 斯坦福NLP的強大QA數據集
斯坦福NLP的強大QA數據集
很多朋友在互聯網搜索問題的時候都會大贊引擎返回的結果,而不是丟給你一堆鏈接讓你自己去查找。各類搜索引擎會對問題進行有效的匹配,總能準確的告訴你世界上有多少個國家、中國的面積有多大,以及今年清明放幾天假。但是面對更為復雜的問題可能搜索引擎黔驢技窮了,比如你想要去把上周末貪心吃掉一大塊巧克力芝士蛋糕運動燃燒掉,無論是谷歌百度還是必應搜狗都沒辦法告訴你需要騎多久的車、走多遠的路才能燃燒你的卡路里。但是,任何一個人都可以從引擎返回的前面一兩條鏈接內容里找到自己的答案。
在如今這個信息爆炸的時代,無數的信息和知識文本讓我們目不暇接。讓機器替代我們去閱讀海量的文獻并為我們提供相關問題的答案在當今社會有著十分巨大的現實需求和重要的現實意義,機器閱讀理解和問答已經成為了自然語言處理領域的關鍵任務,這一能力將會實現像電影時光機器中那位知識淵博的圖書管理員一樣強大的智能AI知識系統。
近年來,類似SQuAD和TriviaQA等大規模的問答數據集促進了這一領域的快速發展,龐大的數據集是的研究人員可以訓練更大更深更強的深度學習模型。通過這些龐大數據集驅動的算法已經可以通過在百科中搜尋合適的內容來回答很多隨機的問題,而無需人類親力親為尋找答案。

SQuAD數據集從超過500篇百科文章中收集了超過10萬個問題,文章的每一段都列出一系列獨立的問題和與之相對應段落內一段連續內容作為答案。這種方式又稱為“抽取式問答” 。
雖然這些數據集推動著這一領域飛速發展,但依然存在不可回避的問題。事實上研究人員發現模型并沒有理解問題的內涵,而更多地傾向于去對問題的答案進行模式匹配。

From Jia and Liang. 研究顯示模型只學會了匹配城市名字而不是理解問題和答案。
為了克服這些問題,斯坦福NLP組的研究人員們Peng Qi & Danqi Chen提出了兩個新的數據集。在這篇文章中,研究人員探索了如何拓展現有機器閱讀系統的能力,并基于這兩個新的數據集探索了在問答任務中機器“閱讀”與“推理”間的相關性,以突破機器以簡單的模式匹配方式來回答問題。
其中CoQA數據集集中于對話的角度,通過自然對話的形式引入與文本段落相關豐富的上下文信息來為問答系統提供對話角度的探索方向。而HotpotQA數據集則超越了段落內容,主要集中于解決需要綜合多個文本,并進行有效推理才能獲得答案的復雜挑戰。
CoQA數據集
絕大多數現存的問答系統局限于獨立的回答問題(類似于SQuAD)。盡管這也是一種問答方式,但對人人類來說更常見的做法是聽過一系列你問我答的具有相互關聯的交流對話來獲取有效信息。CoQA就是這樣一個機遇對話問答的數據集,其中包含了自七個領域的8千個對話過程,共十二萬七千個問答數據,可以有效解決現有AI問答系統中存在的上述問題。

CoQA主要包含了從各種來源收集的文章,以及關于文章內容的一系列相關對話。對話的每一輪包含一個問題及其答案,同時每一個問題都依賴于先前的問題。與SQuAD以及其他現存的數據集不同的是,這一數據集中對話歷史對于回答很多問題的答案是不可或缺的。例如在上面例子中的第二個問題,在沒有對先前回答歷史理解的情況下是無法回答的。此外在對話中人們的注意力中心會隨著對話的進行而轉移,例如前述例子中的從問題四中的他們,到問題五中的他再到問題六中的他們,對于機器來說要回答這類對話中心迅速變化問題充滿了調整,數據集中的問題需要機器能夠更加理解對話的上下文內容才能有效回答。
CoQA還具有很多不同于先前數據集的新特征:
首先這一數據集并不會像SQuAD一樣將答案限制在文章中一個連續地區域。研究人員認為一個問題的答案不僅僅局限于一個單一的部分,而是會分布在文章各處。此外研究人員希望這一數據集可以支持自動評價,問題的答案可以獲得人類的認同。所以數據集的標注者不僅標注出了文章中對應的部分(作為給出答案的理由),同時將這些部分編輯為了自然語言形式的回答。這些給出答案的理由將提升問答系統模型的訓練效果。
其次現存的QA數據集大都集中在單個領域,使得基于這些數據集訓練的模型不具有通過的泛化能力。為了解決這一問題CoQA數據集收集了來自兒童故事、文學、中學英語測試、新聞、百科、Reddit和科學等七個領域的不同材料,使得數據集具有了更為豐富的特性。
通過對數據集進行深度的分析,研究人員發現了一系列豐富的語言學現象。首先27.2%的問題需要進行實際的推理,包括常識和預測的輔助,而不能簡單的從文章內容中進行轉述。比如需要通過對于主人公動作的描寫來推測他的性格。只有29.8%的問題可以直接通過文本匹配來回答。此外研究人員發現有30.5%的問題并不依賴于討論歷史,49.7%的問題包含“它”、“他”、“她”等清晰的討論語言標志,額外19.8%的問題需要參考整個段落或事件來進行回答。

