") 當(dāng)前生成圖像最逼真的BigGAN被谷歌超越!造假效果更為逼真
當(dāng)前生成圖像最逼真的BigGAN被谷歌超越!造假效果更為逼真
當(dāng)前生成圖像最逼真的BigGAN被超越了!
出手的,是谷歌大腦和蘇黎世聯(lián)邦理工學(xué)院。他們提出了新一代GAN:S3GAN。
它們生成的照片,都是真假難辨。
下面這兩只蝴蝶,哪只更生動?
兩張風(fēng)景照片,哪張更真實(shí)?
難以抉擇也正常,反正都是假的。上面的照騙,都是左邊出自S3GAN,右邊的出自BigGAN之手。
它們還有更多作品:
至于哪些是S3GAN,答案文末揭曉。
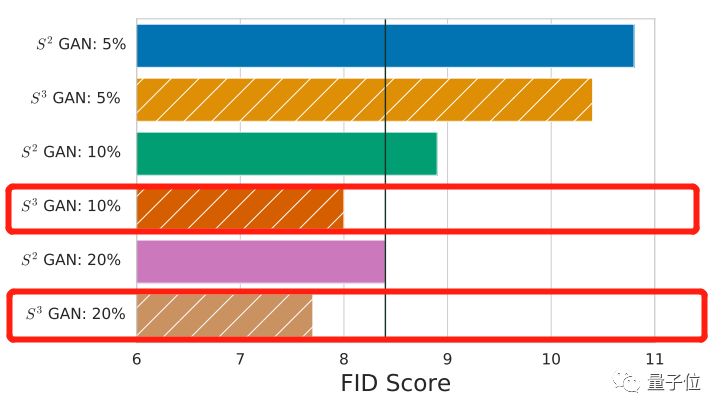
肉眼難分高下,就用數(shù)據(jù)說話。跑個FID(Frechet Inception Distance)得分,分值越低,就表示這些照騙,越接近人類認(rèn)識里的真實(shí)照片——
S3GAN是8.0分,而BigGAN是8.4分。新選手略微勝出。
你可還記得BigGAN問世之初,直接將圖像生成的逼真度提高了一個Level,引來Twitter上花樣贊賞?
如今它不止被超越,而且是被輕松超越。
“輕松”在哪呢?
S3GAN達(dá)到這么好的效果,只用了10%的人工標(biāo)注數(shù)據(jù)。而老前輩BigGAN,訓(xùn)練所用的數(shù)據(jù)100%是人工標(biāo)注過的。
如果用上20%的標(biāo)注數(shù)據(jù),S3GAN的效果又會更上一層樓。
標(biāo)注數(shù)據(jù)的缺乏,已經(jīng)是幫GAN提高生成能力,拓展使用場景的一大瓶頸。如今,這個瓶頸已經(jīng)幾乎被打破。
現(xiàn)在的S3GAN,只經(jīng)過了ImageNet的實(shí)驗(yàn),是實(shí)現(xiàn)用更少標(biāo)注數(shù)據(jù)訓(xùn)練生成高保真圖像的第一步。
接下來,作者們想要把這種技術(shù)應(yīng)用到“更大”和“更多樣化”的數(shù)據(jù)集中。
不用標(biāo)注那么多
為什么訓(xùn)練GAN生成圖像,需要大量數(shù)據(jù)標(biāo)注呢?
GAN有生成器、判別器兩大組件。
其中判別器要不停地識破假圖像,激勵生成器拿出更逼真的圖像。
而圖像的標(biāo)注,就是給判別器做判斷依據(jù)的。比如,這是真的貓,這是真的狗,這是真的漢堡……這是假圖。
可是,沒有那么多標(biāo)注數(shù)據(jù)怎么辦?
