 AI自學就可用更少步數復原任意3階魔方
AI自學就可用更少步數復原任意3階魔方
魔術方塊是非常有趣的益智玩具,但從難度來說,并不比其他棋類游戲困難,如果人工智能(AI)算法可以在國際象棋或圍棋中輕松打敗人類,那么復原魔術方塊也不是這么困難的事。
但是事實上對于算法來說,要解出魔術方塊的謎題和下棋是完全不同種類的任務。
過去在棋類游戲中展現出超人類表現的算法,都是屬于傳統的「強化學習」(RL)系統,這類型 AI 在確定某些特定的一步是實現整體目標的積極步驟時,便會獲得獎勵,進而使系統產生追求最大利益的習慣性行為,然而當 AI 無法確定這一步是否有益時,強化學習自然就無法發揮作用。
如果還是無法理解,試著這么想吧:在進行棋類游戲時,系統可以輕易去判定一個動作究竟是屬于「好棋」或「壞棋」,但是在轉動魔術方塊時,你能夠說出有任何特定的一步,是改善整體難題的關鍵嗎?
從外觀上來看,魔術方塊是個很單純的益智玩具,然而因為 3D 立體的特性,這讓一般常見的 3 階魔術方塊就已有著驚人的近 4.33×1019 組合,而在其中,只有六面都是相同顏色的狀態才能成為「正確解答」。
過去人們已經研究出許多不同算法和策略來解決這項難題,但 AI 研究人員真正的目標還是希望能像 AlphaGo Zero 那樣,讓 AI 在沒有任何歷史知識的情況下,學會自行應對隨機的魔術方塊難題。
而近期加利福尼亞大學 Stephen McAleer 和團隊透過一種被稱為「自學疊代」(autodidactic iteration)的 AI 技術打造出「DeepCube」系統,成功讓 AI 在面對任何亂序的 3 階魔術方塊時都可以成功找出正確解答。
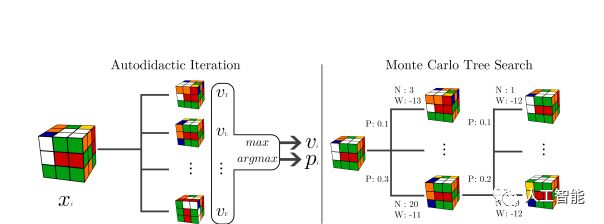
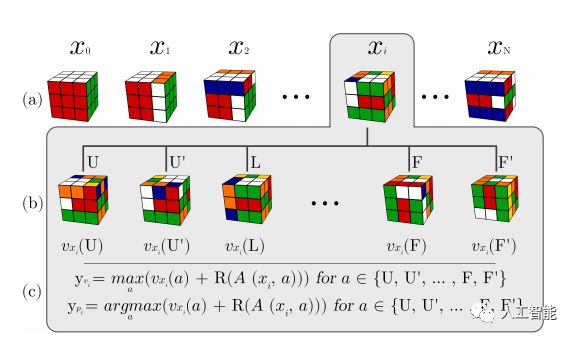
根據團隊解釋,自學疊代是一種全新的強化學習算法,與過去棋類游戲算法的處理方式不同,它采取了「反著看」的內部獎勵判斷機制:當 AI 提出一個動作建議時,算法便會跳至完成的圖形開始往前推導,直到到達提出的動作建議,藉以判斷每一步動作的強度。
雖然聽來相當的繁雜,但這讓系統能夠更熟悉每一步動作,并得以評估出整體強度,一但獲得足夠數量的數據,系統便能以傳統的樹狀搜索方式去找出如何移動最好的方法。
團隊在研究中發現,DeepCube 系統在訓練中自己找出了許多與人類玩家相同的策略,并在經過 44 個小時的自學訓練后,已經能夠在沒有任何人為干預下,在平均 30 步以內復原任何隨機亂序魔術方塊──這些「最佳解答」不是和人類最佳表現一樣好,就是比這些表現更好。
McAleer 和團隊打算未來將在更大、更難解決的 16 階魔術方塊上進行測試,這項全新的系統將有助于 AI 應用更全面化,像是生物物理學上重要的蛋白質摺疊(Protein Folding)問題或也有望得以解決。
-
人工智能
+關注
關注
1796文章
47666瀏覽量
240278 -
強化學習
+關注
關注
4文章
268瀏覽量
11301
原文標題:不需要人類知識,AI 也能以更少步數復原任意 3 階魔方
文章出處:【微信號:worldofai,微信公眾號:worldofai】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
英飛凌展示637ms復原魔方的機器人
魔方復原
[每周一練]labVIEW_3D魔方(1202-1208)
【深聯華杯】魔方復原
C語言的算法設計之魔方陣
這個機器人解開魔方的時間為0.38秒 破世界紀錄
繼圍棋、德撲之后,AI現在又在魔方領域碾壓人類
OpenAI的AI機器人可用單手就能還原魔方
諾丁漢大學用深度學習復原魔方
基于RT-Thread開發電子魔方實現功能
求解瞬態問題時,如何選擇階數和時步?
基于樹莓派RP2040單片機設計的三階魔方還原機器人

基于樹莓派RP2040的解魔方機器人,7秒還原三階魔方






 工商網監
工商網監
評論