與SQuAD2.0相比,CoQA數據集的問題要短很多(平均5.5詞),這反映了數據集中對話的特點。此外數據集中的問題還包含了更多豐富的問題和更多類型的提問方式,而SQuAD中的問題則更多的集中于問題本身。同時CoQA數據集還加入了更多的前綴、時態的變化,豐富了問答系統的表達。
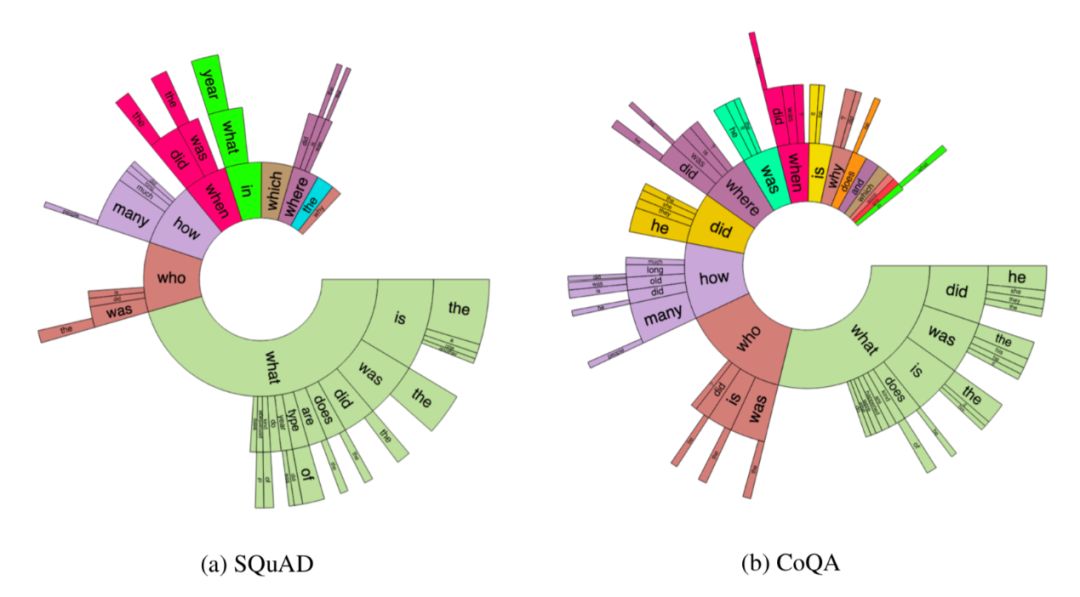
最新進展
去年八月公布數據集以來,CoQA引起了全球范圍內研究者的關注,并成為了最有效的基準數據集。基于它產生了一系列優秀的研究工作,包括谷歌強大的BERT模型和微軟亞洲研究院提出的“BERT+MMFT+ADA”方案實現87.5%的領域F1和85.3%域外F1精度。不僅達到了人類的水平并超過了不久之前基準模型將近20個點。我們相信在優秀數據集的基礎上,好的模型還將不斷涌現,未來可期!

