 從搜索引擎到人工智能看大數據應用發展史
從搜索引擎到人工智能看大數據應用發展史
我們對大數據技術的使用也經歷了一個發展過程。從最開始的 Google 在搜索引擎中開始使用大數據技術,到現在無處不在的各種人工智能應用,伴隨著大數據技術的發展,大數據應用也從曲高和寡走到了今天的遍地開花。
Google 從最開始發表大數據劃時代論文的時候,也許自己也沒有想到,自己開啟了一個大數據的新時代。今天大數據和人工智能的種種成就,離不開全球數百萬大數據從業者的努力,這其中也包括你和我。歷史也許由天才開啟,但終究還是由人民創造,作為大數據時代的參與者,我們正在創造歷史。
大數據應用的搜索引擎時代
作為全球最大的搜索引擎公司,Google 也是我們公認的大數據鼻祖,它存儲著全世界幾乎所有可訪問的網頁,數目可能超過萬億規模,全部存儲起來大約需要數萬塊磁盤。為了將這些文件存儲起來,Google 開發了 GFS(Google 文件系統),將數千臺服務器上的數萬塊磁盤統一管理起來,然后當作一個文件系統,統一存儲所有這些網頁文件。
你可能會覺得,如果只是簡單地將所有網頁存儲起來,好像也沒什么太了不起的。沒錯,但是 Google 得到這些網頁文件是要構建搜索引擎,需要對所有文件中的單詞進行詞頻統計,然后根據 PageRank 算法計算網頁排名。這中間,Google 需要對這數萬塊磁盤上的文件進行計算處理,這聽上去就很了不起了吧。當然,也正是基于這些需求,Google 又開發了 MapReduce 大數據計算框架。
其實在 Google 之前,世界上最知名的搜索引擎是 Yahoo。但是 Google 憑借自己的大數據技術和 PageRank 算法,使搜索引擎的搜索體驗得到了質的飛躍,人們紛紛棄 Yahoo 而轉投 Google。所以當 Google 發表了自己的 GFS 和 MapReduce 論文后,Yahoo 應該是最早關注這些論文的公司。
Doug Cutting 率先根據 Google 論文做了 Hadoop,于是 Yahoo 就把 Doug Cutting 挖了過去,專職開發 Hadoop。可是 Yahoo 和 Doug Cutting 的蜜月也沒有持續多久,Doug Cutting 不堪 Yahoo 的內部斗爭,跳槽到專職做 Hadoop 商業化的公司 Cloudera,而 Yahoo 則投資了 Cloudera 的競爭對手 HortonWorks。
頂尖的公司和頂尖的高手一樣,做事有一種優雅的美感。你可以看 Google 一路走來,從搜索引擎、Gmail、地圖、Android、無人駕駛,每一步都將人類的技術邊界推向更高的高度。而差一點的公司即使也曾經獲得過顯赫的地位,但是一旦失去做事的美感和節奏感,在這個快速變革的時代,隕落得比流星還快。
大數據應用的數據倉庫時代
Google 的論文剛發表的時候,吸引的是 Yahoo 這樣的搜索引擎公司和 Doug Cutting 這樣的開源搜索引擎開發者,其他公司還只是吃瓜群眾。但是當 Facebook 推出 Hive 的時候,嗅覺敏感的科技公司都不淡定了,他們開始意識到,大數據的時代真正開啟了。
曾經我們在進行數據分析與統計時,僅僅局限于數據庫,在數據庫的計算環境中對數據庫中的數據表進行統計分析。并且受數據量和計算能力的限制,我們只能對最重要的數據進行統計和分析。這里所謂最重要的數據,通常指的都是給老板看的數據和財務相關的數據。
