 波束成形雷達在人工智能加持下可能是自動駕駛的制勝法寶
波束成形雷達在人工智能加持下可能是自動駕駛的制勝法寶
自動駕駛汽車中的人工智能(AI)應用已經很常見,從能夠識別行人并閱讀交通標志的深度卷積神經網絡,到可以讓Waymo自動駕駛汽車安全通過交叉路口的算法,先進的機器學習無處不在。相比之下,令人詫異的是目前的傳感器仍然不夠智能。
傳感器的短板
不過,不要誤解我的意思,目前的傳感器通過傳統方法已經能夠提供驚人的性能。高分辨率數字攝像頭正在變得越來越便宜,并且在尺寸和可靠性方面也能夠滿足工程師的理想要求。雷達的探測范圍和分辨率也一直在提高。激光雷達(LiDAR)雖然價格昂貴,但卻提供了令人難以置信的3D環境感知能力,解鎖了各種自動駕駛應用。
但是,所有這些傳感器,通訊大多是單向的。一旦攝像頭定好位,它就會每33毫秒發送一張它所指向的環境圖片,直到被命令停止運行。頂級的機械旋轉LiDAR也是按預設方向持續捕捉并傳輸數據流。目前的雷達也與此類似。
對比人類駕駛員“捕捉”周圍環境的方式,人類會不時掃描道路,尋找可能進入道路的物體。當接近十字路口時,人類可能會向每個方向查看,觀察是否可以安全通過。人類如果觀察到正在路邊奔跑的孩子,可能會把注意力集中在他們身上,以防突發情況需要緊急停車。真正智能的自動駕駛汽車不僅需要能夠從預設的掃描模式中獲取信息,還要能夠將其信息收集重點“聚焦”在環境中最相關的區域。
雖然在傳感器中嵌入人工智能本身具有挑戰,但其潛在的效益是巨大的。用最高效的方式收集數據,可以在降低計算量和材料成本的同時提高性能,這是Level 4級和5級自動駕駛走向大眾的迫切需求。
機器學習
機器學習和人工神經網絡的研究,始終要求與人類的認知進行比較。因此,近年一種以人類認知經驗為核心的概念正受到越來越多的關注。據麥姆斯咨詢報道,近期一篇關于“殘差注意力網絡(Residual Attention Network)”的論文,采用堆疊殘差注意力模塊在標準物體識別基準上實現了最先進的性能。
這一突破性研究真正令人驚嘆的是,他們的網絡層數不到下一代最佳方案的一半。傳統的卷積神經網絡都是平等地對待每個像素,無論其包含什么內容。相比之下,在這個殘差注意力網絡中,每個注意力模塊都執行兩項任務:決定看哪里,以及那里有什么。這種架構可使網絡只關注每張圖像中最重要的元素,使其相比競爭方案更具優勢。
“Show, Attend and Tell”算法
“Show, Attend and Tell”算法展示了另一種非常令人印象深刻的方案。以前的工作都是只關注圖像一次,然后使用最后一層的全連接層得到圖像最有用的信息。這樣的缺點就是在描述圖像的時候丟失了很多有用的信息。
這項研究中所提取的這些矢量來自于低級(low-level)的卷積層,這使得解碼器可以通過選擇所有特征向量的子集來選擇性地聚焦于圖像的某些部分,也就是將注意力(Attention)機制嵌入。Attention機制可以學習到類似于人類注意力一樣的信息。
網絡神經元
還有一些研究使用人工神經網絡來選擇何時使用哪個傳感器。在近期發表的一項研究中,研究人員為他們被稱為“傳感器轉換注意網絡”開發了一種架構:將不同類型的傳感器引入一個共同架構的一種神經網絡系統。這項研究探討了他們的算法能夠評估來自每個傳感器的噪聲水平,并忽略它確定為不可靠的傳感器。
舉例來說,比如從電影中轉錄語音。如果音頻非常清晰但視頻很模糊,則可以完全忽略視頻,通過將音頻饋送到長短期記憶神經網絡(LSTM)來獲得最佳性能;如果音頻嚴重失真,但是視頻清晰,則可以通過使用卷積神經網絡嘗試讀取演講者的嘴唇來提高性能。獲悉哪種傳感更可靠,是建立像人類一樣注意力算法的重要一步。
需要更進一步的研究
雖然這些研究成果很喜人,但它們對人類注意力的模仿方式還不夠完善。當人類關注某個物體時,會用眼睛追蹤它。這是因為我們的視覺在視野中心最好,而忽略邊緣附近的區域。可以想象傳感器也以相同的方式運行,讓它們更多地掃描周圍環境中的關鍵區域,而對不感興趣的區域執行快速、粗略的探測。
關于這個問題的一項非常重要的研究由Larochelle和Hinton發表于2010年。受人眼功能的啟發,他們創建了一種模型,在該模型中,神經網絡會選擇輸入圖像中需要查看的區域。這些區域將以高分辨率傳送,而周圍區域的信息將模糊處理。通過結合這些類似人眼的“中央凹視”,可以看到神經網絡以接近人眼的方式掃描圖像。
