") Mozilla基金會發(fā)起的Common Voice項目,發(fā)布新版語音識別數(shù)據(jù)集
Mozilla基金會發(fā)起的Common Voice項目,發(fā)布新版語音識別數(shù)據(jù)集
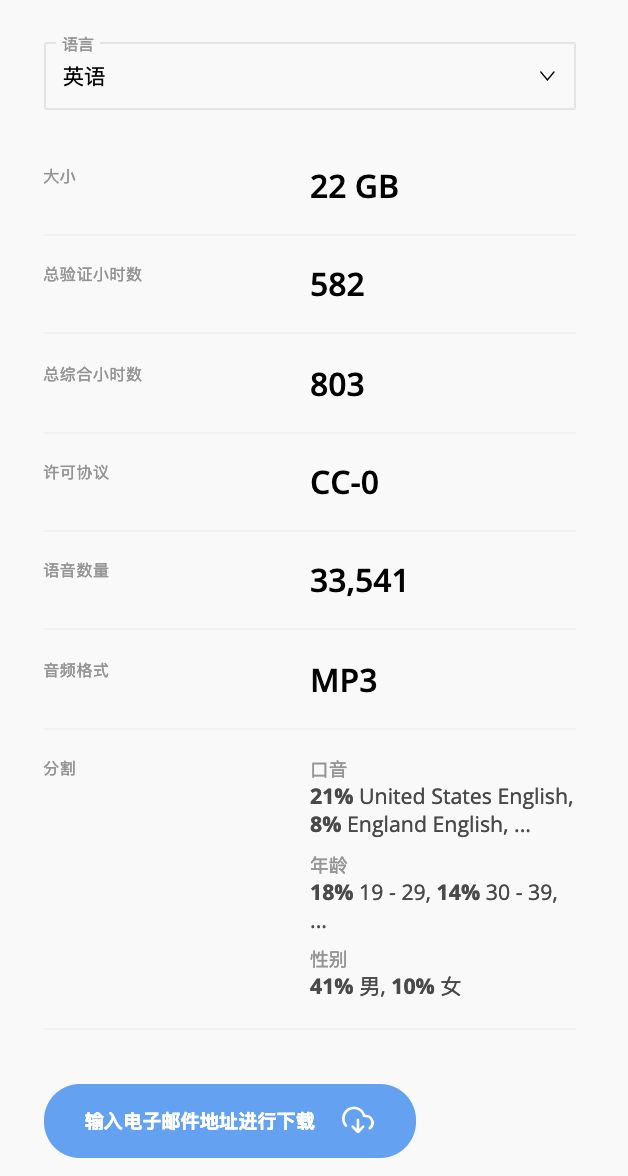
3 月 1 日,由 Mozilla 基金會發(fā)起的 Common Voice 項目,發(fā)布新版語音識別數(shù)據(jù)集,包括來自 42000 名貢獻者,超過 1400 小時的語音樣本數(shù)據(jù),涵蓋包括英語、法語、德語、荷蘭語、漢語在內(nèi)的 18 種語言。
(數(shù)據(jù)集鏈接:https://voice.mozilla.org/zh-CN/datasets)
Common Voice 項目可以集成到由 DeepSpeech,也就是基于 DeepSpeech 語音識別框架的一套語音轉(zhuǎn)文本的開源語音識別引擎。它不僅包括語音片段,還包括對訓(xùn)練語音引擎有用的元數(shù)據(jù),如說話者的年齡、性別和口音,收集這些語音片段需要做大量的工作。目前 DeepSpeech 項目已在GitHub上獲得了 9418 個 Star,1674 個 fork。
(GitHub 傳送門:https://github.com/mozilla/DeepSpeech)
它目前是同類項目中最大的多語言數(shù)據(jù)集之一,Mozilla 聲稱,此次發(fā)布的數(shù)據(jù)集比八個月前公開發(fā)布的 Common Voice 語料庫要更加龐大,其中包含來自 20,000 名英語志愿者的 500 小時語音數(shù)據(jù)(400,000 條錄音),而且語料庫還將進一步擴充。該基金會表示,通過 Common Voice網(wǎng)站和移動應(yīng)用,他們正在積極開展 70 種語言的數(shù)據(jù)收集工作。
2017 年 6 月,Mozilla 宣布推出 Project Common Voice 眾包計劃,旨在為語音識別應(yīng)用構(gòu)建開源數(shù)據(jù)集。他們邀請來自世界各地的志愿者通過網(wǎng)絡(luò)和移動應(yīng)用貢獻語音記錄的文本片段,當然,他們會非常嚴格地保護項目貢獻者的隱私。
2017 年 11 月,Mozilla 基金會發(fā)布了第一批 Common Voice 英語數(shù)據(jù)集成果,該數(shù)據(jù)集包括大約 500 個小時的語音數(shù)據(jù),以及來自 20,000 個志愿者貢獻的 400,000 條錄音。2018 年 6 月,Mozilla開始收集法語、德語和威爾士語等 40 多種語種的眾包語音數(shù)據(jù)。
為了簡化流程,Mozilla 本周還推出了一款改進的 Common Voice web 工具,其可以對不同的語音剪輯進行更改,還增加了用于查看、重新錄制和跳過剪輯的新控件,一個可以快速切換儀表板的“說話”和“收聽”模式的開關(guān),以及選擇退出語音會話的選項。此外,它正在推出新的配置文件功能,允許用戶跨語言跟蹤他們的語言進度和指標,并添加人口統(tǒng)計信息。
未來幾個月里,Mozilla 表示將嘗試不同的方法來增加數(shù)據(jù)收集的數(shù)量,提升數(shù)據(jù)質(zhì)量,并且最終計劃使用部分錄音數(shù)據(jù)來開發(fā)語音產(chǎn)品。
語音技術(shù)將是一大科技技術(shù)革新,但可惜的是,目前操縱這場革新游戲的只有大型科技公司。
首先,科技巨頭一般都來自科技強國,而用于訓(xùn)練機器的語音數(shù)據(jù)目前更偏向于英語、中文等一些特定的語言,在多樣性方面,顯然這并不適合全人類。