谷歌和ETH蘇黎世的研究人員,決定訓(xùn)練AI自己標(biāo)注圖像,給判別器食用。
自監(jiān)督 vs 半監(jiān)督
要讓判別器自己標(biāo)注圖像,有兩種方法。
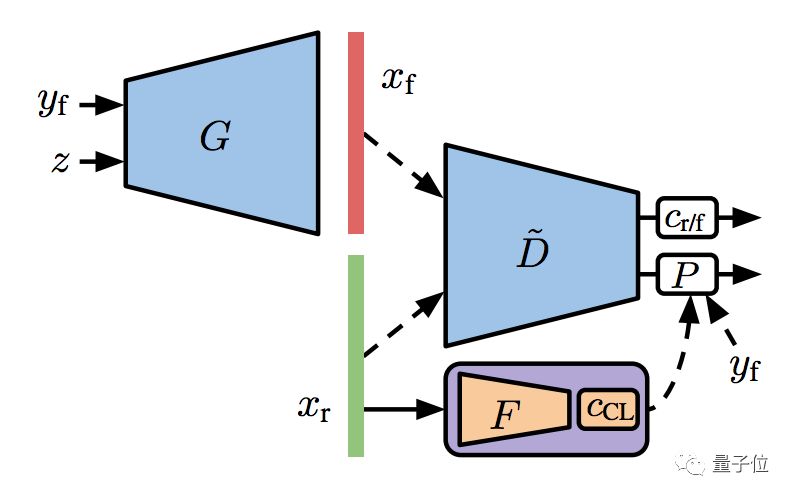
一是自監(jiān)督方法,就是給判別器加一個特征提取器 (Feature Extractor) ,從沒有標(biāo)注的真實(shí)訓(xùn)練數(shù)據(jù)里面,學(xué)到它們的表征 (Feature Representation) 。
對這個表征做聚類 (Clustering) ,然后把聚類的分配結(jié)果,當(dāng)成標(biāo)注來用。
這里的訓(xùn)練,用的是自監(jiān)督損失函數(shù)。
二是半監(jiān)督方法,也要做特征提取器,但比上一種方法復(fù)雜一點(diǎn)點(diǎn)。
在訓(xùn)練集的一個子集已經(jīng)標(biāo)注過的情況下,根據(jù)這些已知信息來學(xué)習(xí)表征,同時訓(xùn)練一個線性分類器 (Linear Classifier) 。
這樣,損失函數(shù)會在自監(jiān)督的基礎(chǔ)上,再加一項(xiàng)半監(jiān)督的交叉熵?fù)p失 (Cross-Entropy Loss) 。
預(yù)訓(xùn)練了特征提取器,就可以拿去訓(xùn)練GAN了。這個用一小部分已知標(biāo)注養(yǎng)成的GAN,叫做S2GAN。
不過,預(yù)訓(xùn)練也不是唯一的方法。
想要雙管齊下,可以用協(xié)同訓(xùn)練 (Co-Training) :
直接在判別器的表征上面,訓(xùn)練一個半監(jiān)督的線性分類器,用來預(yù)測沒有標(biāo)注的圖像。這個過程,和GAN的訓(xùn)練一同進(jìn)行。
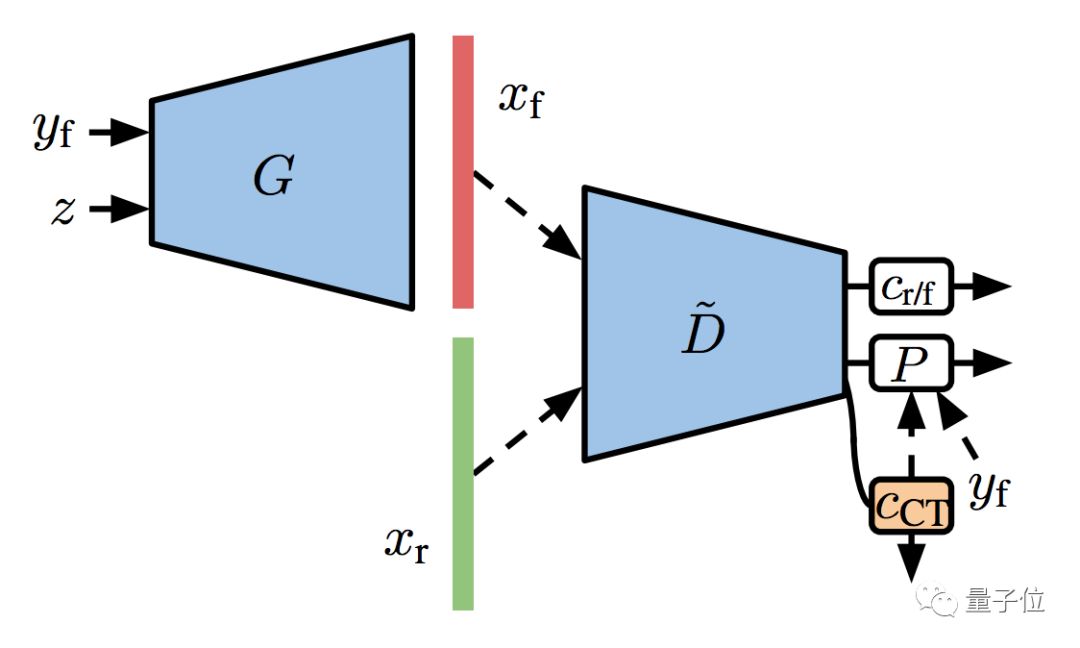
這樣就有了S2GAN的協(xié)同版,叫S2GAN-CO。
升級一波
然后,團(tuán)隊(duì)還想讓S2GAN變得更強(qiáng)大,就在GAN訓(xùn)練的穩(wěn)定性上面花了心思。
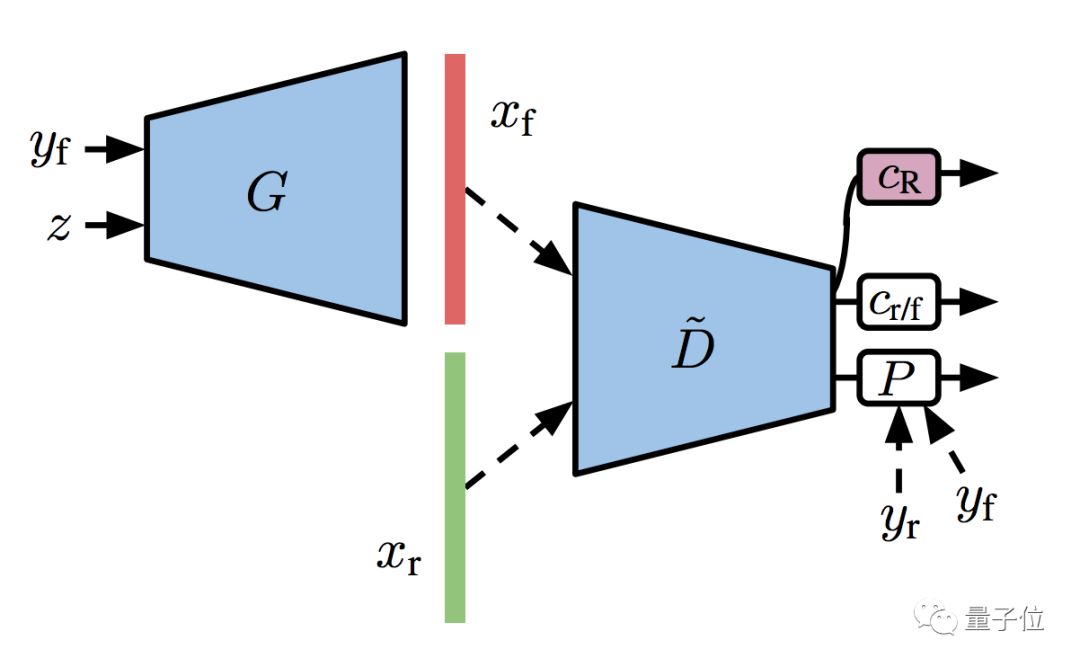