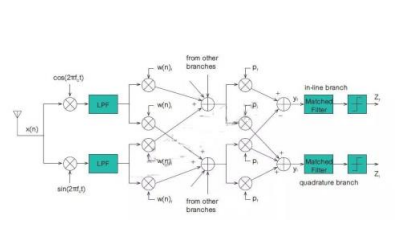
雖然上述大部分研究都集中在攝像頭成像上,但對于自動駕駛傳感器來說最有潛力的是固態模擬雷達。傳統的數字波束成形雷達將寬泛的信號發射到周圍環境中,然后在仔細分析反射回波的基礎上,嘗試識別環境中的目標。
相比之下,固態模擬雷達將所有能量集中在一個非常窄的波束中,像LiDAR一樣對周圍環境進行掃描。然而,與LiDAR不同的是,雷達通常使用一系列調制脈沖來測量其視場中物體的位置和速度。這種方案提供了無與倫比的探測范圍、角分辨率和信噪比。當然,它也提出了一些挑戰和機遇。
時序就是一切
固態模擬雷達面臨的一個主要挑戰是確定所要使用的脈沖序列。脈沖序列的參數會影響最大測量范圍、最大可測量速度以及兩者的分辨率。這些限制是由物理定律決定的,因此增加其中一個就會不可避免地影響另一個。
對于擁堵的市中心,需要盡可能高的分辨率,因為在低速行駛時,距離非常遠或運動非常快的物體影響不大;相對來說,在高速公路行駛時,需要更大的探測范圍,以便盡早警告駕駛員前方的障礙物,并需要具有足夠高的最大可測量速度,以捕捉迎面駛來的車輛。有選擇地最大化雷達的性能需要算法的支持,這些算法了解它們的狀況,并能決定如何最好地探測、理解周圍的環境。
這類雷達的另一個挑戰是掃描需要時間,通常在幾個毫秒的量級。雖然這聽起來可能很短,但在每個方向上都以高分辨率掃描則需要花費太長的時間,這對實現自動駕駛來說不太實際。與上述注意力機制神經網絡非常相似,這樣的系統必須能夠基于先前的掃描對其環境的不同區域進行優先級排序。
Metawave正在這個方向上努力
汽車雷達初創公司Metawave正致力于開發硬件和軟件來解決這些問題。Metawave基于超材料的模擬波束成形雷達,可以在其他傳感器無法企及的距離捕捉信息,不過,前提是它需要將“注意力”集中于最緊要的目標。雖然Metawave目前的研究主要集中在雷達領域,但這些技術還可以在固態LiDAR甚至攝像頭應用中實現新的性能水平。
據麥姆斯咨詢此前報道,Metawave的先進雷達已經通過演示驗證,首次實現300米外的汽車及其速度探測,以及最遠可達180米外的行人和自行車探測。通過與Infineon(英飛凌)77GHz雷達芯片組(包括RXS8160 MMIC和AURIX微控制器)以及NVIDIA(英偉達)AI(人工智能)處理引擎相結合,Metawave的開發測試平臺性能相比目前現有的汽車傳感器提升了一倍以上。
像所有新興技術一樣,很難預測這個領域在五年內的發展方向。盡管如此,我相信純研究領域興起的“注意力”概念,將成為實現Level 4級和Level 5級自動駕駛不可或缺的關鍵。對于大規模生產的自動駕駛汽車來說,更是如此,成本敏感型制造商會尋求使用更高效的算法,來降低硬件成本。
關于Metawave
Metawave成立于2017年,位于加利福尼亞州帕洛阿爾托和卡爾斯巴德,是一家致力于徹底改變無線通信和雷達傳感未來的無線技術公司。利用自適應超材料和人工智能,Metawave主要專注于構建用于自動駕駛的智能波束控制雷達。Metawave正在構建能夠進行4D點云成像、非視距物體探測和車輛間(V2V)通信的高性能雷達,使自動駕駛汽車更安全、更智能、更互聯,改變汽車制造商部署雷達的方式。Metawave的投資方包括英飛凌、Hyundai(現代汽車)、Toyota(豐田汽車)、Denso(日本電裝)以及Asahi Glass等汽車產業領導者。
-
人工智能
+關注
關注
1796文章
47683瀏覽量
240302 -
自動駕駛
+關注
關注
785文章
13932瀏覽量
167013
原文標題:人工智能加持下的波束成形雷達可能是自動駕駛的制勝法寶
文章出處:【微信號:MEMSensor,微信公眾號:MEMS】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
毫米波波束成形和天線設計
雷達模擬波束成形和數字波束成形的區別
AI/自動駕駛領域的巔峰會議—國際AI自動駕駛高峰論壇
無人駕駛與自動駕駛的差別性
人工智能上路需要知道什么常識
【模擬對話】相控陣波束成形IC簡化天線設計
中汽創智科技首席人工智能官丁華杰:AI賦能自動駕駛的幾點思考 精選資料分享
什么叫嵌入式人工智能
波束成形的類型及其在RF PCB中的用途
毫米波波束成形和天線技術的實例說明






 工商網監
工商網監
評論