其次,像亞馬遜、谷歌、蘋果這樣的科技巨頭正在大力投資他們的智能助手,但由此產(chǎn)生的數(shù)據(jù)集并不對外開放,而像學(xué)生、創(chuàng)業(yè)公司和對構(gòu)建語音設(shè)備感興趣的人只能訪問非常有限的數(shù)據(jù)集,而且可能還需要付費購買。
基于此,Mozilla 基金會認為,沒有足夠的數(shù)據(jù)開放給公眾使用,將會扼殺科技創(chuàng)新,開放語音數(shù)據(jù)集則可以讓更多人參與進來,讓任何人都可以自由地使用該數(shù)據(jù)集,將語音技術(shù)嵌入到各種應(yīng)用和服務(wù)中。這類似于 OpenStreetMap這樣的開放眾包項目,該項目為開發(fā)人員提供開放且可自由使用的世界地圖。
在新的數(shù)據(jù)集發(fā)布后,外國網(wǎng)友們也對此進行了評價:
看到開放數(shù)據(jù)領(lǐng)域的創(chuàng)新真是太好了。最近有許多斷言認為,質(zhì)量更高的 ML 數(shù)據(jù)將要比 ML 算法更重要,這么說是對的,特別是在語音識別等領(lǐng)域。然而,要趕上科技巨頭還有很長的路要走。因為在 15 年前,就有公司每年會處理 100 萬分鐘的標簽語音數(shù)據(jù)。
除非我們在這方面進行投資,否則老牌企業(yè)和新進入這個市場的企業(yè)之間的數(shù)據(jù)差距將繼續(xù)擴大。
另有網(wǎng)友花了時間驗證了一些語音,他在評論中表達了質(zhì)疑稱:
至少在我能聽出來的范圍內(nèi),我沒有聽到任何句子說錯了。不過,我確實遇到了大量非常糟糕的樣本,以至于有些難以理解。比如口音重、有背景噪音或者非常安靜,而且他覺得一些“機械的”樣本是通過文本轉(zhuǎn)語音軟件生成的。所以 Common Voice 能提供優(yōu)質(zhì)數(shù)據(jù)嗎?
還有網(wǎng)友拿開源數(shù)據(jù)集 LibriSpeech 做了對比:
ASR 訓(xùn)練的有聲讀物是絕對不錯的。事實上,在 Common Voice 之前,最大的 ASR 公開訓(xùn)練數(shù)據(jù)集是 LibriSpeech (http://www.openslr.org/12/)。同樣值得注意的是,Mozilla 的 DeepSpeech 模型的第一個版本使用 LibriSpeech 進行了訓(xùn)練和測試。但是正如其他人提到的由于一些數(shù)據(jù)集不夠好,由 Common Voice 的數(shù)據(jù)集訓(xùn)練的有聲讀物存在一些瑕疵。
但是 Common Voice 的目標不是取代 LibreSpeech 或其他開放數(shù)據(jù)集(如 TED 演講)作為訓(xùn)練數(shù)據(jù)集,而是它們的有益補充。
總之,相較于目前已開源的其他語音數(shù)據(jù)集類型單一,數(shù)據(jù)量不足,數(shù)據(jù)雜亂的情況,雖然而 Common Voice 的數(shù)據(jù)集有不足,但在綜合多樣性、豐富性和質(zhì)量方面都遙遙領(lǐng)先。它有望被全世界更大范圍內(nèi)的開發(fā)者們所關(guān)注并受益,也將為語音技術(shù)的發(fā)展帶來不可估量的價值。
-
語音識別
+關(guān)注
關(guān)注
38文章
1742瀏覽量
112927 -
語音技術(shù)
+關(guān)注
關(guān)注
2文章
226瀏覽量
21318 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1209瀏覽量
24834
原文標題:1400小時開源語音數(shù)據(jù)集,你想要都在這兒
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論