 一圖在手,機器學習、神經網絡、數據科學要點都有
一圖在手,機器學習、神經網絡、數據科學要點都有
完全圖解人工智能、NLP、機器學習、深度學習、大數據!這份備忘單涵蓋了上述領域幾乎全部的知識點,并使用信息圖、腦圖等多種可視化方式呈現,設計精美,實用性強。
今天,新智元要為大家推薦一個超實用、顏值超高的神經網絡+機器學習+數據科學和Python的完全圖解,文末附有高清PDF版鏈接,支持下載、打印,推薦大家可以做成鼠標墊、桌布,或者印成手冊等隨手攜帶,隨時翻看。
這是一份非常詳實的備忘單,涉及具體內容包括:
神經網絡基礎知識
神經網絡圖譜
機器學習基礎知識
著名Python庫Scikit-Learn
Scikit-Learn算法
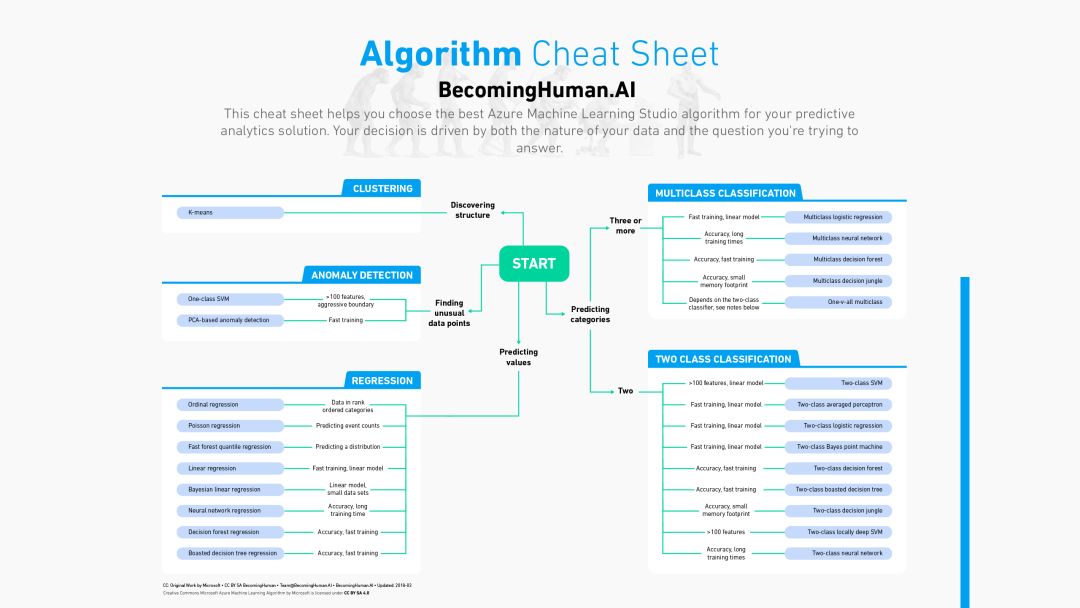
機器學習算法選擇指南
Python基礎
PySpark基礎
Numpy基礎
Bokeh
Keras
Pandas
使用Pandas進行Data Wrangling
使用dplyr和tidyr進行Data Wrangling
SciPi
MatPlotLib
使用ggplot進行數據可視化
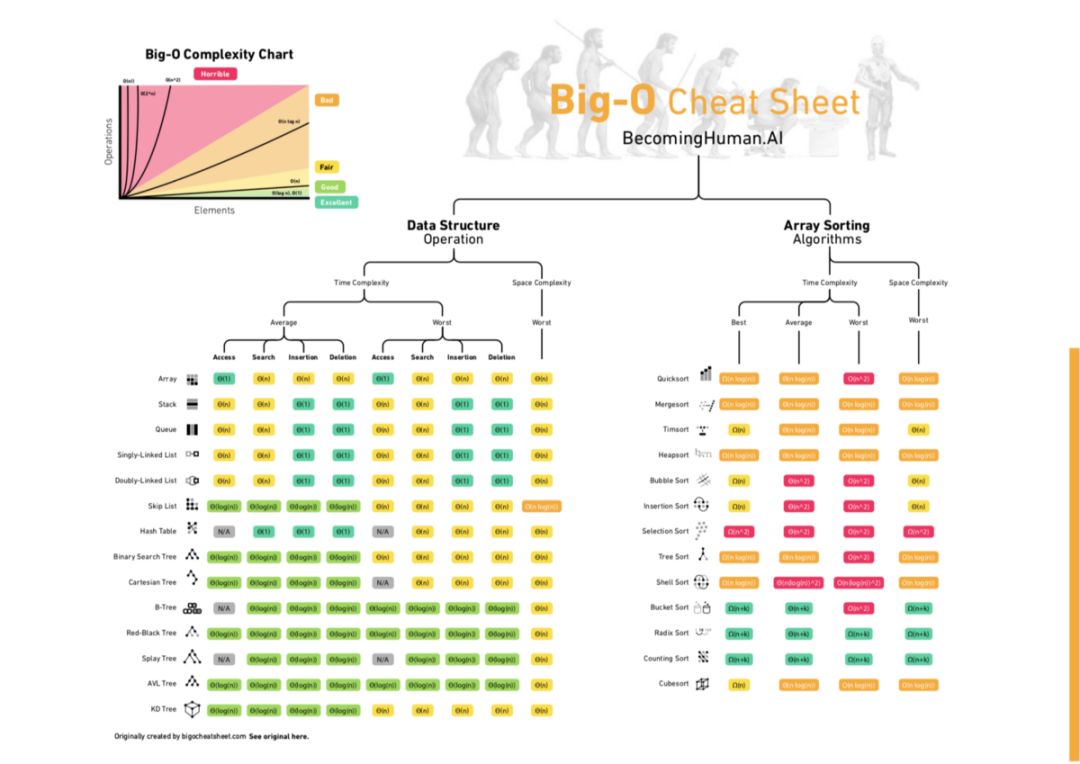
Big-O
神經網絡Cheat Sheet

