 一種針對深度強化學習運動任務的自動環境
一種針對深度強化學習運動任務的自動環境
編者按:通常我們看到的深度強化學習的實現都是在模擬環境中,例如OpenAI的Gym。但這次,迪士尼研究院的科學家們將DL應用到了模塊化機器人上,并創建了一個自動學習環境,可以直接將控制策略應用到實體機器人上。論智將原論文編譯如下。
在這篇論文中,迪士尼研究院的研究者們提出了一種自動學習環境,直接在硬件(模塊化有腿機器人)上建立控制策略。這一環境通過計算獎勵促進了強化學習過程,計算過程是利用基于視覺的追蹤系統和將機器人從新放回原位的重置系統進行的。我們應用了兩種先進的深度學習算法——Trust Region Policy Optimization(TRPO)和Deep Deterministic Policy Gradient(DDPG),這兩種算法可以訓練神經網絡做簡單的前進或者爬行動作。利用搭建好的環境,我們展示了上述兩種算法都能在高度隨機的硬件和環境條件下有效學習簡單的運動策略。之后我們將這種學習遷移到了多腿機器人上。
問題概述
自然界中,很多生物都能根據環境做出適應性動作。在最近一項對盲蜘蛛(也稱長腳蜘蛛)的研究發現,當它們遇到敵人時,會自動伸出腳,過一段時間后又會恢復行走速度和轉向控制。即使不會自動變化,很多生物也會在改變身體結構之后調整動作姿態,這都是長期學習適應的結果。那么我們能否從借鑒生物將這種學習運動的技巧應用到機器人身上呢?
之前有科學家依賴先驗知識手動為機器人設計合適的步態,雖然經驗豐富的工程師能讓機器人隨意移動,但在可以組裝的機器人身上這種方法就不切實際了。
最近,研究者又表示可以用深度強化學習技術提高采樣策略,從而在虛擬環境中完成很多任務,例如游泳、跳躍、行走或跑步。但是對于真實的有腿機器人來說,深度強化學習技術卻很少應用,因為在我們的經驗中,即使一個簡單的爬行動作對真實硬件來說也是很困難的,因為涉及到多變的未經模式化的動作。
在這篇論文中,迪士尼研究院的科學家們提出了一種針對深度強化學習運動任務的自動環境,其中包括一個視覺追蹤器和一個重置機制。在這一環境之上,科學家們在可組裝的有腿機器人上應用了兩種學習算法——TRPO和DDPG。之后訓練神經網絡策略在單腿機器人和多腿機器人上的運動,結果證明算法能在硬件上有效地學習控制策略。
實驗裝置說明
實驗所用機器人如圖所示:
這類似蜘蛛的機器人是可以靈活拆卸的,中間的本體是一個六邊形的形狀,每一面都可以利用磁鐵吸附上一條“機械腿”,不過在實驗中研究人員最多只用了三條腿。除此之外,這三條腿也各不相同,分別可以實現不同的前進方向。
實驗的環境布局如下圖所示:
環境主要由兩部分組成:視覺追蹤系統和讓機器人復位的重置裝置。視覺系統是用消費級攝像頭實現的,距離平面約90cm,它追蹤的是機器人身上的綠色和紅色兩個點,從而重現全局的位置并為機器人導航。
重置裝置是全自動學習環境中的重要組成部分。我們用只有一個自由度的杠桿結構即可將機器人拉回到初始位置。該裝置距離機器人25cm,兩個1.5m長的線分別連接機器人本體上的兩點。
設置完畢后,研究人員將控制問題用部分可觀察馬爾科夫決策過程(POMDP)表示,它可以用無法觀察到的狀態變量來解釋決策問題。具體的數學公式可參考原論文。
學習算法
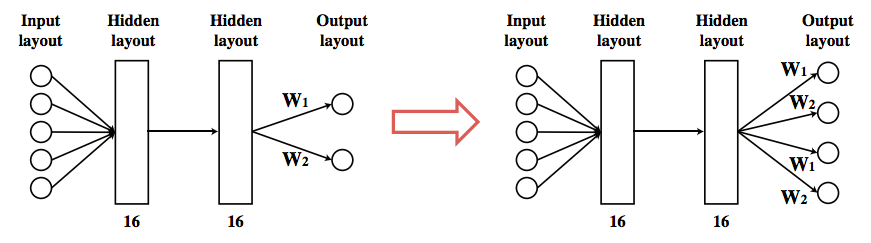
模型的策略用一個神經網絡表示,該網絡由兩個完全連接的隱藏層組成,每層有16個tanh活動神經元。當在單腿機器人上訓練好策略,我們也許能將所學到的知識轉移到多腿機器人上。假設所有的腿都有同樣的接頭形狀,我們可以通過復制輸出神經元和對應的鏈接進行多腿運動。
實驗結果
在實驗中,研究人員主要研究了兩個問題:
目前最先進的深度強化學習算法能否直接在硬件上訓練策略?
