D來計算其信息增益,以此作為評價準則。
更一般的,特征子集A實際上確定了對數據集D的一個劃分,每個劃分區域對應著A上的一個取值,而樣本標記信息Y則對應著對D的真是劃分,通過估算這兩個劃分的差異,就能對A進行評價。與Y對應的劃分的差異越小,則說明A越好。信息熵僅是判斷這個差異的一種途徑,其他能判斷兩個劃分差異的機制都能用于特征子集評價。
將特征子集搜索機制與子集評價機制相結合,即可得到特征選擇方法。例如將前向搜索與信息熵結合,這顯然與決策樹算法非常相似。事實上,決策樹可用于特征選擇,樹節點的劃分屬性所組成的集合就是選擇出的特征子集。其他的特征選擇方法未必像決策樹特征選擇這么明顯,但它們在本質上都是顯式或隱式地結合了某種 (或多種) 子集搜索機制和子集評價機制。
常見的特征選擇方法大致可分為三類:過濾式 (filter)、包裹式 (wrapper) 和嵌入式 (embedding)。
3 過濾式選擇
過濾式方法先對數據集進行特征選擇,然后再訓練學習器,特征選擇過程與后續學習器無關。這相當于先用特征選擇過程對初始特征進行“過濾”,再用過濾后的特征來訓練模型。
Relief (Relevant Features) [Kira and Rendell, 1992] 是一種著名的過濾式特征選擇方法,該方法設計了一個“相關統計量”來度量特征的重要性。該統計量是一個 向量,其每個分量分別對應于一個初始特征,而特征子集的重要性則是由子集中每個特征所對應的相關統計量分量之和來決定。于是,最終只需指定一個閾值ττ,然后選擇比ττ大的相關統計量分量所對應的特征即可;也可以指定欲選取的特征個數k,然后選擇相關統計量分量最大的k個特征。
顯然,Relief 的關鍵是如何確定相關統計量。給定訓練集{(x1,y1),(x2,y2),…,(xm,ym)},對每個示例xi,Relief 先在xi的同類樣本中尋找其最鄰近xi,nh,稱為“猜中鄰近” (near-hit),在從xi的異類樣本中尋找其最近鄰xi,nm,稱為“猜錯鄰近” (near-miss),然后,想干統計量對應于屬性j的分量為:
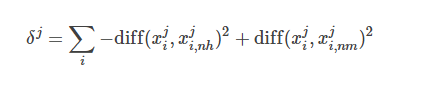

從上式可看出,若樣本與其猜中近鄰在某一屬性上的距離小于該樣本與其猜錯近鄰的距離,則說明這一屬性對區分同類與異類樣本是有益的,于是增大該屬性對應的統計量分量;反之,則說明該屬性起負面作用,于是減小其對應的統計量分量。最后,對基于不同樣本得到的估計結果進行平均,就得到各屬性的相關統計量分量,分量值越大,則對應屬性的分類能力就越強。
4 包裹式選擇
與過濾式特征選擇不考慮后續學習器不同,包裹式特征選擇直接把最終將要使用的學習器的性能作為特征子集的評價準則。換言之,包裹式特征選擇的目的就是為給定學習器選擇最有利于其性能、“量身定做”的特征子集。
一般而言,由于包裹式特征選擇方法直接針對給定學習器進行優化,因此從最終學習器性能來看,包裹式特征選擇比過濾式特征選擇更好,但另一方面,由于在特征選擇過程中需多次訓練學習器,因此包裹式特征選擇的計算開銷通常比過濾式特征選擇大得多。
LVM (Las Vegas Wrapper) [Liu and Setiono, 1996] 是一個典型的包裹式特征選擇方法。它在拉斯維加斯方法 (Las Vegas method) 框架下使用隨機策略來進行子集搜索,并以最終分類器的誤差為特征子集評價準則。該算法是通過在數據集D上,使用交叉驗證法來估計學習器L的誤差,注意這個誤差是在僅考慮特征子集A′時得到的,即特征子集A′中包含的特征數更少,則將A′保留下來。
需注意的是,由于 LVW 算法中特征子集搜索采用了隨機策略,而每次特征子集評價都需要訓練學習器,計算開銷很大,因此算法設置了停止條件控制參數T。然而,整個 LVM 算法是基于拉斯維加斯方法框架,若初始特征數很多(即∣A∣很大) 、T設置較大,則算法可能運行很長時間都達不到停止條件。換言之,若有運行時間限制,則有可能給不出解。
5 嵌入式選擇與L1正則化
在過濾式和包裹式特征選擇方法中,特征選擇過程與學習器訓練過程有明顯的分別;與此不同,嵌入式特征選擇是特征選擇過程與學習器訓練過程融為一體,兩者在同一個優化過程中完成,即在學習器訓練過程中自動地進行了特征選擇。
給定數據集D={(x1,y1),(x2,y2),…,(xm,ym)},其中x∈R,y∈R。考慮最簡單的線性模型回歸模型,以平方誤差為損失函數,則優化目標為:
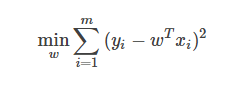
當樣本特征很多,而樣本數相對較少時,上式很容易陷入過擬合。為了緩解過擬合問題,可對上式引入正則化想。若使用L2L2范數正則化,則有:
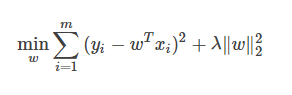
其中正則化參數λ>0。上式也稱為“嶺回歸” (ridge regression) [Tikhonov and Arsenin, 1977],通過引入L2范數正則化,確能顯著降低過擬合的風險。
那么,能否將正則化項中的L2范數替換為Lp范數呢?答案是肯定的。若令p=1,即采用L1范數,則有:
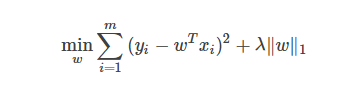
其中正則化參數λ>0。上式稱為 LASSO (Least Absolute Shrinkage and Selection Operator) [Tibshirani, 1996]。
L1范數和L2范數正則化都有助于降低過擬合風險,但L1范數還會帶來一個額外的好處:它比L2范數更易于獲得“稀疏” (sparse) 解,即它求得的w會有更少的非零分量。
注意到w取得稀疏解意味著初始的d個特征中僅有對應著w的非零分量的特征才會出現在最終模型中,于是,求解L1范數正則化的結果是得到了僅采用一部分初始特征的模型;換言之,基于L1正則化的學習方法就是一種嵌入式特征選擇方法,其特征選擇過程與學習器訓練過程融為一體,同時完成。
-
嵌入式
+關注
關注
5092文章
19177瀏覽量
307664 -
機器學習
+關注
關注
66文章
8438瀏覽量
133084 -
特征選擇
+關注
關注
0文章
12瀏覽量
7196
原文標題:機器學習中的特征選擇
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦










 工商網監
工商網監
評論