神經網絡基礎知識
人工神經網絡(ANN),俗稱神經網絡,是一種基于生物神經網絡結構和功能的計算模型。 它就像一個人工神經系統,用于接收,處理和傳輸計算機科學方面的信息。
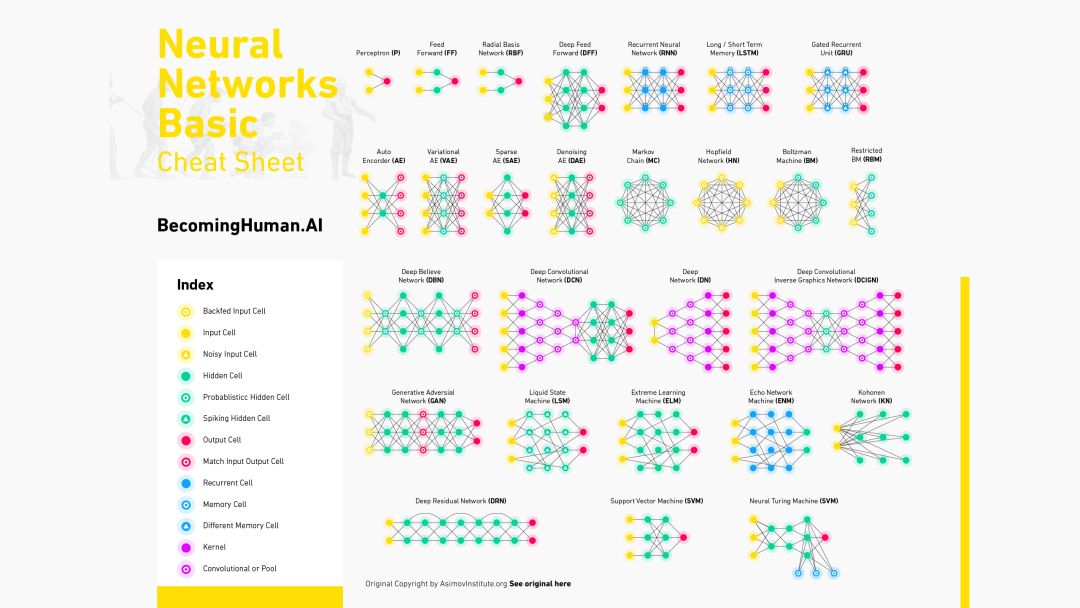
基本上,神經網絡中有3個不同的層:
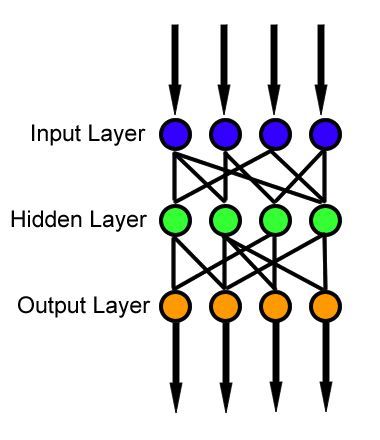
輸入層(所有輸入都通過該層輸入模型)
隱藏層(可以有多個隱藏層用于處理從輸入層接收的輸入)
輸出層(處理后的數據在輸出層可用)
神經網絡圖譜
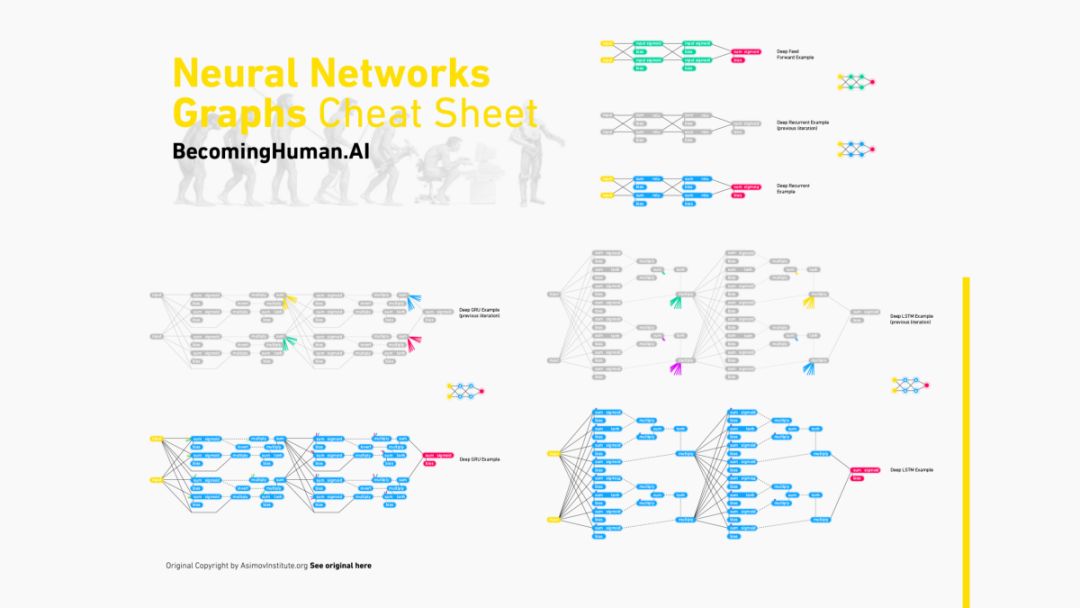
圖形數據可以與很多學習任務一起使用,在元素之間包含很多豐富的關聯數據。例如,物理系統建模、預測蛋白質界面,以及疾病分類,都需要模型從圖形輸入中學習。圖形推理模型還可用于學習非結構性數據,如文本和圖像,以及對提取結構的推理。
機器學習Cheat Sheet
用Emoji解釋機器學習