我們能否通過遷移策略將學習轉化到復雜場景中?
科學家們首先訓練了一條腿的機器人,最終動作類似于爬行。A、B、C三種腿型的結果如圖:
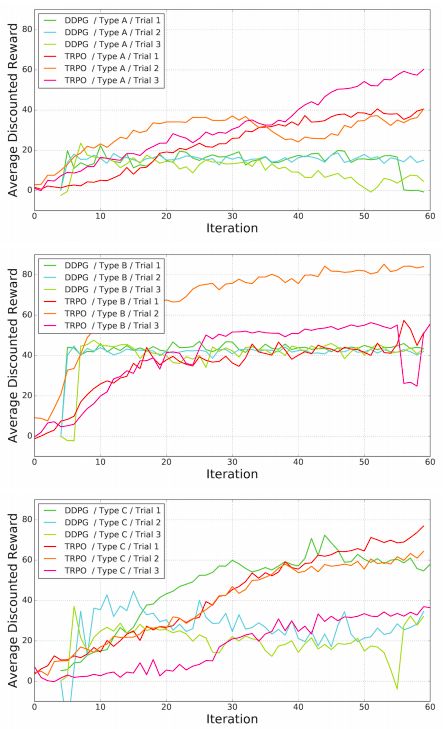
可以看到,TRPO和DDPG兩種算法都能成功地在硬件上進行訓練,同時表現得要比其他手動設計的步態優秀。
接下來科學家測試了學習框架在多腿運動上的表現。首先是用兩個Type B的腿進行爬行動作。下圖是兩種算法在遷移學習和無遷移下的表現:
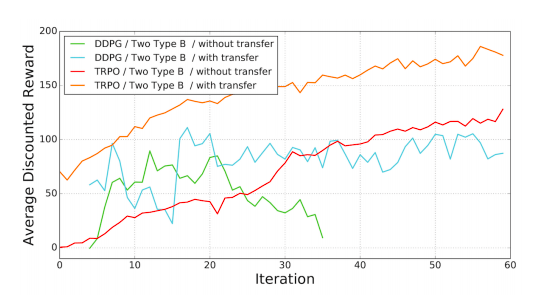
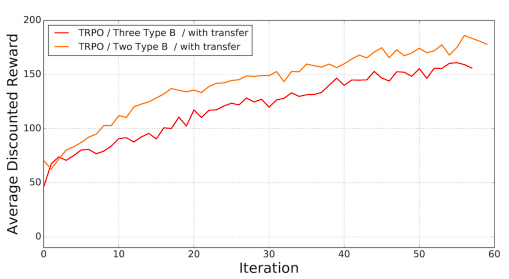
結果符合預期,遷移學習能作為一個很好地初始解決政策。接著研究人員又測試了三條腿前進的表現,結果顯示中間的那條腿作用并不大。
結語
由于傳感器能力有限,研究者在這項實驗中僅對簡單的開環爬行運動進行了實驗。如果有更復雜的控制器和獎勵的話,也許會得到更復雜的行為。例如,可以用基于IMU的反饋控制器訓練機器人走路或跑步。或者可以使用深度相機收集機器人的高度,當它們從爬行轉變成走路時給予獎勵。
除此之外,雖然研究者展示了遷移學習在初始策略上的重要作用,但都是應用在相同種類的腿上,動作也都類似。未來,他們計劃將動作分解成不同難度水平的,應用于不同任務上。
自動學習過程有時會生成意想不到的行為。例如,在做空翻動作時,追蹤系統會出現bug,因為機器人會擋住標記從而對其位置進行誤判。雖然這不會對這次實驗中的機器人造成損壞,但是對于體型龐大的機器人卻是致命的。所以,想在硬件系統上進行直接學習可能也需要傳統算法的幫助,保證機器人的安全,而不是一位追求采樣的高效。
-
機器人
+關注
關注
211文章
28642瀏覽量
208419 -
神經網絡
+關注
關注
42文章
4779瀏覽量
101171 -
深度學習
+關注
關注
73文章
5515瀏覽量
121551
原文標題:迪士尼創建新框架,將深度學習直接應用到實體機器人上
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
什么是深度強化學習?深度強化學習算法應用分析

深度學習DeepLearning實戰
將深度學習和強化學習相結合的深度強化學習DRL
強化學習環境研究,智能體玩游戲為什么厲害
如何使用深度強化學習進行機械臂視覺抓取控制的優化方法概述
一種基于多智能體協同強化學習的多目標追蹤方法
基于深度強化學習仿真集成的壓邊力控制模型
《自動化學報》—多Agent深度強化學習綜述






 工商網監
工商網監
評論