HotpotQA:基于多文本的機器閱讀
為了探索世界本來的面目,我們再閱讀時不僅需要深入理解每篇文章上下文的內容和關系,更需要搜尋多篇相關的文獻探求事物背后的內在聯系。例如下面這些問題問題,我們基于從單篇材料進行回答:
- 雅虎是在哪個州建立的?
- 斯坦福還是CMU的計算機研究人員多?
- 剛剛吃的小蛋糕需要跑步多久才能消耗掉?
雖然網上有豐富的資料幾乎可以幫助我們解答任何問題,但很多時候我們并不能直接搜索到需要的答案。如果我們想要知道雅虎在美國哪個州創立的,我們假設你就只在wiki上進行檢索,發現我們沒能找到這個問題的直接答案,而僅僅發現了Yahoo的主頁和楊致遠,David Filo的介紹。為了回答這個問題,你需要在wiki上瀏覽并總結如下的分析才能回答這一問題:

通常我們將經歷以下步驟來回答這個問題:我們首先注意到,雅虎是在斯坦福創建的,那么隨后我們就將問題中心轉移到斯坦福在哪。隨后在斯坦福的頁面上發現它坐落于加州,最后我們就將這兩個問題聯系起來得到了雅虎于加州創立的答案。
顯然在回答這類問題的時候我們需要具備兩種能力:尋找相關信息的檢索能力以及基于多個文檔信息進行推理的能力。
這對于機器閱讀系統來說是十分重要的能力,只有具備這樣的檢索推理能力才能幫助我們從海量的信息總尋求需要的答案。
然而目前的數據集大都集中于單個文檔的理解問答,為了解決這一問題,斯坦福的研究人員們建立了另一個優秀的數據集HotPotQA。
HotpotQA數據集的內容
HotpotQA是一個包含十一萬三千個問答對的龐大數據集, 這一數據集的特點在于問題的答案需要結合大量的文檔進行分析綜合,并最終基于多個事實的支撐來推理得出答案。

這一數據集中的問答來源于整個英文版的Wikipedia,覆蓋了從科學、宇宙、地理到娛樂、運動、和法律等多樣性的內容。其中的每一個問題都需要綜合多個文檔進行推理而得到。例如前文雅虎的例子中,斯坦福大學就是回答問題中確實的一環,我們通過尋找斯坦福的位置間接的回答了雅虎創立的地點。這一條推理的邏輯鏈條如下所示:

在這問答中,斯坦福大學成為了我們銜接不同知識間的橋梁和紐帶。在很多類似的問題里都會存在這里銜接不同知識的橋梁,幫助我們最終通過整合推理得到答案。
也許你會想到,我們如果可以直接找到問題中的橋梁媒介那就太好了!雖然這一中介不能回答原始問題,但它可以指導我們進行推理和進一步的信息搜尋已解決問題。在Hotpot數據集中,研究人員總結出了一類新的問題類型:比較形問題,以增強問答系統的推理和語言理解能力。
例如,到底是斯坦福還是CMU的計算機研究人員多呢?為了回答這一問題,QA系統不僅需要檢索出相應的材料,分別找出兩個學校計算機研究人員的數量,同時還需要對結果進行比較以獲取最終答案。而比較對于現有的問答系統十分困難,問題中引入的數值比較、時間比較、數量甚至是算數問題的比較提高問題的復雜度和難度。
但這并不意味著前一個尋找相關材料的問題簡單。盡管在比較問題中搜索和定位支持材料較為容易,但對于需要橋梁媒介來進行回答的問題,這一任務很可能更具挑戰。
基于傳統信息檢索方法將wiki的文章按照與問題的相關性進行排名,研究人員發現需要平均檢索兩個以上的段落(黃金段落)才能找到與問題相關的答案,而在排名最高的是個段落中只能找到1.1個黃金段落。在按照相關性排序畫出的圖中,無論排序較高或者是較低的段落都呈現出了明顯的厚尾效應。

