 Airbnb開發和部署的房源嵌入技術
Airbnb開發和部署的房源嵌入技術
【導讀】本文最早于 2018 年 5 月 13 日發表,主要介紹了機器學習的嵌入技術在 Airbnb 愛彼迎房源搜索排序和實時個性化推薦中的實踐。Airbnb 愛彼迎的兩位機器學習科學家憑借這項技術的實踐獲得了2018 年 KDD ADS track 的最佳論文,本文即是對這篇論文的精華概括。
Airbnb 平臺包含數百萬種不同的房源,用戶可以通過瀏覽搜索結果頁面來尋找想要的房源,我們通過復雜的機器學習模型使用上百種信號對搜索結果中的房源進行排序。 當用戶查看一個房源時,他們有兩種方式繼續搜索:返回搜索結果頁,或者查看房源詳情頁的「相似房源」(會推薦和當前房源相似的房源)。我們 99% 的房源預訂來自于搜索排序和相似房源推薦。
在這篇博文中,我們將會介紹 Airbnb 開發和部署的房源嵌入(Listing Embedding)技術,以及如何用此來改進相似房源推薦和搜索排序中的實時個性化。 這種嵌入是從搜索會話(Session)中學到的 Airbnb 房源的一種矢量表示,并可用此來衡量房源之間的相似性。 房源嵌入能有效地編碼很多房源特征,比如位置、價格、類型、建筑風格和房屋風格等等,并且只需要用 32 個浮點數。我們相信通過嵌入的方法來做個性化和推薦對所有的雙邊市場平臺都非常有效。
嵌入的背景
將詞語表示為高維稀疏向量 (high-dimensional, sparse vectors) 是用于語言建模的經典方法。不過,在許多自然語言處理 (NLP) 應用中,這一方法已經被基于神經網絡的詞嵌入并將詞語用低維度 (low-dimentional) 來表示的新模型取代。新模型假設經常一起出現的詞也具有更多的統計依賴性,會直接考慮詞序及其共現 (co-occurrence) 來訓練網絡。 隨著更容易擴展的單詞表達連續詞袋模型 (bag-of-words) 和 Skip-gram 模型的發展,在經過大文本數據訓練之后,嵌入模型已被證明可以在多種語言處理任務中展現最佳性能。
最近,嵌入的概念已經從詞的表示擴展到 NLP 領域之外的其他應用程序。來自網絡搜索、電子商務和雙邊市場領域的研究人員已經意識到,就像可以通過將句子中的一系列單詞視為上下文來訓練單詞嵌入一樣,我們也可以通過處理用戶的行為序列來訓練嵌入用戶操作,比如學習用戶點擊和購買的商品或瀏覽和點擊的廣告。 這樣的嵌入已經被用于 web 上的各種推薦系統中。
房源嵌入
我們的數據集由 N 個用戶的點擊會話 (Session) 組成,其中每個會話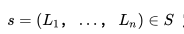 定義為一個由用戶點擊的 n 個房源 id 組成的的不間斷序列;同時,只要用戶連續兩次點擊之間的時間間隔超過30分鐘,我們就會認為是一個新的會話。 基于該數據集,我們的目標是學習一個 32 維的實值表示方式
定義為一個由用戶點擊的 n 個房源 id 組成的的不間斷序列;同時,只要用戶連續兩次點擊之間的時間間隔超過30分鐘,我們就會認為是一個新的會話。 基于該數據集,我們的目標是學習一個 32 維的實值表示方式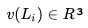 來包含平臺上所有的房源,并使相似房源在嵌入空間中處于臨近的位置。
來包含平臺上所有的房源,并使相似房源在嵌入空間中處于臨近的位置。
列表嵌入的維度被設置為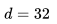 ,這樣的設置可以平衡離線性能(在下一節中討論)和在線搜索服務器內存中存儲向量所需的空間,能夠更好地進行實時相似度的計算。
,這樣的設置可以平衡離線性能(在下一節中討論)和在線搜索服務器內存中存儲向量所需的空間,能夠更好地進行實時相似度的計算。
