 如何利用兩種機器學習的方法——邏輯回歸和樸素貝葉斯分類器
如何利用兩種機器學習的方法——邏輯回歸和樸素貝葉斯分類器
識別虛假新聞可以說是 Facebook 等社交網絡目前最重視的問題。本文,我們就將介紹如何利用兩種機器學習的方法——邏輯回歸和樸素貝葉斯分類器,來識別存在故意誤導的新聞文章。
自然語言處理( NLP )屬于計算機科學領域,它致力于處理和分析任何形式的自然人類語言(書面,口頭或其他)。 簡而言之,計算機只能理解 0 和 1 ,而人類則使用各種語言進行溝通,NLP 的目的便是在這兩個“世界”間搭建溝通的橋梁,這樣數據科學家和機器學習工程師能分析大量的人類溝通數據。
那 NLP 如何識別虛假新聞呢?實際上,NLP 會把文章分解成一個個小成分并篩選出其中的重要特征,而后我們搭建并訓練模型去識別這其中不靠譜的內容來鑒別虛假新聞。
這次嘗試不僅練習了自然語言處理的技能,也學習了一些有效構建強大分類模型的技術。
▌數據清洗
首先從 Kaggle 庫中選取一個包含兩萬篇標記文章的數據集用于測試效果,結果顯示,模型在預測標簽時的準確度為93%。
在大部分以數據為主體的項目中,第一道工序便是數據清洗。在鑒別虛假新聞時,我們需要處理成千上萬篇來自不同領域、有著不同清晰度的文章。 為了有效篩選需要的內容,我們使用正則表達式來提取分析中所需要的字符串類型。例如,這是一行使用 re python 模塊的代碼:
參閱鏈接:
https://docs.python.org/3/howto/regex.html#
這行代碼會使用空格來替換所有不是字母或數字的字符。 第一個參數,“[^A-Za-z0-9']” ,表示除非符合括號內的指定集,其他內容將全部替換成第二個參數,也就是空格。 一旦我們刪除了那些不需要的字符,我們就可以開始進行標記化和矢量化了!
Scikit-learn 是一個令人驚嘆的 python 機器學習包,它能承擔很多繁重的工作。 特別是 Count Vectorizer 這個函數,它能創建所有被分析文本的完整詞匯表,并將每個單獨的文檔轉換為表示每個單詞總數的向量。 因為大多數文章并不會包含詞匯表里的大部分單詞,函數將返回一個稀疏矩陣形式的向量。 矢量化器則允許我們對各種預處理函數和首選的標記器進行集成。
參閱鏈接:
http://scikit-learn.org/stable/modules/generated/sklearn.feature_extraction.te
xt.CountVectorizer.html