而 Hive 可以在 Hadoop 上進行 SQL 操作,實現數據統計與分析。也就是說,我們可以用更低廉的價格獲得比以往多得多的數據存儲與計算能力。我們可以把運行日志、應用采集數據、數據庫數據放到一起進行計算分析,獲得以前無法得到的數據結果,企業的數據倉庫也隨之呈指數級膨脹。
不僅是老板,公司中每個普通員工比如產品經理、運營人員、工程師,只要有數據訪問權限,都可以提出分析需求,從大數據倉庫中獲得自己想要了解的數據分析結果。
你看,在數據倉庫時代,只要有數據,幾乎就一定要進行統計分析,如果數據規模比較大,我們就會想到要用 Hadoop 大數據技術,這也是 Hadoop 在這個時期發展特別快的一個原因。技術的發展同時又促進了技術應用,這也為接下來大數據應用走進數據挖掘時代埋下伏筆。
大數據應用的數據挖掘時代
大數據一旦進入更多的企業,我們就會對大數據提出更多期望,除了數據統計,我們還希望發掘出更多數據的價值,大數據隨之進入數據挖掘時代。
講個真實的案例,很早以前商家就通過數據發現,買尿不濕的人通常也會買啤酒,于是精明的商家就把這兩樣商品放在一起,以促進銷售。啤酒和尿不濕的關系,你可以有各種解讀,但是如果不是通過數據挖掘,可能打破腦袋也想不出它們之間會有關系。在商業環境中,如何解讀這種關系并不重要,重要的是它們之間只要存在關聯,就可以進行關聯分析,最終目的是讓用戶盡可能看到想購買的商品。
除了商品和商品有關系,還可以利用人和人之間的關系推薦商品。如果兩個人購買的商品有很多都是類似甚至相同的,不管這兩個人天南海北相隔多遠,他們一定有某種關系,比如可能有差不多的教育背景、經濟收入、興趣愛好。根據這種關系,可以進行關聯推薦,讓他們看到自己感興趣的商品。
更進一步,大數據還可以將每個人身上的不同特性挖掘出來,打上各種各樣的標簽:90 后、生活在一線城市、月收入 1~2 萬、宅……這些標簽組成了用戶畫像,并且只要這樣的標簽足夠多,就可以完整描繪出一個人,甚至比你最親近的人對你的描述還要完整、準確。
除了商品銷售,數據挖掘還可以用于人際關系挖掘。你聽過“六度分隔理論”嗎,它認為世界上兩個互不認識的人,只需要很少的中間人就能把他們聯系起來。這個理論在美國的實驗結果是,通過六步就能聯系上兩個不認識的美國人。也是基于這個理論,Facebook 研究了十幾億用戶的數據,試圖找到關聯兩個陌生人之間的數字,答案是驚人的 3.57。你可以看到,各種各樣的社交軟件記錄著我們的好友關系,通過關系圖譜挖掘,幾乎可以把世界上所有的人際關系網都描繪出來。
現代生活幾乎離不開互聯網,各種各樣的應用無時不刻不在收集數據,這些數據在后臺的大數據集群中一刻不停地在被進行各種分析與挖掘。這些分析和挖掘帶給我們的是美好還是恐懼,依賴大數據從業人員的努力。但是可以肯定,不管最后結果如何,這個進程只會加速不會停止,你我只能投入其中。
大數據應用的機器學習時代
我們很早就發現,數據中蘊藏著規律,這個規律是所有數據都遵循的,過去發生的事情遵循這個規律,將來要發生的事情也遵循這個規律。一旦找到了這個規律,對于正在發生的事情,就可以按照這個規律進行預測。
在過去,我們受數據采集、存儲、計算能力的限制,只能通過抽樣的方式獲取小部分數據,無法得到完整的、全局的、細節的規律。而現在有了大數據,可以把全部的歷史數據都收集起來,統計其規律,進而預測正在發生的事情。
這就是機器學習。
