 windows下虛擬機配置spark集群最強攻略!
windows下虛擬機配置spark集群最強攻略!
首先需要在windows上安裝vmware和ubuntu虛擬機,這里就不多說了。
vmware下載地址:直接百度搜索,使用百度提供的鏈接下載,這里附上一個破解碼
5A02H-AU243-TZJ49-GTC7K-3C61N
ubuntu下載地址:http://cdimage.ubuntu.com/daily-live/current/
一路安裝下去,我一共裝了4臺虛擬機,三臺用于構建集群,一臺用于爬蟲,如圖所示:
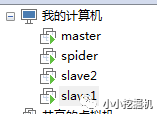
這里,我們以slave2為例來說明一下虛擬機的網絡配置:
首先,將虛擬機的網絡設置設置為自定義,選擇VMnet8:
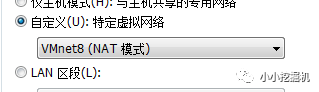
隨后,我們點擊VMWARE上的編輯-虛擬網絡編輯-右下角的更改設置,應該有三個連接方式,這里我們把其他兩個移除,只剩下VMnet8:

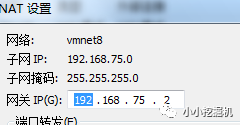
隨后,點擊NAT設置,我們可以發現網關是192.168.75.2
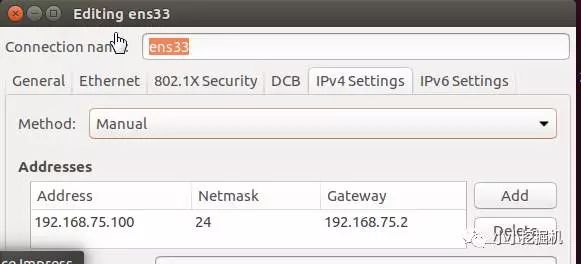
接下來,我們要設置虛擬機的ip:點擊右上角的edit connectinos,設置Ipv4,如下圖所示:
隨后修改兩個文件:
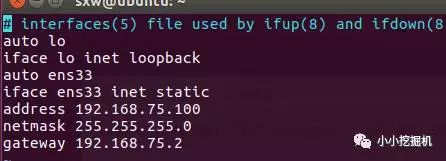
修改interfaces文件
命令:sudo vim /etc/network/interfaces ( 如果沒有vim命令,使用sudo apt-get install vim進行安裝):
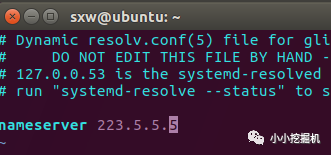
修改resolv.conf文件
命令:sudo vim /etc/resolv.conf:
接下來重啟我們的網絡就可以啦:
命令:sudo /etc/init.d/networking restart(如果啟動失敗,重啟虛擬機即可)

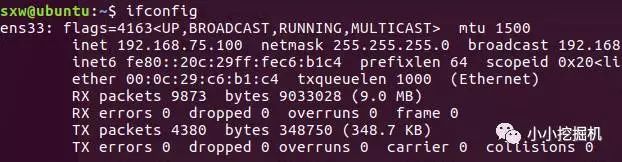
查看我們的ip,使用ifconfig命令,如果沒有安裝(使用sudo apt install net-tools 進行安裝):
下載xshell,百度搜索xshell,使用百度提供的下載地址即可。
要想使用xshell的ssh方式訪問虛擬機,首先要在虛擬機上安裝ssh服務
使用命令:sudo apt-get install openssh-server
隨后啟動ssh服務:sudo /etc/init.d ssh start
再次點擊VMWARE上的編輯-虛擬網絡編輯-右下角的更改設置,設置端口轉發:
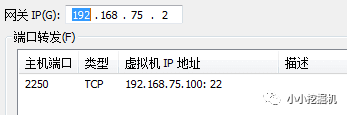
隨后打開xshell,新建連接:
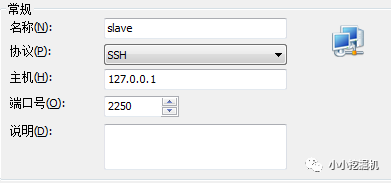
設置用戶名和密碼:
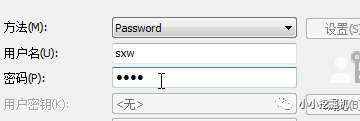
隨后點擊連接即可,發現連接成功!
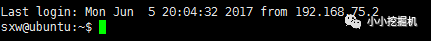
這里以修改主節點主機名稱為例,其他節點類似。
使用命令 : sudo vim /etc/hostname 查看當前主機名,并修改為master:
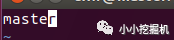
重啟之后生效:

兩個從節點的主機依次修改為slave1,slave2
接下來,將主節點和兩個從節點的ip和主機名添加到hosts文件中,使用命令
sudo vim /etc/hosts
修改的結果為:
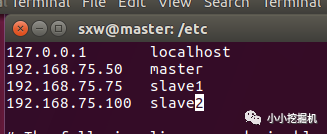
兩個從節點的hosts文件修改為同樣的結果,此時發現各虛擬機之間可以ping通。

接下來,需要讓主節點可以免驗證的登錄到從節點,從而在進行任務調度時可以暢通無阻。
首先要在各個節點上生成公鑰和私鑰文件,這里以slave1節點進行講解,其他節點操作方式完全相同。
我們首先要開啟ssh服務,使用命令:sudo /etc/init.d/ssh start

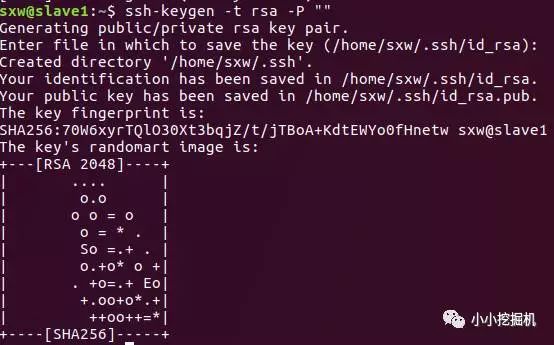
隨后使用如下命令生成公鑰和私鑰文件:
ssh-keygen -t rsa -P ""
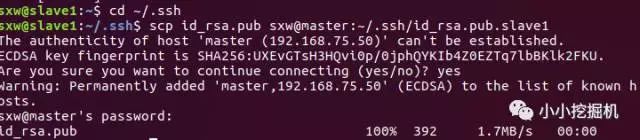
在所有節點上生成秘鑰文件之后,我們需要將從節點的公鑰傳輸給主節點,使用命令:
cd ~/.ssh
scp id_rsa.pub sxw@master:~/.ssh/id_rsa.pub.slave1
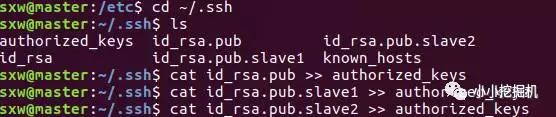
隨后,在主節點下,將所有的公鑰信息拷貝到authorized_keys文件下:使用命令:
cd ~/.ssh
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub.slave1 >> authorized_keys
cat id_rsa.pub.slave2 >> authorized_keys
接下來將authorized_keys文件復制到slave1和slave2節點目錄下:
scp authorized_keys sxw@slave1:~/.ssh/authorized_keys
scp authorized_keys sxw@slave2:~/.ssh/authorized_keys