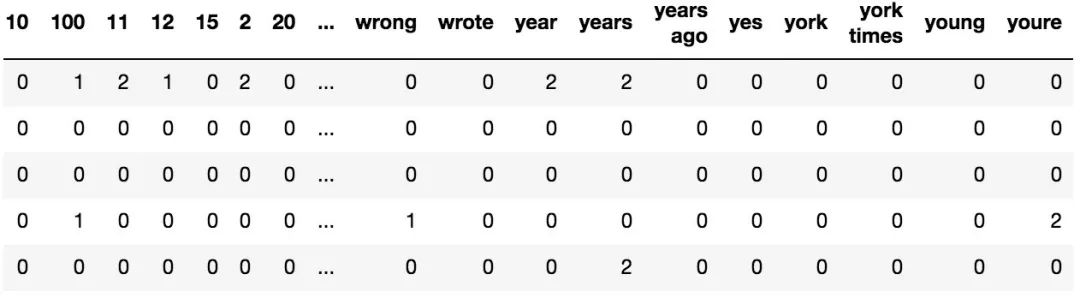
一個被矢量化的文章的示例,每行包含我們初始的1000個特征詞的出現次數
在分析新聞的情況下,僅考慮單個單詞的方法過于簡單,因此我們會允許對雙字符或兩個單詞短語進行向量化。 我們將特征的數量限制為1000,這樣我們在通過特征判斷真假時就只需考慮文檔內最重要的那些特征。
▌特征工程
特征工程是不一個簡單的技能,它更像是復雜的藝術形式。 它包含了考慮數據集和域的過程,選擇對于模型最有用的特征,以及測試特征以優化選擇。 Scikit-learn 的矢量化器提取了我們的1000個基礎的 n 元語法( n-gram ) 特征,同時我們開始添加元特征來改進我們的分類。我們決定計算每個文檔中的平均單詞長度和出現數字的次數,以此提高我們模型的準確性。
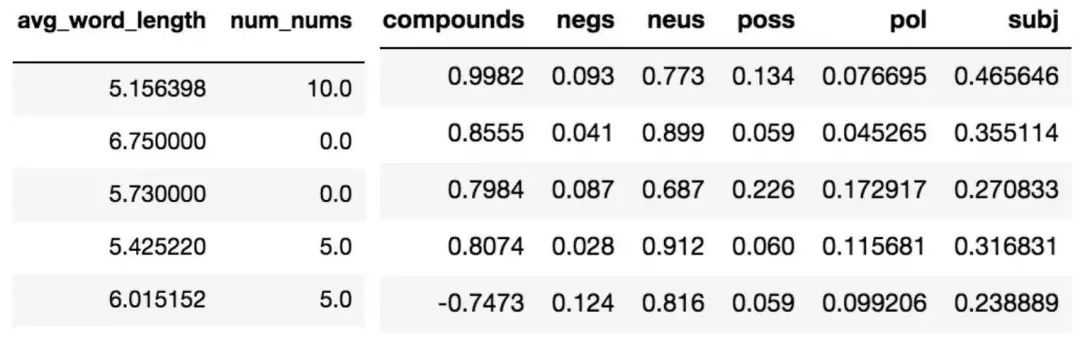
左:各類特征 右:情感得分
情感分析是 NLP 中的另一種分析工具,它可以量化文章中的情緒并評分。我們在這里使用了兩個包,TextBlob 和 Natural Language Toolkit 的 Vader 。它們都是分析文中情緒的工具。 Vader 會針對文章的偏激性和中立性進行測量和評分,而 TextBlob 則會測量文章的偏激性和整體主觀性。我們原本猜想這些情緒分布會根據文章的真實性和誤導性有大幅變化,但在實際情況中我們發現這種差異并不明顯。
通過 Vader 得出的中性文章情緒的分布,0代表的是完全中立
TextBlob 情感得分
(左:-1 代表極性為負,1 代表極性為正;右:0 代表非常客觀,1 代表非常主觀)
從上圖可以看出,通過情感評分的方法不能體現出明顯的差異。 然而,我們認為感情分數和分類器兩者的綜合使用可提高判斷的準確率,因此我們決定將它保留在模型中。
▌邏輯回歸
我們在這里考慮的系統是僅僅包含真和假兩類。 通過給出的相關特征,我們對文章是虛假捏造的概率進行建模。 多項邏輯回歸( LR )是這項工作的理想候選者,我們的模型通過使用對數變換(logit transformation)和最大似然估計(maximum likelihood estimation)來模擬預測變量的相關不可靠性的概率。
換句話說,LR 會直接計算后驗 p(x|y) , 學習如何給輸入的特征分配標簽。 這是一個判別法的例子,雖然在技術層面上這并不是一個統計分類,但它可以對分類資格的條件概率進行賦值。SciKit-Learn 的邏輯回歸模型提供了一種便利的方法來執行此操作。