目前有幾種不同的嵌入訓練方法,在這里,我們將專注于一種稱為負抽樣 (Negative Sampling) 的技術。 首先,它將嵌入初始化為隨機向量,然后通過滑動窗口的方式讀取所有的搜索會話,并通過隨機梯度下降(stochastic gradient descent)來更新它們。 在每一步中,我們都會將中央房源的向量更新并將其推向正向相關房源的向量(用戶在點擊中心房源前后點擊的其他房源,滑動窗口長度為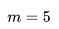 ),并通過隨機抽樣房源的方式將它從負向相關房源推開(因為這些房源很大幾率與中央房源沒有關系)。
),并通過隨機抽樣房源的方式將它從負向相關房源推開(因為這些房源很大幾率與中央房源沒有關系)。
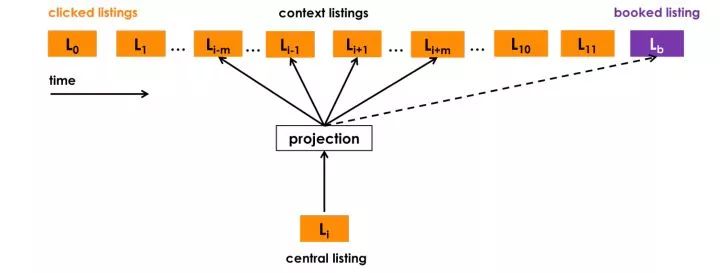
為簡潔起見,我們將跳過具體訓練過程的細節,并著重解釋為了更好地適用我們的場景而做的一些修改:
使用最終預訂的房源作為全局上下文 (Global Context):我們使用以用戶預訂了房源(上圖中紫色標記)為告終的用戶會話來做這個優化,在這個優化的每個步驟中我們不僅預測相鄰的點擊房源,還會預測最終預訂的房源。 當窗口滑動時,一些房源會進入和離開窗口,而預訂的房源始終作為全局上下文(圖中虛線)保留在其中,并用于更新中央房源向量。
適配聚集搜索的情況:在線旅行預訂網站的用戶通常僅在他們的旅行目的地內進行搜索。 因此,對于給定的中心房源,正相關的房源主要包括來自相同目的地的房源,而負相關房源主要包括來自不同目的地的房源,因為它們是從整個房源列表中隨機抽樣的。 我們發現,這種不平衡會導致在一個目的地內相似性不是最優的。 為了解決這個問題,我們添加了一組從中央房源的目的地中抽樣選擇的隨機負例樣本集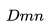
考慮到上述所有因素,最終的優化目標可以表述為
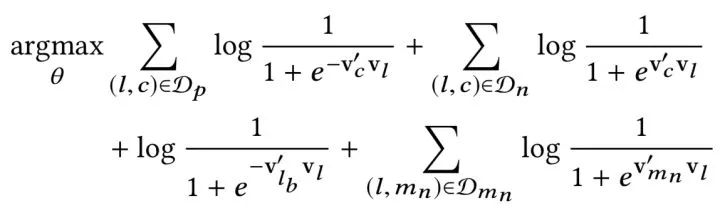
在這里
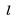
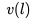
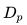
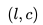
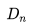
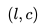
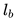
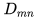
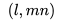
使用上面所描述的優化程序,我們通過使用超過 8 億次的搜索點擊會話,訓練了 Airbnb 上 450 萬個有效列表的房源嵌入,從而獲得了高質量的房源展示。
冷啟動嵌入:每天在 Airbnb 上都有新的房源提供。這些房源在新建時還不在我們的訓練數據集中,所以沒有嵌入信息。 要為新房源創建嵌入,我們會找到 3 個地理位置最接近、房源類別和價格區間相同的已存在的房源,并計算這些房源嵌入的向量平均值來作為新房源的嵌入值。
嵌入學習到的是什么?
我們用多種方式來評估嵌入捕獲到的房源的特征。首先,為了評估地理位置相似性是否被包含,我們對用于學習的嵌入進行了 k 均值聚類 (k-means clustering)。下面的圖顯示了美國加州產生的 100 個聚類,確認了來自近似位置的房源聚集在一起。 接下來,我們評估了不同類型(整套房源,獨立房間,共享房間)和價格范圍的房源之間的平均余弦相似性 (cosine similarity) ,并確認相同類型和價格范圍的房源之間的余弦相似性遠高于不同類型和不同價格的房源之間的相似性。 因此我們可以得出結論,這兩個房源特征也被很好的包括在訓練好的嵌入中了。
雖然有一些房源特征我們可以從房源元數據中提取(例如價格),所以不需要被學習,但是其他類型的房源特征(例如建筑風格,樣式和感覺)很難提取為房源特征的形式。 為了評估這些特性并能夠在嵌入空間中進行快速簡便的探索,我們內部開發了一個相似性探索工具 (Similarity Exploration Tool),并提供了一個視頻進行演示。