接下來我們驗證是否可以免密碼登錄:使用命令
ssh slave1
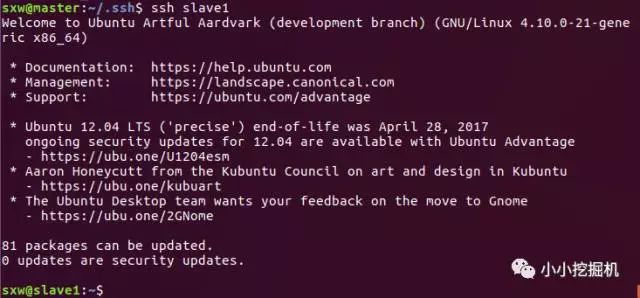
登陸成功,我們可以使用exit命令退出登錄
這里我們可以直接使用linux的命令下載jdk,當然也可以在本地下載之后傳輸到虛擬機中,這里我采用的是后者,因為我感覺在主機上下載會比較快一些。到java官網中下載最新的jdk文件即可。
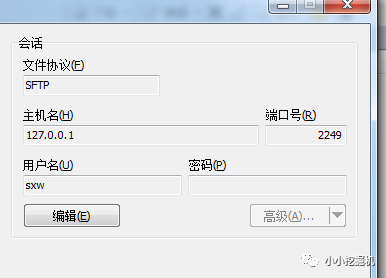
使用由于剛才我們配置了端口轉發,因此我們可以使用winscp進行文件傳輸:
傳輸文件到/home/sxw/Documents路徑下,直接將文件進行拖拽即可:
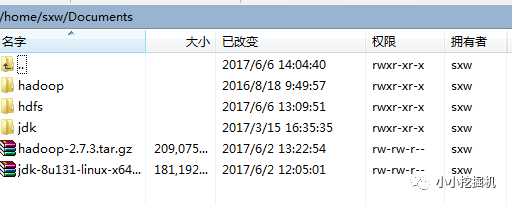
隨后,在該路徑下,使用如下命令進行解壓:
tar -zxvf 文件名

重命名jdk文件夾為jdk

隨后修改配置文件:
sudo vim /etc/profile
添加如下三行:export JAVA_HOME=/home/sxw/Documents/jdk
exportCLASSPATH=.:$JAVA_HOME/lib:$JAVA_HOME/jre/lib:$CLASSPATH
exportPATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$PATH
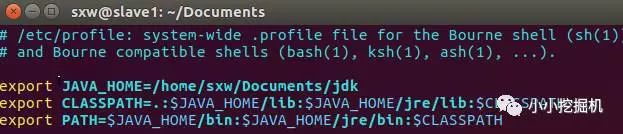
使用source命令使修改生效,同時查看是否安裝成功

可以使用命令下載scala,不過我們仍然選擇在本地下載scala:下載地址:http://www.scala-lang.org/download/2.11.7.html
通過winscp傳入各虛擬機里,并使用如下命令進行解壓:
tar -zxvf 文件名

重命名文件:

修改配置文件,增加以下兩行,并用source命令使修改生效:

檢查是否安裝成功:

可以看到scala已經安裝成功了!
我們首先在主節點上配置好hadoop的文件,隨后使用scp命令傳輸到從節點上即可。
同樣,我們在hadoop官網下載hadoop文件,通過winscp傳入主節點,使用tar命令進行解壓,并修改文件夾名為hadoop,這些這里暫且略過。
修改環境變量(所有節點都需要修改)并使用source命令使其生效:

接下來修改hadoop的配置文件:
(1)$HADOOP_HOME/etc/hadoop/hadoop-env.sh
修改JAVA_HOME 如下:
export JAVA_HOME=/home/sxw/Documents/jdk
(2)$HADOOP_HOME/etc/hadoop/slaves
修改salves里添加兩個從節點的名稱
slave1
slave2
(3)$HADOOP_HOME/etc/hadoop/core-site.xml
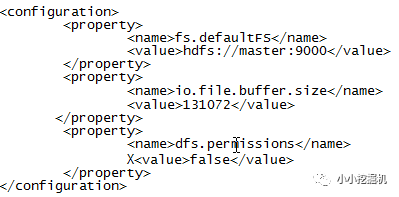
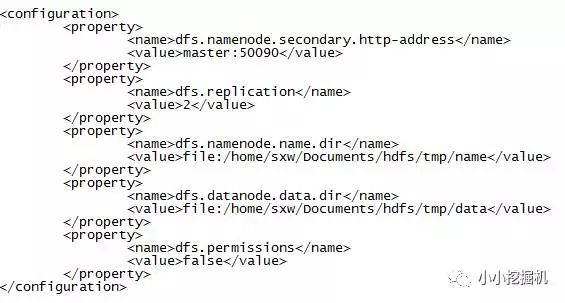
(4)$HADOOP_HOME/etc/hadoop/hdfs-site.xml
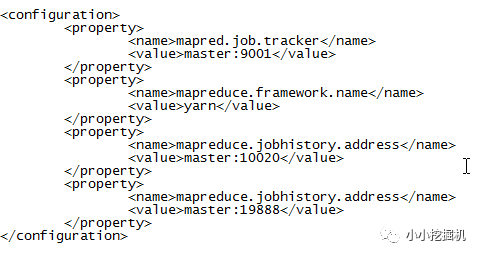
(5)$HADOOP_HOME/etc/hadoop/mapred-site.xml
首先使用如下命令生成mapred-site.xml文件:cp mapred-site.xml.template mapred-site.xml
隨后進行修改:
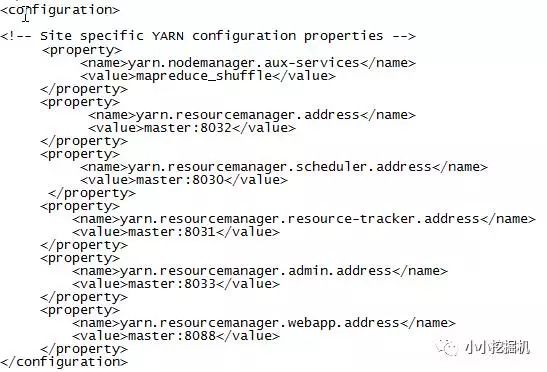
(6)$HADOOP_HOME/etc/hadoop/yarn-site.xml
至此,hadoop的配置文件就修改完了,我們用scp命令將修改好的hadoop文件傳入到子節點即可
我們首先在主節點上配置好spark的文件,隨后使用scp命令傳輸到從節點上即可。
同樣在spark官網下載最新的spark文件,并使用winscp傳入虛擬機,使用tar命令進行解壓,并重命名文件夾為spark。
添加spark到環境變量并使其生效:

接下來修改spark的配置文件:
(1)$SPARK_HOME/conf/spark-env.sh
首先使用如下命令生成spark-env.sh文件:
cpspark-env.sh.template spark-env.sh
隨后進行修改:

(2)$SPARK_HOME/conf/slaves
首先使用如下命令生成slaves文件:
cpslaves.template slaves
隨后進行修改:
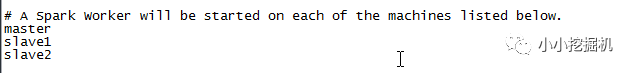
至此,spark的配置文件就修改完了,我們用scp命令將修改好的spark文件傳入到子節點即可,不要忘記修改子節點的環境變量
首先我們編寫一個啟動腳本:
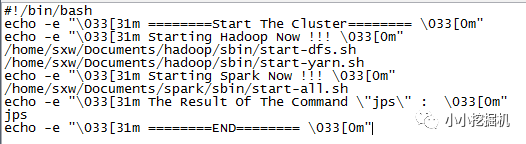
可以看到,hadoop的啟動需要兩個命令,分別啟動dfs和yarn,傳統的start-all.sh已經被棄用。而spark的啟動只需要一個命令。
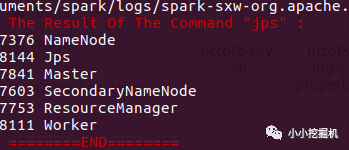
啟動的結果如下圖所示:
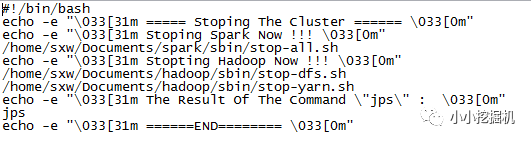
隨后我們再編寫一個關閉集群的腳本:
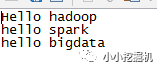
我們在/home/sxw/Documents下建立一個wordcount.txt文件
文件內容如下圖:
到hadoop的bin路徑下執行如下三條命令:
hadoopfs-mkdir-p/Hadoop/Inputhadoopfs-putwordcount.txt/Hadoop/Inputhadoopjar/home/sxw/Documents/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jarwordcount/Hadoop/Input/Hadoop/Output
可以看到我們的hadoop再進行運算了:

使用如下命令查看運算結果,發現我們的期望的結果正確輸出:
hadoop fs -cat/Hadoop/Output/*

hadoop配置成功!
我們直接利用spark-shell 進行測試,編寫幾條簡單額scala語句:
到spark的bin路徑下執行./spark-shell命令進入scala的交互模式,并輸入如下幾條scala語句:
valfile=sc.textFile("hdfs://master:9000/Hadoop/Input/wordcount.txt")valrdd=file.flatMap(line=>line.split("")).map(word=>(word,1)).reduceByKey(_+_)rdd.collect()rdd.foreach(println)
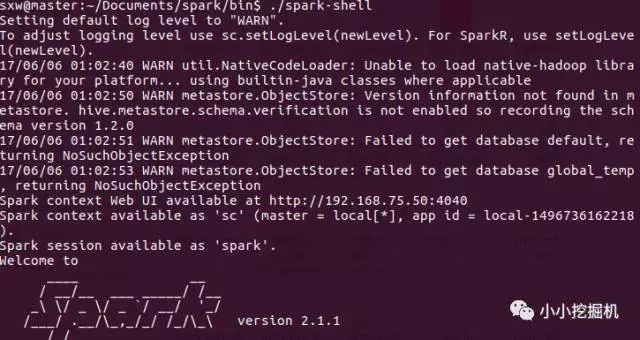
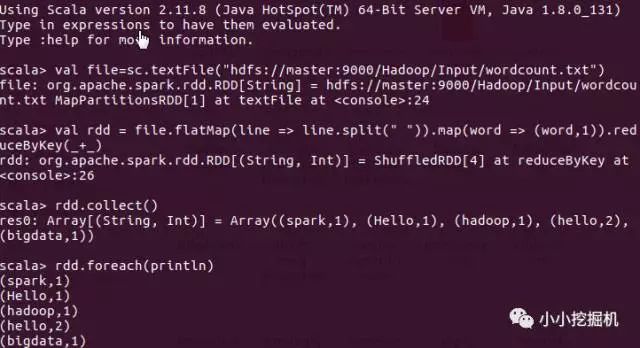
可以看到,我們的spark集群成功搭建!
-
Linux
+關注
關注
87文章
11345瀏覽量
210385 -
虛擬機
+關注
關注
1文章
937瀏覽量
28426
原文標題:windows下虛擬機配置spark集群最強攻略!
文章出處:【微信號:atleadai,微信公眾號:LeadAI OpenLab】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
Anaconda之tensorflow:深度學習之Anaconda下安裝tensorflow正確運行之史上最強攻略
MYZR虛擬機功能演示
電子書:電源設計最強攻略, 帶你全面掌握設計竅門
虛擬機Ubuntu18 64位系統虛擬機的配置方法
在虛擬機中安裝Windows XP鏡像
求一種基于集群的技術和基于虛擬機重啟的技術
云環境下虛擬機集群系統動態負載均衡機制


如何使用windows10遠程連接虛擬機桌面
Hyper-V創建虛擬機配置IP等網絡配置原理(Linux、Windows為例)





 工商網監
工商網監
評論