具體來講,有超過80%的高排名段落可以再Top10的檢索結果中找到,而只有30%的低排名結果可以在Top10中找到。假設我們僅僅依靠閱讀相關性排名較高的文件來尋找可以回答問題的環境段落的話,我們需要閱讀近600個文本,這還不包括機器有時候無法準確識別黃金段落帶來的損耗。
所以我們需要新的方法來解決這種原始的機器閱讀方法,引入推理和歸納來提升系統表現,這也將為我們帶來對于海量信息更加便捷的和有效的接入。
創建更具解釋性的問答系統
問答系統另一個重要的需求是產生結果的可解釋性。一個只會簡單給出答案的問答系統,而不能解釋或者嚴重答案的問答系統,在某種程度上來說是無法使用的。即便是在絕大多是時候這一系統都給出了正確的答案,用戶在無法再無法驗證答案的情況下是不會充分信任它的。
所以HotpotQA數據集在收集過程中,標注人員將得到答案的支撐語句標記了出來,作為數據集的一部分為問答系統提供可解釋性的支持。下圖中綠色的句子作為得到答案的依據被標注了出來。
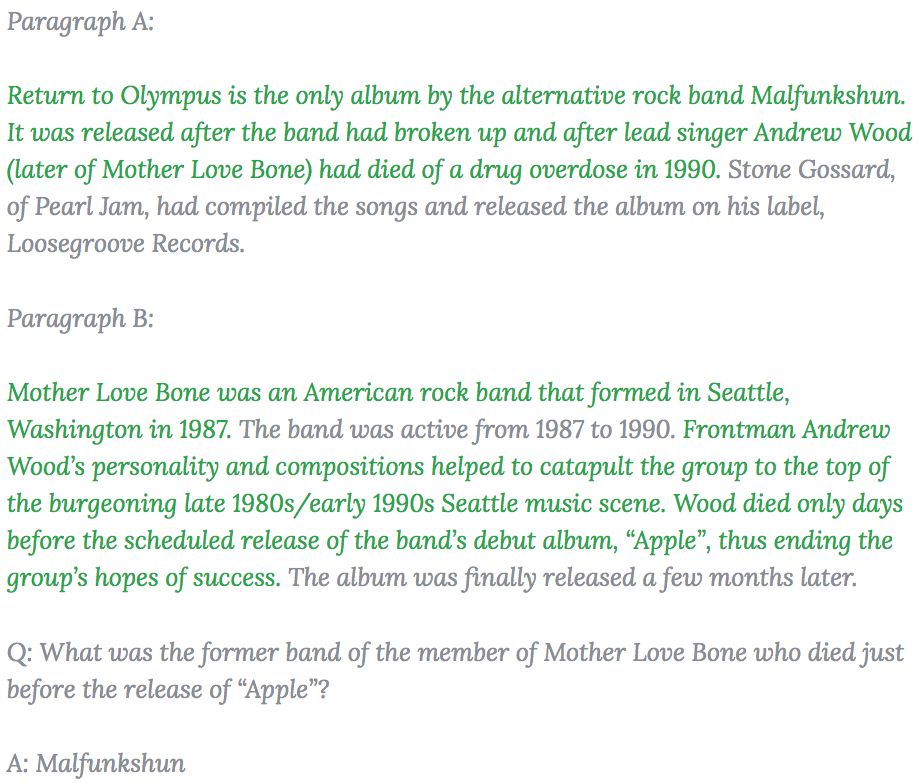
這些依據不僅能夠幫助用戶更有效地檢查系統給出的答案,同時也能在很大程度上促進系統更精確地尋找所期望的答案,為模型提供比先前數據集更豐富的監督信號。
寫在最后的思考
書寫的文字中濃縮了人類最寶貴的智慧,越來越多的電子化文件將有效驅動智能問答系統的閱讀、推理和理解能力,超越傳統的模式匹配,單一文本的學習模式,并發展出具有多文件歸納、推理和理解能力的強大系統。
CoQA系統中一系列問題形式的數據集將有效共享多個對話之間的上下文內容,綜合推理回答復雜的問題;HotpotQA數據集中的多文件推理和支撐依據將進一步促進智能問答系統對問題的綜合理解及可解釋性。這將促進學界在相關方向上更為深入的研究,更多的優秀研究和高性能模型將會不斷涌現。
數據是深度學習系統,特別是問答系統最為重要的燃料,這兩個數據集將為投入深度學習的熔爐,推動用問答系統的引擎推動深度學習這艘巨輪不斷向前。
-
AI
+關注
關注
87文章
31513瀏覽量
270333 -
機器
+關注
關注
0文章
784瀏覽量
40820 -
數據集
+關注
關注
4文章
1209瀏覽量
24833
原文標題:機器閱讀理解最新進展:超越模式匹配,斯坦福研究員探索機器“閱讀”與“推理”的相關性
文章出處:【微信號:thejiangmen,微信公眾號:將門創投】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
斯坦福開發過熱自動斷電電池
關于斯坦福的CNTFET的問題
斯坦福 CG635 供應 CG635 時鐘發生器
供應 現貨 CG635 斯坦福 時鐘發生器
熱賣現貨 CG635 斯坦福 時鐘發生器
回收新舊 斯坦福SRS DG645 延遲發生器
DG645 斯坦福 SRS DG645 延遲發生器 現金回收
"現代愛迪生"鎳氫反應電池發明者斯坦福逝世
斯坦福開啟以人為中心的AI計劃
斯坦福SR560可編程濾波器開機顯示overload維修案例

維修斯坦福SR560可編程濾波器燒了overload






 工商網監
工商網監
評論