 谷歌提出元獎勵學習,兩大基準測試刷新最優結果
谷歌提出元獎勵學習,兩大基準測試刷新最優結果
RL算法由于獎勵不明確,智能體可能會收到“利用環境中的虛假模式”的正反饋,這就有可能導致獎勵黑客攻擊。谷歌提出了使用開發元獎勵學習(MeRL)來解決未指定獎勵的問題,通過優化輔助獎勵函數向智能體提供更精確的反饋。
強化學習(RL)為優化面向目標的行為,提供了統一且靈活的框架。
并且在解決諸如:玩視頻游戲、連續控制和機器人學習等具有挑戰性的任務方面,取得了顯著成功。
RL算法在這些應用領域的成功,往往取決于高質量和密集獎勵反饋的可用性。
然而,將RL算法的適用性,擴展到具有稀疏和未指定獎勵的環境,是一個持續的挑戰。
需要學習智能體從有限的反饋中,概括例如如何學習正確行為的問題。
在這種問題設置中研究RL算法性能的一種自然方法,是通過自然語言理解任務。
為智能體提供自然語言輸入,并且需要生成復雜的響應,以實現輸入過程中指定的目標,同時僅接收“成功-失敗”的反饋。
例如一個“盲”智能體,任務是通過遵循一系列自然語言命令(例如,“右,上,上,右”)到達迷宮中的目標位置。
給定輸入文本,智能體(綠色圓圈)需要解釋命令,并基于這種解釋采取動作以生成動作序列(a)。
如果智能體人達到目標(紅色星級),則獲得1的獎勵,否則返回0。
由于智能體無法訪問任何可視信息,因此智能體解決此任務,并概括為新指令的唯一方法,是正確解釋指令。
在這些任務中,RL智能體需要學習從稀疏(只有少數軌跡導致非零獎勵)和未指定(無目的和意外成功之間的區別)獎勵。
重要的是,由于獎勵不明確,智能體可能會收到“利用環境中的虛假模式”的正反饋,這就有可能導致獎勵黑客攻擊,在實際系統中部署時會導致意外和有害的行為。
在“學習從稀疏和未指定的獎勵中進行概括”中,使用開發元獎勵學習(MeRL)來解決未指定獎勵的問題,通過優化輔助獎勵函數向智能體提供更精確的反饋。
《Learning to Generalize from Sparse and Underspecified Rewards》論文地址:
https://arxiv.org/abs/1902.07198
MeRL與使用“新探索策略收集到成功軌跡”的記憶緩沖區相結合,從而通過稀疏獎勵學習。
這個方法的有效性在語義分析中得到證明,其目標是學習從自然語言到邏輯形式的映射(例如,將問題映射到SQL程序)。
本文研究了弱監督問題設置,其目標是從問答配對中自動發現邏輯程序,而不需要任何形式的程序監督。
例如下圖中找出“哪個國家贏得最多銀牌?”,智能體需要生成類似SQL的程序,以產生正確的答案(即“尼日利亞”)。
所提出的方法在WikiTableQuestions和WikiSQL基準測試中實現了最先進的結果,分別將先前的工作提升了1.2%和2.4%。
MeRL自動學習輔助獎勵函數,而無需使用任何專家演示(例如,ground-truth計劃),使其更廣泛適用并且與先前的獎勵學習方法不同。
高級概述:
元獎勵學習(MeRL)
MeRL在處理不明確獎勵方面發現,虛假軌跡和實現意外成功的程序,對智能體的泛化性能不利。
例如,智能體可能解決上述迷宮問題的特定實例。但是,如果它在訓練期間學會執行虛假動作,提供看不見的指令則可能導致其失敗。
為了緩解這個問題,MeRL優化了更精確的輔助獎勵函數,可以根據行動軌跡的特征區分意外、或非意外的成功。
通過元學習最大化訓練的智能體在保持驗證集上的表現,來優化輔助獎勵。
從稀疏獎勵中學習
要從稀疏的獎勵中學習,有效的探索如何找到一組成功軌跡,至關重要。
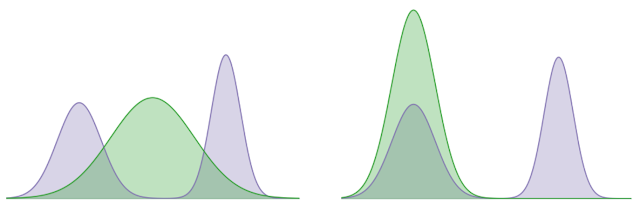
論文通過利用Kullback-Leibler(KL)發散的兩個方向來解決這一挑戰,這是一種衡量兩種不容概率分布的方法。
在下面的示例中,使用KL散度來最小化固定雙峰(陰影紫色)和學習高斯(陰影綠色)分布之間的差異,這可以分別代表智能體的最優策略分布,和學習的策略的分布。
KL對象的一個學習方向,試圖覆蓋兩種模式的分布,而其他目標學習的分布,則在尋求特定模式(即,它更喜歡A模式而不是B模式)。
我們的方法利用模式覆蓋了KL關注多個峰值以收集多樣化的成功軌跡和模式的傾向,尋求KL在軌跡之間的隱含偏好,以學習強有力的策略。
結論
設計區分最佳和次優行為的獎勵函數對于將RL應用于實際應用程序至關重要。
這項研究在沒有任何人為監督的情況下向獎勵函數建模方向邁出了一小步。
在未來的工作中,我們希望從自動學習密集獎勵函數的角度解決RL中的信用分配問題。
致謝
這項研究是與Chen Liang和Dale Schuurmans合作完成的。 我們感謝Chelsea Finn和Kelvin Guu對該論文的評論。
-
谷歌
+關注
關注
27文章
6195瀏覽量
106016 -
智能體
+關注
關注
1文章
166瀏覽量
10614 -
強化學習
+關注
關注
4文章
268瀏覽量
11301
原文標題:谷歌提出元獎勵學習,兩大基準測試刷新最優結果
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
影響OTDR測試結果的因素
MLCommons推出AI基準測試0.5版
谷歌正式發布Gemini 2.0 性能提升近兩倍
ESD HBM測試差異較大的結果分析


浪潮信息AS13000G7榮獲MLPerf? AI存儲基準測試五項性能全球第一
華為云圖引擎服務GES震撼業界,刷新基準測試世界紀錄
普強成功榮登兩大榜單
中文大模型測評基準SuperCLUE:商湯日日新5.0,刷新國內最好成績

谷歌提出大規模ICL方法
用STM32L4R9驅動480*800的LCD屏幕,結果屏幕刷新看起來是逐行進行,刷新速度較慢,是否正常?
通用CPU性能基準測試的研究現狀





 工商網監
工商網監
評論