把歷史上人類圍棋對弈的棋譜數據都存儲起來,針對每一種盤面記錄何種落子可以得到更高的贏面。得到這個統計規律以后,就可以利用這個規律和人下棋,每一步都計算落在何處將得到更大的贏面,于是我們就得到了一個會下棋的機器人,這就是前兩年轟動一時的 AlphaGo,以壓倒性優勢下贏了人類的頂尖棋手。
再舉個和我們生活更近的例子。把人聊天的對話數據都收集起來,記錄每一次對話的上下文,如果上一句是是問今天過得怎么樣,那么下一句該如何應對,通過機器學習可以統計出來。將來有人再問今天過得怎么樣,就可以自動回復下一句話,于是我們就得到一個會聊天的機器人。Siri、天貓精靈、小愛同學,這樣的語音聊天機器人在機器學習時代已經滿大街都是了。
將人類活動產生的數據,通過機器學習得到統計規律,進而可以模擬人的行為,使機器表現出人類特有的智能,這就是人工智能 AI。
現在我們對待人工智能還有些不理智的態度,有的人認為人工智能會越來越強大,將來會統治人類。實際上,稍微了解一點人工智能的原理就會發現,這只是大數據計算出來的統計規律而已,表現的再智能,也不可能理解這樣做的意義,而有意義才是人類智能的源泉。按目前人工智能的發展思路,永遠不可能出現超越人類的智能,更不可能統治人類。
寫在最后
大數據從搜索引擎到機器學習,發展思路其實是一脈相承的,就是想發現數據中的規律并為我們所用。所以很多人把數據稱作金礦,大數據應用就是從這座蘊含知識寶藏的金礦中發掘中有商業價值的真金白銀出來。
數據中蘊藏著價值已經是眾所周知的事情了,那么如何從這些龐大的數據中發掘出我們想要的知識價值,這正是大數據技術目前正在解決的事情,包括大數據存儲與計算,也包括大數據分析、挖掘、機器學習等應用。
美國的西部淘金運動帶來了美國的大拓荒時代,來自全世界各地的人涌向美國西部,將人口、資源、生產力帶到了荒蠻的西部地帶,一條條鐵路也將美國的東西海岸連接起來,整個美國也隨之繁榮起來。大數據這座更加龐大的金礦目前也正發揮著同樣的作用,全世界無數的政府、企業、個人正在關注著這座金礦,無數的資源正在向這里涌來。
我們不曾生活在美國西部淘金的繁榮時代,錯過了那個光榮與夢想、自由與激情的個人英雄主義時代。但是現在,一個更具劃時代意義的大數據淘金時代正在到來,而你我正身處其中。
-
人工智能
+關注
關注
1796文章
47666瀏覽量
240281 -
搜索引擎
+關注
關注
0文章
119瀏覽量
13385
原文標題:大數據應用發展史:從搜索引擎到人工智能
文章出處:【微信號:jingzhenglizixun,微信公眾號:機器人博覽】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
阿里國際推出全球首個B2B AI搜索引擎Accio
阿里國際推出B2B領域AI搜索引擎Accio
Meta開發新搜索引擎,減少對谷歌和必應的依賴
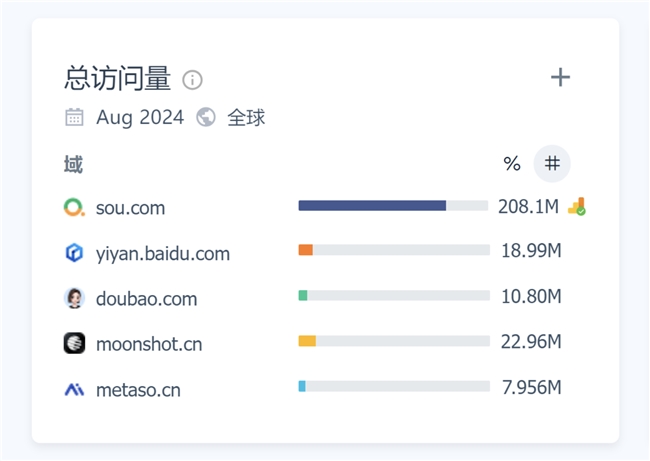
月訪問量超2億,增速113%!360AI搜索成為全球增速最快的AI搜索引擎
OpenAI推出SearchGPT原型,正式向Google搜索引擎發起挑戰
微軟計劃在搜索引擎Bing中引入AI摘要功能
AI搜索挑戰百度谷歌,重塑信息檢索的市場?
OpenAI下周或推人工智能搜索挑戰谷歌
OpenAI注冊新域名,準備推出結合AI技術的搜索引擎挑戰谷歌
OpenAI或將推出ChatGPT搜索引擎
OpenAI或將在5月9日發布ChatGPT版搜索引擎
潤和軟件與新財富聯合發布金融AI對話式搜索引擎“金融搜一搜”產品






 工商網監
工商網監
評論