研究人員說,判別器自己就是一個分類器嘛,如果把這個分類器擴(kuò)增 (Augmentation) 一下,可能療效上佳。
于是,他們給了分類器一個額外的自監(jiān)督任務(wù),就是為旋轉(zhuǎn)擴(kuò)增過的訓(xùn)練集 (包括真圖和假圖) ,做個預(yù)測。
再把這個步驟,和前面的半監(jiān)督模型結(jié)合起來,GAN的訓(xùn)練變得更加穩(wěn)定,就有了升級版S3GAN:
架構(gòu)脫胎于BigGAN
不管是S2GAN還是S3GAN,都借用了前輩BigGAN的網(wǎng)絡(luò)架構(gòu),用的優(yōu)化超參數(shù)也和前輩一樣。
不同的是,這個研究中,沒有使用正交正則化 (Orthogonal Regularization) ,也沒有使用截斷 (Truncation) 技巧。

△BigGAN的生成器和鑒別器架構(gòu)圖
訓(xùn)練的數(shù)據(jù)集,來自ImageNet,其中有130萬訓(xùn)練圖像和5萬測試圖像,圖像中共有1000個類別。
圖像尺寸被調(diào)整成了128×128×3,在每個類別中隨機(jī)選擇k%的樣本,來獲取半監(jiān)督方法中的使用的部分標(biāo)注數(shù)據(jù)集。
最后,在128核的Google TPU v3 Pod進(jìn)行訓(xùn)練。
超越BigGAN
研究對比的基線,是DeepMind的BigGAN,當(dāng)前記錄的保持者,F(xiàn)ID得分為7.4。
不過,他們在ImageNet上自己實(shí)現(xiàn)的BigGAN,F(xiàn)ID為8.4,IS為75,并以此作為了標(biāo)準(zhǔn)。
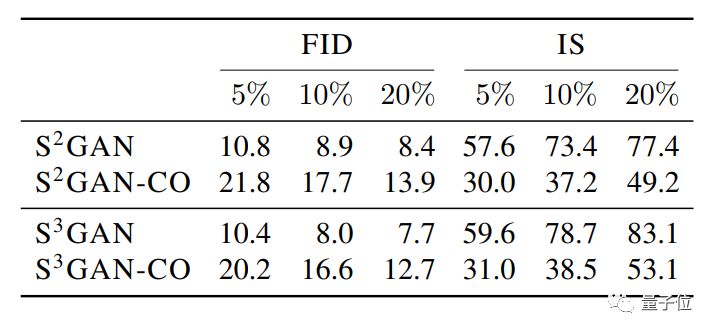
在這個圖表中,S2GAN是半監(jiān)督的預(yù)訓(xùn)練方法。S2GAN-CO是半監(jiān)督的協(xié)同訓(xùn)練方法。
S3GAN,是S2GAN加上一個自監(jiān)督的線性分類器 (把數(shù)據(jù)集旋轉(zhuǎn)擴(kuò)增之后再拿給它分類) 。
其中,效果最好的是S3GAN,只使用10%由人工標(biāo)注的數(shù)據(jù),F(xiàn)ID得分達(dá)到8.0,IS得分為78.7,表現(xiàn)均優(yōu)于BigGAN。
