 通過實戰針對機器學習之特征工程進行處理
通過實戰針對機器學習之特征工程進行處理
前言
上次對租金預測比賽進行的是數據分析部分的處理機器學習實戰--住房月租金預測(1),今天繼續分享這次比賽的收獲。本文會講解對特征工程的處理。話不多說,我們開始吧!
特征工程

“數據決定了機器學習的上限,而算法只是盡可能逼近這個上限”,這里的數據指的就是經過特征工程得到的數據。特征工程指的是把原始數據轉變為模型的訓練數據的過程,它的目的就是獲取更好的訓練數據特征,使得機器學習模型逼近這個上限。特征工程能使得模型的性能得到提升,有時甚至在簡單的模型上也能取得不錯的效果。特征工程在機器學習中占有非常重要的作用,上面的思維導圖包含了針對特征工程處理的所有方法。
缺失值處理
1print(all_data.isnull().sum())
使用上面的語句可以查看數據集中的缺失值
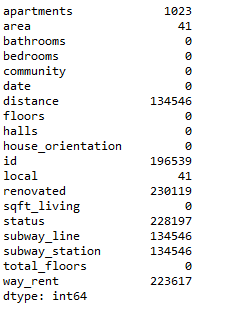
從上面的圖中可以清楚的看到各數據的缺失值。
對于缺失值是任何一個數據集都不可避免的,在數據統計過程中可能是無意的信息被遺漏,比如由于工作人員的疏忽,忘記而缺失;或者由于數據采集器等故障等原因造成的缺失,或者是有意的有些數據集在特征描述中會規定將缺失值也作為一種特征值,再或者是不存在的,有些特征屬性根本就是不存在的。
缺失值的處理,我們常用的方法有:刪除記錄:對于樣本數據量較大且缺失值不多同時正相關性不大的情況下是有效。可以使用pandas的dropna來直接刪除有缺失值的特征。數據填充:數據填充一般采用均值,中位數和中數,當然還有其他的方法比如熱卡填補(Hot deck imputation),K最近距離鄰法(K-means clustering)等。不作處理:因為一些模型本身就可以應對具有缺失值的數據,此時無需對數據進行處理,比如Xgboost,rfr等高級模型,所以我們可以暫時不作處理。
對于這次比賽缺失值的處理主要是數據的填充。
1cols=["renovated","living_status","subway_distance","subway_station","subway_line"] 2forcolincols: 3kc_train[col].fillna(0,inplace=True) 4kc_test[col].fillna(0,inplace=True) 5 6kc_train["way_rent"].fillna(2,inplace=True) 7kc_test["way_rent"].fillna(2,inplace=True) 8kc_train["area"].fillna(8,inplace=True) 9kc_train=kc_train.fillna(kc_train.mean())10kc_test["area"].fillna(8,inplace=True)11kc_test=kc_test.fillna(kc_test.mean())
對于裝修狀態,居住狀態,距離,地鐵站點和線路均用0填充,區均用中位數8來填充,出租方式用2填充,同時做了一個判斷
1kc_train['is_living_status']=kc_train['living_status'].apply(lambdax:1ifx>0else0)2kc_train['is_subway']=kc_train['subway_distance'].apply(lambdax:1ifx>0else0)3kc_train['is_renovated']=kc_train['renovated'].apply(lambdax:1ifx>0else0)4kc_train['is_rent']=kc_train['way_rent'].apply(lambdax:1ifx0else0)7kc_test['is_subway']=kc_test['subway_distance'].apply(lambdax:1ifx>0else0)8kc_test['is_renovated']=kc_test['renovated'].apply(lambdax:1ifx>0else0)9kc_test['is_rent']=kc_test['way_rent'].apply(lambdax:1ifx
異常值處理
異常值是分析師和數據科學家常用的術語,因為它需要密切注意,否則可能導致錯誤的估計。 簡單來說,異常值是一個觀察值,遠遠超出了樣本中的整體模式。
什么會引起異常值呢?
主要有兩個原因:人為錯誤和自然錯誤
如何判別異常值?
正態分布圖,箱裝圖或者離散圖。以正態分布圖為例:符合正態分布時,根據正態分布的定義可知,距離平均值3δ之外的概率為 P(|x-μ|>3δ) <= 0.003 ,這屬于極小概率事件,在默認情況下我們可以認定,距離超過平均值3δ的樣本是不存在的。 因此,當樣本距離平均值大于3δ,則認定該樣本為異常值。當數據不服從正態分布:當數據不服從正態分布,可以通過遠離平均距離多少倍的標準差來判定,多少倍的取值需要根據經驗和實際情況來決定。
異常值的處理方法常用有四種:1.刪除含有異常值的記錄2.將異常值視為缺失值,交給缺失值處理方法來處理3.用平均值來修正4.不處理
1all_data=pd.concat([train,test],axis=0,ignore_index=True) 2all_data.drop(labels=["price"],axis=1,inplace=True) 3fig=plt.figure(figsize=(12,5)) 4ax1=fig.add_subplot(121) 5ax2=fig.add_subplot(122) 6g1=sns.distplot(train['price'],hist=True,label='skewness:{:.2f}'.format(train['price'].skew()),ax=ax1) 7g1.legend() 8g1.set(xlabel='Price') 9g2=sns.distplot(np.log1p(train['price']),hist=True,label='skewness:{:.2f}'.format(np.log1p(train['price']).skew()),ax=ax2)10g2.legend()11g2.set(xlabel='log(Price+1)')12plt.show()
查看訓練集的房價分布,左圖是原始房價分布,右圖是將房價對數化之后的。
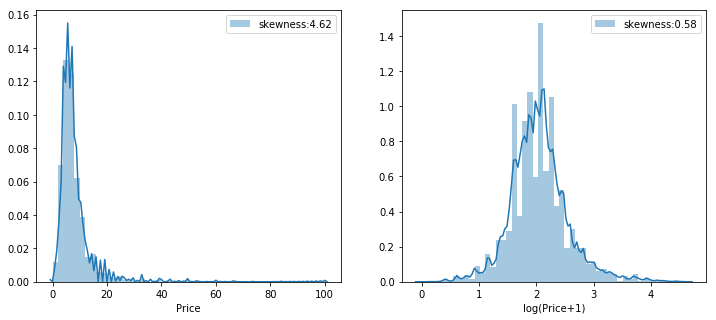
由于房價是有偏度的,將房價對數化并且將有偏的數值特征對數化
1train['price']=np.log1p(train['price'])23#將有偏的數值特征對數化4num_features_list=list(all_data.dtypes[all_data.dtypes!="object"].index)56foriinnum_features_list:7ifall_data[i].dropna().skew()>0.75:8all_data[i]=np.log1p(all_data[i])
根據上一篇我們篩選出的十個最相關的特征值,畫出離散圖,并且對離散點做處理,這里只取房屋面積舉個栗子。
1var='sqft_living'2data=pd.concat([train['price'],train[var]],axis=1)3data.plot.scatter(x=var,y='price',ylim=(0,150));