視頻鏈接:https://www.youtube.com/watch?v=1kJSAG91TrI&feature=youtu.be
該視頻提供了許多嵌入示例,能夠找到相同獨特建筑風格的相似房源,包括船屋、樹屋、城堡等。
線下評估
在對使用了嵌入的推薦系統進行線上搜索測試之前,我們進行了多次離線測試。同時我們還使用這些測試比較了多種不同參數訓練出來的不同嵌入,以快速做優化,決定嵌入維度、算法修改的不同思路、訓練數據的構造、超參數的選擇等。
評估嵌入的一種方法是測試它們通過用戶最近的點擊來推薦的房源,有多大可能最終會產生預訂。
更具體地說,假設我們獲得了最近點擊的房源和需要排序的房源候選列表,其中包括用戶最終預訂的房源;通過計算點擊房源和候選房源在嵌入空間的余弦相似度,我們可以對候選房源進行排序,并觀察最終被預訂的房源在排序中的位置。
我們在下圖中顯示了一個此類評估的結果,搜索中的房源根據嵌入空間的相似性進行了重新排序,并且最終被預訂房源的排序是按照每次預定前的點擊的平均值來計算,追溯到預定前的 17 次點擊。
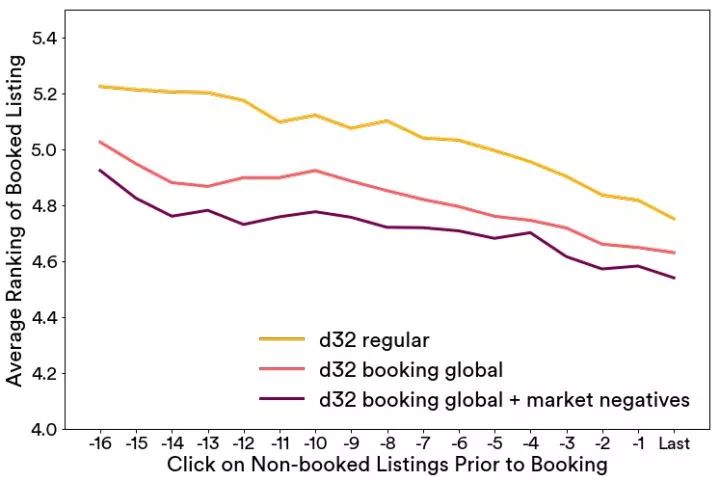
我們比較了幾個嵌入版本:
d32 regular,沒有對原始嵌入算法進行任何修改
d32 booking global,被預訂房源作為全局上下文
d32 booking global + market negatives,被預訂房源作為全局上下文,且加入了中央房源的目的地中抽樣選擇的隨機負例樣本作為負值(見上述目標優化公式)
從圖中我們可以看出,第三個選項中的被預訂房源一直都有較為靠前的排序,所以我們可以得出結論,這個選擇要比其它兩個更優。
基于嵌入的相似房源推薦
每個 Airbnb 房源詳情頁面都包含一個「相似房源」的輪播,推薦與當前房源相似并且可以在相同時間段內預訂的房源。
在我們測試嵌入前,我們主要通過調用主搜索排序模型來搜索相同位置、價格區間和類型的房源以得出相似房源。
在有了嵌入之后,我們對此進行了 A/B 測試,將現有的相似房源算法與基于嵌入的解決方案進行了比較。在基于嵌入的解決方案中,相似房源是通過在房源嵌入空間中找到 k 個最近鄰居 (k-nearest neighbors) 來生成的。 更確切地說,給定學習好了的房源嵌入,通過計算其向量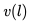 與來自相同目的地的所有房源的向量
與來自相同目的地的所有房源的向量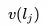 之間的余弦相似性,可以找到指定房源
之間的余弦相似性,可以找到指定房源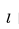 的所有可預訂的相似房源(如果用戶設置了入住和退房日期,房源需要在該時間段內可預訂)。最終得到的
的所有可預訂的相似房源(如果用戶設置了入住和退房日期,房源需要在該時間段內可預訂)。最終得到的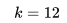 個最高相似性的房源組成了相似房源列表。
個最高相似性的房源組成了相似房源列表。
A/B 測試顯示,基于嵌入的解決方案使「相似房源」點擊率增加了21%,最終通過「相似房源」產生的預訂增加了 4.9%。
基于嵌入的實時個性化搜索
到目前為止,我們已經看到嵌入可以有效地用于計算房源之間的相似性。 我們的下一個想法是在搜索排序中利用此功能進行一個會話內的實時個性化,目的是向用戶更多展示他們喜歡的房源,更少展示他們不喜歡的房源。
為實現這一目標,我們為每個用戶實時收集和維護(基于 Kafka)兩組短期歷史事件:
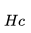 :用戶在過去 2 周內點擊的房源 ID
:用戶在過去 2 周內點擊的房源 ID
