 何愷明等人再出重磅新作:分割任務的TensorMask框架
何愷明等人再出重磅新作:分割任務的TensorMask框架
看到今天要給大家介紹的論文,也許現在大家已經非常熟悉 Ross Girshic、Piotr Dollár 還有我們的大神何愷明的三人組了。沒錯,今天這篇重磅新作還是他們的產出,營長感覺剛介紹他們的新作好像沒多久啊!想要追趕大神腳步,確實是不能懈怠啊!
不過這次一作是來自 FAIR 的陳鑫磊博士,雖然和三人組合比起來,一作陳鑫磊還沒有那么被大家所熟知,不過其實力也是不容小覷的(畢竟后面跟著三個實力響當當的人物)。營長在陳鑫磊的個人主頁上看到他的學習經歷和研究成果,也是忍不住點贊。陳鑫磊在浙江大學國家重點實驗室 CAD&CG實驗室學習時,師從蔡登教授,隨后在 CMU 攻讀博士學位,現任職于 FAIR,畢業前曾在 Google Cloud 李飛飛和李佳組內實習。在博士研究期間,每年和導師 Abhinav Gupta 教授都有論文發表在 AAAI、CVPR、ECCV、ICCV 等頂會上,考慮篇幅,營長就從每年成果中選一篇列舉出來,大家可以前往陳鑫磊的個人主頁中可以看到全部作品。
2013-2018 年間的主要作品:
[1]、Xinlei Chen, Li-Jia Li, Li Fei-Fei, Abhinav Gupta.Iterative Visual Reasoning Beyond Convolutions. The 31st IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2018.Spotlight
[2]、Xinlei Chen, Abhinav Gupta.Spatial Memory for Context Reasoning in Object Detection. The 15th International Conference on Computer Vision(ICCV), 2017
[3]、Gunnar A. Sigurdsson,Xinlei Chen, Abhinav Gupta.Learning Visual Storylines with Skipping Recurrent Neural Networks. The 14th European Conference on Computer Vision(ECCV), 2016
[4]、Xinlei Chen, Abhinav Gupta.Webly Supervised Learning of Convolutional Networks. The 15th International Conference on Computer Vision(ICCV), 2015.Oral
[5]、Xinlei Chen, C. Lawrence Zitnick.Mind's Eye: A Recurrent Visual Representation for Image Caption Generation. The 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2015
[6]、Xinlei Chen, Alan Ritter, Abhinav Gupta, Tom Mitchell.Sense Discovery via Co-Clustering on Images and Text. The 28th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2015.
[7]、Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta.Enriching Visual Knowledge Bases via Object Discovery and Segmentation. The 27th IEEE Conference on Computer Vision and Pattern Recognition(CVPR), 2014
