 FPGA的深度學習加速器有怎樣的挑戰和機遇
FPGA的深度學習加速器有怎樣的挑戰和機遇
FPGA 的神經網絡加速器如今越來越受到 AI 社區的關注,本文對基于 FPGA 的深度學習加速器存在的機遇與挑戰進行了概述。
近年來,神經網絡在各種領域相比于傳統算法有了極大的進步。在圖像、視頻、語音處理領域,各種各樣的網絡模型被提出,例如卷積神經網絡、循環神經網絡。訓練較好的 CNN 模型把 ImageNet 數據集上 5 類頂尖圖像的分類準確率從 73.8% 提升到了 84.7%,也靠其卓越的特征提取能力進一步提高了目標檢測準確率。RNN 在語音識別領域取得了最新的詞錯率記錄。總而言之,由于高度適應大量模式識別問題,神經網絡已經成為許多人工智能應用的有力備選項。
然而,神經網絡模型仍舊存在計算量大、存儲復雜問題。同時,神經網絡的研究目前還主要聚焦在網絡模型規模的提升上。例如,做 224x224 圖像分類的最新 CNN 模型需要 390 億浮點運算(FLOP)以及超過 500MB 的模型參數。由于計算復雜度直接與輸入圖像的大小成正比,處理高分辨率圖像所需的計算量可能超過 1000 億。
因此,為神經網絡應用選擇適度的計算平臺特別重要。一般來說,CPU 每秒能夠完成 10-100 的 GFLOP 運算,但能效通常低于 1 GOP/J,因此難以滿足云應用的高性能需求以及移動 app 的低能耗需求。相比之下,GPU 提供的巔峰性能可達到 10TOP/S,因此它是高性能神經網絡應用的絕佳選擇。此外,Caffe 和 TensorFlow 這樣的編程框架也能在 GPU 平臺上提供易用的接口,這使得 GPU 成為神經網絡加速的首選。
除了 CPU 和 GPU,FPGA 逐漸成為高能效神經網絡處理的備選平臺。根據神經網絡的計算過程,結合為具體模型設計的硬件,FPGA 可以實現高度并行并簡化邏輯。一些研究顯示,神經網絡模型能以硬件友好的方式進行簡化,不影響模型的準確率。因此,FPGA 能夠取得比 CPU 和 GPU 更高的能效。
回顧 20 世紀 90 年代,那時 FPGA 剛出現,但不是為了神經網絡,而是為了電子硬件原型的快速開發而設計的。由于神經網絡的出現,人們開始探索、改進其應用,但無法確定其發展方向。盡管在 1994 年,DS Reay 首次使用 FPGA 實現神經網絡加速,但由于神經網絡自身發展不夠成熟,這一技術并未受到重視。直到 2012 年 ILSVRC 挑戰賽 AlexNet 的出現,神經網絡的發展漸為明晰,研究社區才開始往更深、更復雜的網絡研究發展。后續,出現了 VGGNet、GoogleNet、ResNet 這樣的模型,神經網絡越來越復雜的趨勢更為明確。當時,研究者開始注意到基于 FPGA 的神經網絡加速器,如下圖 1 所示。直到去年,IEEE eXplore 上發表的基于 FPGA 的神經網絡加速器數量已經達到了 69 個,且還在一直增加。這足以說明該方向的研究趨勢。
圖 1:基于 FPGA 的神經網絡加速器開發歷史
論文:A Survey of FPGA Based Deep Learning Accelerators: Challenges and Opportunities