參閱鏈接:
http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html
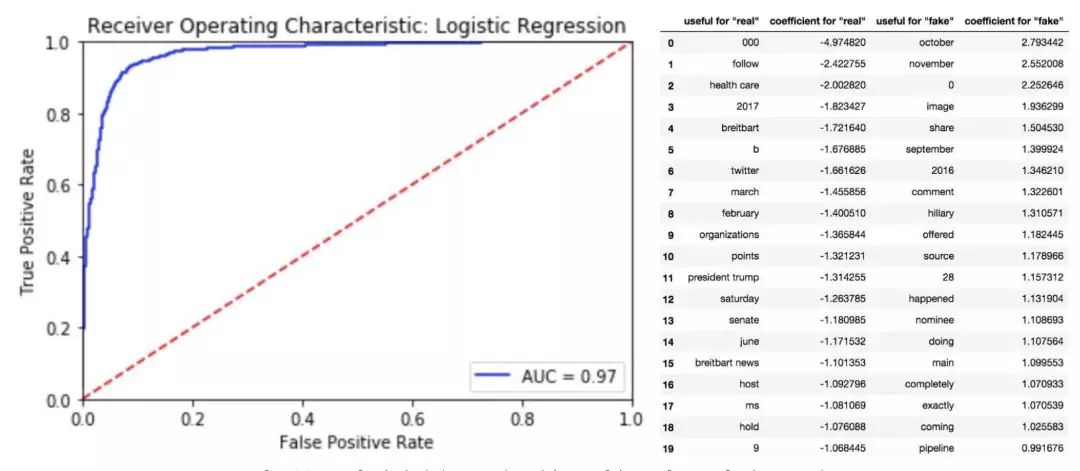
左:邏輯回歸的 ROC 曲線;右:回歸中排名前二十的特征
▌樸素貝葉斯分類器
我們的第二種方法是使用樸素貝葉斯算法( NB )算法,雖然它很簡單,但是它十分適用于這個模型。通過假設特征之間的獨立性,NB 從每個標簽文章中學習聯合概率 p(x,y) 的模型。基于貝葉斯規則計算得到的條件概率,模型會依據最大概率對文章進行標簽分配并預測真偽。與前面提到的方法不同,這是一個生成分類器的例子。
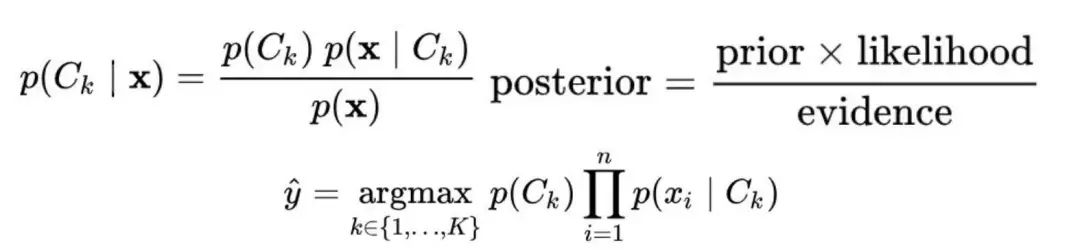
貝葉斯分類器,使用 MAP 決策規則
在這種情況下,我們考慮是一個多項事件模型,它能最準能確地表示我們的特征分布情況。 正如預期的那樣,其結果與邏輯擬合所得出的結論十分接近
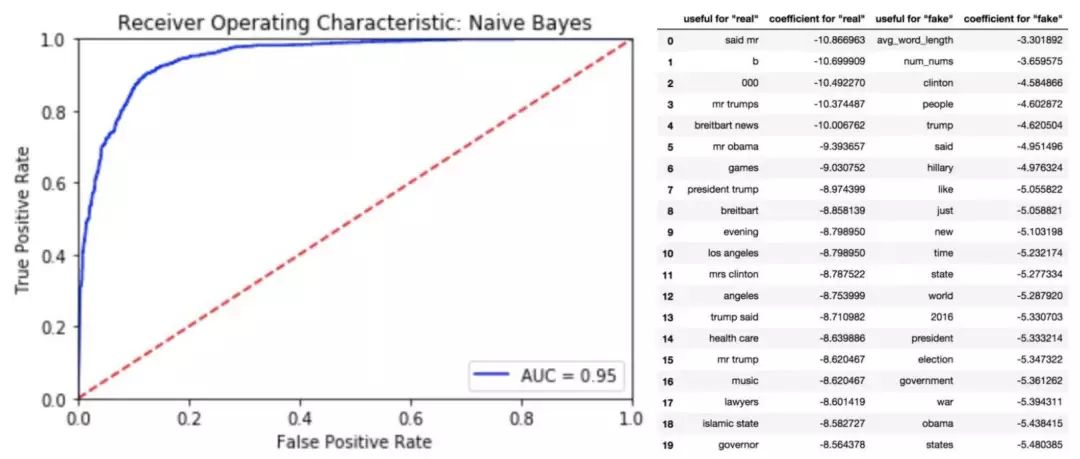
左:多項樸素貝葉斯的 ROC 曲線;右:樸素貝葉斯分類器中排名前20的特征
▌結論
機器學習可以有效地識別以虛假新聞形式存在的錯誤信息。 即便是沒有標題來源等上下文信息,僅正文內容也足以用來進行分析和學習。 因此,這些策略可以很簡單地應用于那些沒有額外描述的文檔。 雖然單獨使用情緒評分法并不能準確地判別假新聞,但當它與其他功能一起使用時,則可以提高分類器的準確性。未來可以嘗試將其與其他流行的模型進行比較,比如支持矢量機。
-
分類器
+關注
關注
0文章
152瀏覽量
13225 -
機器學習
+關注
關注
66文章
8441瀏覽量
133094 -
數據集
+關注
關注
4文章
1209瀏覽量
24836
原文標題:教你用邏輯回歸和樸素貝葉斯算法識別虛假新聞,小技能大用途!
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
非常通俗的樸素貝葉斯算法(Naive Bayes)
如何選擇機器學習的各種方法
回歸算法有哪些,常用回歸算法(3種)詳解
樸素貝葉斯分類器一階擴展的注記
Python機器學習庫和深度學習庫總結
樸素貝葉斯等常見機器學習算法的介紹及其優缺點比較

貝葉斯分類器原理及應用分析
樸素貝葉斯算法的后延概率最大化的認識與理解







 工商網監
工商網監
評論