[8]、Xinlei Chen, Abhinav Shrivastava, Abhinav Gupta.NEIL: Extracting Visual Knowledge from Web Data. The 14th International Conference on Computer Vision(ICCV), 2013.Oral.
這幾個人從出道至今,都有非常多的佳作,出產率也非常高,最近大家還在重談去年三人組合的論文《Rethinking ImageNet Pre-training》,今天就有了這篇在密集掩碼預測新突破:《TensorMask: A Foundation for Dense Object Segmentation》,大神們簡直就是快要承包整個 CV 界了!
“CV男團”四人的個人主頁(一到四作的順序):
http://xinleic.xyz/#
http://www.rossgirshick.info/
http://kaiminghe.com/
http://pdollar.github.io/
接下來,營長就為大家帶來“CV男團”這篇最新力作的初解讀,因為論文中涉及很多與 TensorMask 框架相關的專業術語,函數定義等,還需要大家下來細細研究,感興趣的同學可以從下面的論文地址里下載論文進一步學習,也歡迎大家在后臺給我們留言,發表你的感想。
論文解讀
摘要
在目標檢測任務中,采用滑窗方式生成目標的檢測框是一種非常常用的方法。而在實例分割任務中,比較主流的圖像分割方法是首先檢測目標邊界框,然后進行裁剪和目標分割,如 Mask RCNN。在這篇工作中,我們研究了密集滑窗實例分割(dense sliding-window instance segmentation)的模式,發現與其他的密集預測任務如語義分割,目標檢測不同,實例分割滑窗在每個空間位置的輸出具有自己空間維度的幾何結構。為了形式化這一點,我們提出了一個通用的框架 TensorMask 來獲得這種幾何結構。
我們通過張量視圖展示了相較于忽略這種結構的 baseline 方法,它可以有一個大的效果提升,甚至比肩于 Mask R-CNN。這樣的實驗結果足以說明TensorMask 為密集掩碼預測任務提供了一個新的理解方向,并可以作為該領域新的基礎方法。
引言
滑窗范式(在一張圖的每個滑動窗口里面去尋找目標)是視覺任務里面最早且非常成功的方法,并且可以很自然的和卷積網絡聯系起來。雖然像 RCNN 系列方法需要在滑窗的方法上再進行精修,但是像 SSD、RetinaNet 的方法就是直接利用滑窗預測。在目標檢測里面非常受歡迎的方法,在實例分割任務中卻沒得到足夠的關注。因此本文的工作就是來填補該缺失。本文主要的 insight 就是定義密集掩碼的表示方式,并且在神經網絡中有效的實現它。與低維、尺度無關的檢測框不同,分割掩碼需要一種更具有結構化的表示方式。因此,本文在空域上,采用結構化的 4 維張量定義了掩碼的表示方式,并提出了一個基于滑窗方法的密集實例分割框架——TensorMask。在 4 維張量(V,U,H,W)中,H 和 W 表示目標的位置,而 V 和 U 表示相關掩碼的位置。與僅直接在通道上加一個掩碼分支的方法不同,這種方法是具有幾何意義的,并且可以直接在(V,U)張量上進行坐標轉換,尺度縮放等操作。在 TensorMask 框架中,作者還順手開發了一個張量尺度金字塔(tensor bipyramid),用于 4 維的尺度縮放。如下公式所示,其中 K 就是尺度。
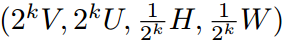 ? ? ?
? ? ?
掩碼的張量表示
TensorMask 框架的主要想法就是利用結構化的高維張量去表示密集的滑動窗口。在理解這樣的一個框架時,需要了解幾個重要的概念。
單位長度(Unit of Length):在不同的軸和尺度上有不同的單位長度,且 HW 和 VU 的單位長度可以不相等。
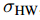 ? ? ?和 ? ? ? ?
? ? ?和 ? ? ? ?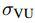 ? ? ?分別表示其單位長度。
? ? ?分別表示其單位長度。
自然表示(Natural Representation):在點(y,x)處的滑窗內,某點的掩碼值表示,如下截圖所示,其中 alpha 表示 VU 和 HW 的單位長度比率。