論文地址:https://arxiv.org/abs/1901.04988
摘要:隨著深度學習的快速發展,神經網絡和深度學習算法已經廣泛應用于各個領域,如圖片、視頻和語音處理等。但是,神經網絡模型也變得越來越大,這體現在模型參數的計算上。雖然為了提高計算性能,研究者在 GPU 平臺上已經做了大量努力,但專用硬件解決方案仍是必不可少的,而且與純軟件解決方案相比正在形成優勢。在這篇論文中,作者系統地探究了基于 FPGA 的神經網絡加速器。具體來講,他們分別回顧了針對特定問題、特定算法、算法特征、通用模板的加速器,還比較了不同設備和網絡模型中基于 FPGA 加速器的設計和實現,并將其與 CPU 和 GPU 的版本進行了比較。最后,作者討論了 FPGA 平臺上加速器的優勢和劣勢,并進一步探索了未來研究存在的機會。
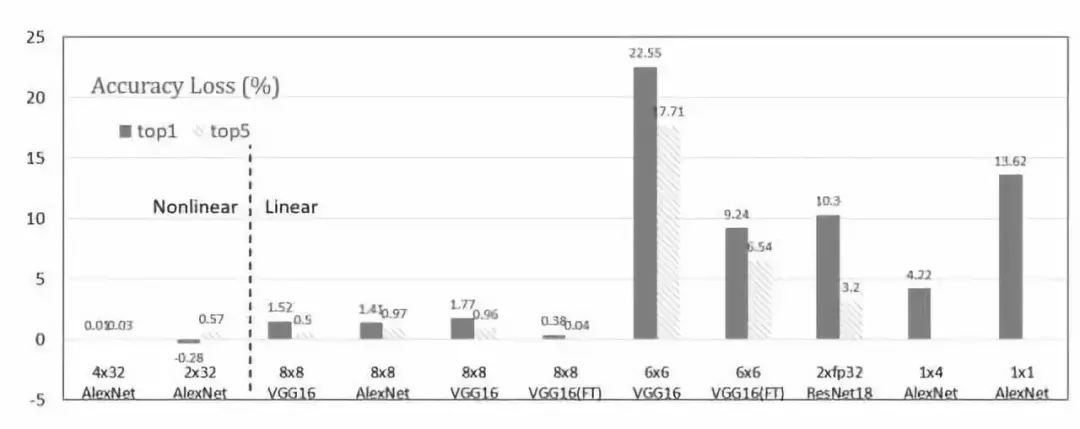
圖 2: 不同數據量化方法的比較
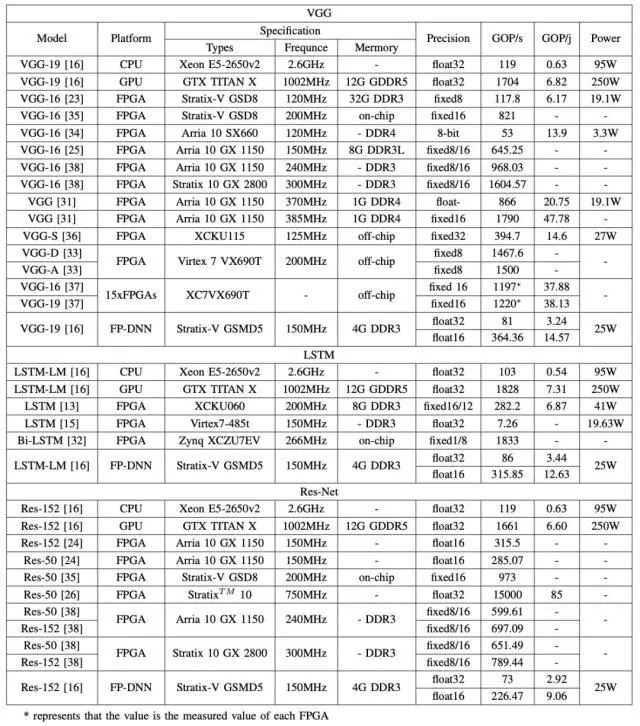
表 1: 不同平臺上不同模型的性能比較
機遇和挑戰
早在 20 世紀 60 年代,Gerald Estrin 就提出了可重構計算的概念。但是直到 1985 年,第一個 FPGA 芯片才被 Xilinx 引入。盡管 FPGA 平臺的并行性和功耗非常出色,但由于其重構成本高,編程復雜,該平臺沒有引起人們的重視。隨著深度學習的持續發展,其應用的高并行性使得越來越多的研究人員投入到基于 FPGA 的深度學習加速器研究中來。這也是時代的潮流。
基于 FPGA 加速器的優勢
1)高性能,低能耗:高能效的優點不容小覷,之前的許多研究已經證明了這一點。從表 1 中可以看出,GOP/j 在 FPGA 平臺上的表現可以達到在 CPU 平臺上的幾十倍,它在 FPGA 平臺上表現的最低水平與其在 GPU 平臺上的表現處于一個層級。這足以說明基于 FPGA 的神經網絡加速器的高能效優勢。
2)高并行性:高并行性是選擇 FPGA 平臺加速深度學習的主要特性。由于 FPGA 的可編輯邏輯硬件單元,可以使用并行化算法輕松優化硬件,已達到高并行性。
3)靈活性:由于 FPGA 具有可重構性,它可以適用于復雜的工程環境。例如,在硬件設計和應用設計完成之后,通過實驗發現性能未能達到理想狀態。可重構性使得基于 FPGA 的硬件加速器能夠很好地處理頻繁的設計變更并滿足用戶不斷變化的需求。因此,與 ASIC 平臺相比,這種靈活性也是 FPGA 平臺的亮點。
4)安全性:當今的人工智能時代需要越來越多的數據用于訓練。因此,數據的安全性越來越重要。作為數據的載體,計算機的安全性也變得更加顯著。目前,一提到計算機安全性,想到的都是各種殺毒軟件。但是這些軟件只能被動地防御,不能消除安全風險。相比之下,從硬件架構層級著手能夠更好地提高安全性。
基于 FPGA 的加速器的劣勢