如果你對這項(xiàng)研究感興趣,請收好傳送門:
論文:

High-Fidelity Image Generation With Fewer Labels
https://arxiv.org/abs/1903.02271
文章開頭的這些照騙展示,就出自論文之中:
第一行是BigGAN作品,第二行是S3GAN新品,你猜對了嗎?
另外,他們還在GitHub上開源了論文中實(shí)驗(yàn)所用全部代碼:
https://github.com/google/compare_gan
-
谷歌
+關(guān)注
關(guān)注
27文章
6196瀏覽量
106018 -
圖像
+關(guān)注
關(guān)注
2文章
1089瀏覽量
40574
原文標(biāo)題:史上最強(qiáng)GAN被谷歌超越!標(biāo)注數(shù)據(jù)少用90%,造假效果卻更逼真
文章出處:【微信號:WW_CGQJS,微信公眾號:傳感器技術(shù)】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
相關(guān)推薦
借助谷歌Gemini和Imagen模型生成高質(zhì)量圖像

AI智能體逼真模擬人類行為
深入理解渲染引擎:打造逼真圖像的關(guān)鍵

谷歌和Meta希望與好萊塢合作獲得授權(quán)內(nèi)容
谷歌發(fā)布AI文生圖大模型Imagen
谷歌發(fā)布Imagen 3,提升圖像文本生成技術(shù)
深度學(xué)習(xí)生成對抗網(wǎng)絡(luò)(GAN)全解析
OpenAI人工智能Sora自動生成視頻,究竟多逼真?你害怕嗎?

麻省理工與Adobe新技術(shù)DMD提升圖像生成速度
谷歌計劃重新推出改進(jìn)后的Gemini AI模型人像生成功能
谷歌暫停Gemini人像生成服務(wù)
Groq推出大模型推理芯片 超越了傳統(tǒng)GPU和谷歌TPU
谷歌Gemini AI模型因人物圖像生成問題暫停運(yùn)行
鴻蒙開發(fā)圖形圖像——@ohos.effectKit (圖像效果)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論