對齊表示(Aligned Representation):由于單位長度中 stride 的存在,自然表示存在著像素偏移的問題,因此這里有一個同 ROIAlign 相似的想法,需要從張量的角度定義一個像素級的表示。

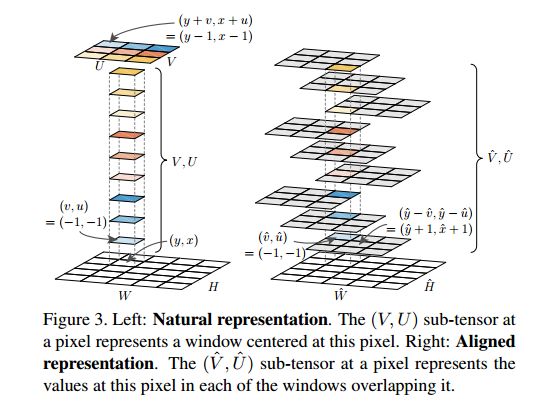
坐標轉換:用于自然表示和對齊表示間的轉換,論文給出了兩種情況下的轉換公式,一種是簡化版的( 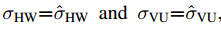 ? ? ?),一種是一般版的(就是任意的單位長度)。
? ? ?),一種是一般版的(就是任意的單位長度)。
上采樣轉換(Upscaling Transformation):下圖就是上采樣轉換的操作集合。實驗證明它可以在不增加通道數的情況下,有效的生成高分辨率的掩碼。
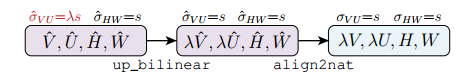
張量尺度金字塔(Tensor Bipyramid):由于掩碼存在尺度問題,它需要隨目標的大小而進行縮放,為了保持恒定的分辨率密度,提出了這種基于尺度來調整掩碼像素數量的方法。
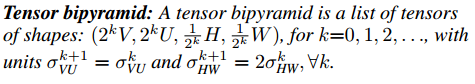
TensorMask結構
基于 TensorMask 表示的模型,有一個采用滑窗的掩碼預測分支和一個類似于檢測框回歸的分類分支。該結構不需要增加檢測框的分支。掩碼預測分支可以采用卷積的 backbone,比如 ResNet50。因此,論文提出了多個基礎(baseline)分支和張量尺度金字塔分支,幫助使用者快速上手 TensorMask。需要指出的是,張量尺度金字塔分支是最有效的一個模型。在訓練時,作者采用 DeepMask 來幫助標記數據,以及 focal loss 等等。
實驗
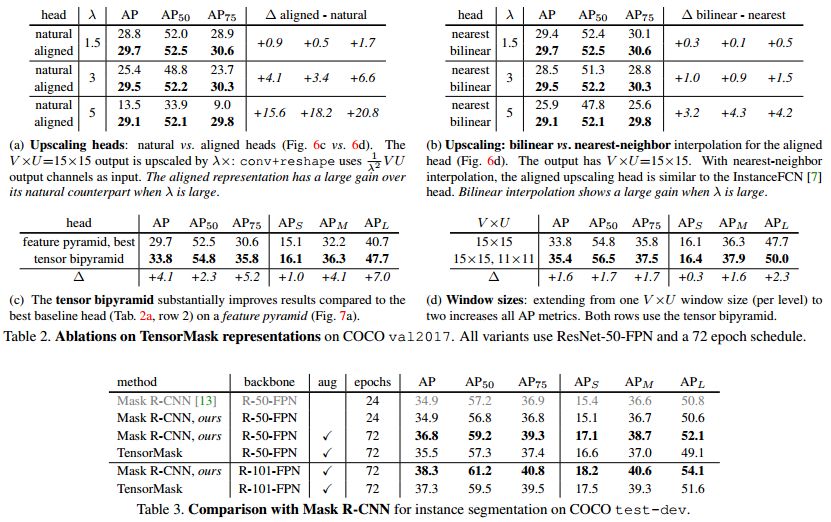
為了說明各分支或者操作的作用,論文做了大量的消融實驗來進行論證。具體結果見下圖表格的數據以及與 Mask-RCNN 可視化的對比。實驗結果證明,TensorMask 能夠定性定量的比肩 MaskR-CNN。

該項工作將滑窗方法與實例分割任務直接聯系了起來,能夠幫助該領域的研究者對實例分割有新的理解,期待代碼早日開源。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101171 -
框架
+關注
關注
0文章
403瀏覽量
17543 -
開源
+關注
關注
3文章
3403瀏覽量
42712
原文標題:何愷明等人提TensorMask框架:比肩Mask R-CNN,4D張量預測新突破
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
畫面分割器怎么調試
畫面分割器怎么連接
畫面分割器和視頻分配器有何區別
畫面分割器有幾路主輸出
圖像語義分割的實用性是什么
圖像分割和語義分割的區別與聯系
圖像分割與目標檢測的區別是什么
機器學習中的數據分割方法
圖像分割與語義分割中的CNN模型綜述
nlp自然語言處理框架有哪些
機器人視覺技術中常見的圖像分割方法
機器人視覺技術中圖像分割方法有哪些
“仲愷農業工程學院與深圳信盈達科技有限公司”揭牌儀式舉行

如何選擇RTOS?使用R-Rhealstone框架評估





 工商網監
工商網監
評論