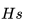 :用戶在過去 2 周內跳過的房源 ID(我們將跳過的房源定義為排序較靠前的房源,但用戶跳過了此房源并點擊了排序較靠后的房源)
:用戶在過去 2 周內跳過的房源 ID(我們將跳過的房源定義為排序較靠前的房源,但用戶跳過了此房源并點擊了排序較靠后的房源)
接下來,在用戶進行搜索時,我們為搜索返回的每個候選房源做 2 個相似性計算:
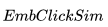
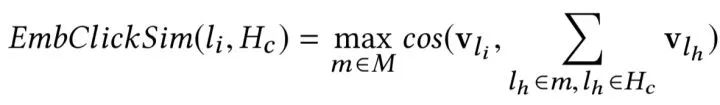
具體來說,我們計算來自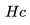 的目的地級質心之間的相似性并選擇最大相似度。 例如,如果
的目的地級質心之間的相似性并選擇最大相似度。 例如,如果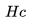 包含來自紐約和洛杉磯的房源,那么這兩個目的地中每個目的地的房源嵌入將被平均以形成目的地級別的質心。
包含來自紐約和洛杉磯的房源,那么這兩個目的地中每個目的地的房源嵌入將被平均以形成目的地級別的質心。
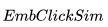
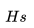
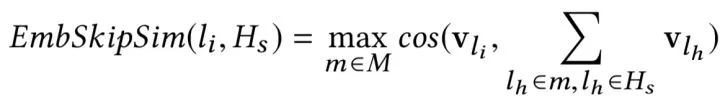
上面這兩個相似性衡量的結果,會作為之后通過搜索排序機器學習模型對候選房源進行排序時考慮的附加信號。
我們首先會記錄這兩個嵌入相似性特征以及其他搜索排序特征,來為模型訓練創建一個新的標記數據集,然后繼續訓練一個新的搜索排序模型,之后我們可以通過 A/B 測試來和當前線上的排序模型進行對比。
為了評估新模型是否如預期地學會了使用嵌入相似性特征,我們在下面繪制了它們的部分依賴圖。這些圖顯示了如果我們固定住其他所有的特征值,只考慮我們正在測試的某個特征值,候選房源的排序分數會發生什么變化。
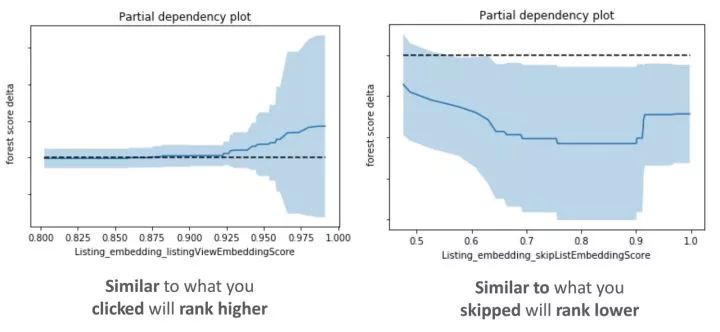
從左邊的圖中可以看出,較大的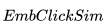 值(用戶最近點擊的房源的相似房源)會導致更高的模型得分。
值(用戶最近點擊的房源的相似房源)會導致更高的模型得分。
在右邊的圖中可以看出,較大的
所以部分依賴圖的觀察結果證實,特征行為符合我們之前預期的模型將學習的內容。除此之外,當新的嵌入特征在搜索排序模型特征中重要性排序很靠前的時候,我們的離線測試結果顯示各項性能指標都有所改進。這些數據讓我們做出了進行在線實驗的決定,之后該實驗取得了成功,我們在 2017 年夏季上線了將嵌入特征用于實時個性化生成推薦的功能。
-
神經網絡
+關注
關注
42文章
4781瀏覽量
101178 -
機器學習
+關注
關注
66文章
8441瀏覽量
133094 -
Airbnb
+關注
關注
0文章
14瀏覽量
5399
原文標題:工程實踐也能拿KDD最佳論文?解讀Embeddings at Airbnb
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
《嵌入式Linux系統開發技術詳解--基于ARM(完整版)》電子版
《嵌入式Linux系統開發技術詳解--基于ARM(完整版)》 電子書免費資源分享
HSDPA和HSUPA在開發/部署這些新技術時存在哪類測試要求?
嵌入式Linux版本Qt5.4快速部署的相關資料分享
如何在RK3308嵌入式開發板上使用ncnn部署mobilenetv2_ssdlite模型呢
嵌入式部署或模式的相關資料分享
Embedded SIG | 多 OS 混合部署框架
部署基于嵌入的機器學習模型
Airbnb機器學習和數據科學團隊經驗分享
嵌入式Linux開發環境部署

嵌入式linux安裝qt,嵌入式Linux版本Qt5.4快速部署
使用嵌入來做個性化的搜索推薦:來自Airbnb





 工商網監
工商網監
評論