1train.drop(train[(train["sqft_living"]>0.125)&(train["price"]<20)].index,inplace=True)
這里將面積大于0.125且價格小于20的點全部刪除。
對于特征工程的處理這是在自己代碼中最重要的兩步--缺失值和異常值的處理,將類別數值轉化為虛擬變量和歸一化的處理效果不是特別好所以沒有貼上,數據集中的房屋朝向可以采用獨熱編碼,感興趣的可以試一下,我一直沒搞懂看了同學的處理他的代碼量太大,效果也不是特別明顯,自己索性沒去研究。下一次更新將針對這個問題進行模型選擇。
-
機器學習
+關注
關注
66文章
8441瀏覽量
133087 -
數據分析
+關注
關注
2文章
1461瀏覽量
34166 -
數據集
+關注
關注
4文章
1209瀏覽量
24835
原文標題:機器學習實戰--住房月租金預測(2)
文章出處:【微信號:AI_shequ,微信公眾號:人工智能愛好者社區】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
機器學習實戰之logistic回歸
【下載】《機器學習》+《機器學習實戰》
機器學習實戰:GNN加速器的FPGA解決方案
想掌握機器學習技術?從了解特征工程開始
機器學習之特征提取 VS 特征選擇


特征選擇和機器學習的軟件缺陷跟蹤系統對比



通過強化學習策略進行特征選擇






 工商網監
工商網監
評論