1)可重構成本:FPGA 平臺的可重構性是一把雙刃劍。盡管它在計算提速方面提供了許多便利,但是不同設計的重構所消耗的時間卻不容忽視,通常需要花幾十分鐘到幾個小時。此外,重構過程分為兩種類型:靜態重構和動態重構。靜態重構,又叫編譯時重構,是指在任務運行之前配置硬件處理一個或多個系統功能的能力,并且在任務完成前將其鎖定。另一個也稱為運行時配置。動態重構是在上下文配置模式下進行的。在執行任務期間,硬件模塊應該按照需要進行重構。但是它非常容易延遲,從而增加運行時間。
2)編程困難:盡管可重構計算架構的概念被提出很久了,也有很多成熟的工作,但可重構計算之前并未流行起來。主要有兩個原因:
從可重構計算的出現到 21 世紀初的 40 年時間是摩爾定律的黃金時期,其間技術每一年半更迭一次。所以這種架構更新帶來的性能提升不像技術進步那么直接、有力;對成熟的系統而言,在 CPU 上傳統的編程采用高階抽象編程語言。但是,可重構計算需要硬件編程,而通常使用的硬件編程語言(Verilog、VHDL)需要程序員花費大量時間才能掌握。
期望
盡管基于 FPGA 的神經網絡加速器仍舊有這樣、那樣的問題,但其未來發展依然可期。以下幾個方向仍然有待研究:
優化計算流程中的其他部分,現在,主流研究聚焦在矩陣運算回路,激活函數的計算少有人涉及。訪問優化。需要進一步研究進行數據訪問的其他優化方法。數據優化。使用能夠自然提升平臺性能的更低位數據,但大部分的低位數據使得權重和神經元的位寬一樣。圖 2 還可以改進與非線性映射的位寬差。所以,應該探索出更好的平衡態。頻率優化。當前,大部分 FPGA 平臺的運算頻率在 100-300MHz,但 FPGA 平臺理論上的運算頻率可以更高。這一頻率主要受限于片上 SRAM 和 DSP 之間的線程。未來研究需要找到是否有方式避免或者解決該問題。FPGA 融合。據參考論文 37 中提到的表現,如果規劃和分配問題能夠得到良好解決,多 FPGA 集群可以取得更好的結果。此外,當前此方向沒有太多研究。所以非常值得進一步探索。自動配置。為了解決 FPGA 平臺上復雜的編程問題,如果做出類似英偉達 CUDA 這樣的用戶友好的自動部署框架,應用范圍肯定會拓寬。
-
FPGA
+關注
關注
1630文章
21796瀏覽量
605989 -
加速器
+關注
關注
2文章
807瀏覽量
38087 -
AI
+關注
關注
87文章
31513瀏覽量
270326 -
深度學習
+關注
關注
73文章
5513瀏覽量
121545
原文標題:基于FPGA的深度學習加速器的挑戰與機遇
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
FPGA在做深度學習加速時需要的技能
FPGA做深度學習能走多遠?
華為FPGA加速云服務器如何加速讓硬件應用高效上云?
機器學習實戰:GNN加速器的FPGA解決方案
一種基于FPGA的圖神經網絡加速器解決方案
英特爾推出深度學習加速器和新一代至強芯片抗衡英偉達
優化基于FPGA的深度卷積神經網絡的加速器設計
基于深度學習的矩陣乘法加速器設計方案

2022 谷歌出海創業加速器展示日: 見證入營企業成長收獲
基于FPGA的深度學習CNN加速器設計方案





 工商網監
工商網監
評論