Scikit-Learn基礎
Scikit-learn是由Python第三方提供的非常強大的機器學習庫,它包含了從數據預處理到訓練模型的各個方面,回歸和聚類算法,包括支持向量機,是一種簡單有效的數據挖掘和數據分析工具。在實戰使用scikit-learn中可以極大的節省代碼時間和代碼量。它基于NumPy,SciPy和matplotlib之上,采用BSD許可證。

Scikit-Learn算法
這張流程圖非常清晰直觀的給出了Scikit-Learn算法的使用指南。
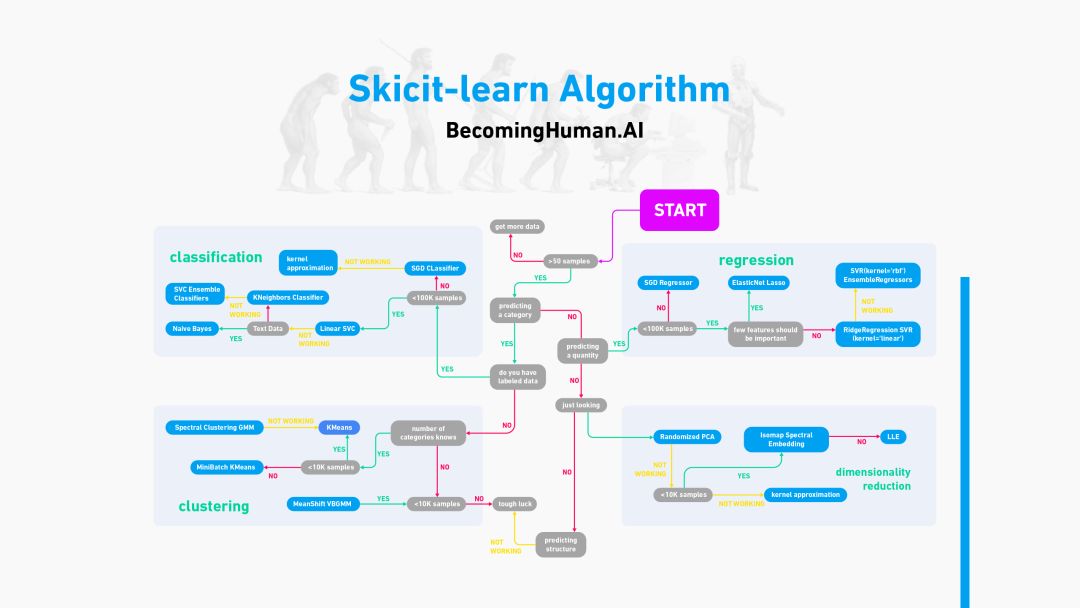
針對Azure Machine Learning Studios的Scikit-Learn算法
被Python武裝起來的數據科學Cheat Sheet


Python基礎
溫馨提示,本圖配合《100天從Python萌新到王者》食用,效果更佳。

PySpark RDD基礎
Apache Spark是專為大規模數據處理而設計的快速通用的計算引擎,通過Scala語言實現,擁有Hadoop MapReduce所具有的優點,不同的是Job中間輸出結果可以保存在內存中,從而不再需要讀寫HDFS,因此Spark能更好地適用于數據挖掘與機器學習等需要迭代的MapReduce的算法。PySpark是Spark 為 Python開發者提供的 API。

NumPy基礎
NumPy是Python語言的一個擴展程序庫。支持高端大量的維度數組與矩陣運算,此外也針對數組運算提供大量的數學函數庫,前身Numeric,主要用于數組計算。它實現了在Python中使用向量和數學矩陣、以及許多用C語言實現的底層函數,并且速度得到了極大提升。

Bokeh
Bokeh是一個交互式可視化庫,面向現代Web瀏覽器。目標是提供優雅、簡潔的多功能圖形構造,并通過非常大或流數據集的高性能交互來擴展此功能。Bokeh可以實現快速輕松地創建交互式圖表、儀表板和數據應用程序。

Keras
Keras 是一個用 Python 編寫的高級神經網絡 API,它能夠以 TensorFlow, CNTK, 或者 Theano 作為后端運行。Keras 的開發重點是支持快速的實驗。能夠以最小的時延把你的想法轉換為實驗結果,是做好研究的關鍵。

Pandas
pandas是一個為Python編程語言編寫的軟件庫,用于數據操作和分析,基于NumPy,納入了大量庫和一些標準的數據模型,提供了高效地操作大型數據集所需的工具。Pandas提供了大量快速便捷地處理數據的函數和方法。

使用Pandas進行Data Wrangling
Data Wrangling通常被翻譯成數據整理,這個詞最開始火起來是因為2017年的電影《金剛·骷髏島》,演員馬克·埃文·杰克遜扮演的角色之一被介紹為“我們的Data Wrangler史蒂夫伍德沃德”。

使用ddyr和tidyr進行Data Wrangling
為什么使用tidyr和dplyr呢?因為雖然R中存在許多基本數據處理功能,但都有點復雜并且缺乏一致的編碼,導致可讀性很差的嵌套功能以及臃腫的代碼。使用ddyr和tidyr可以獲得:
更高效的代碼
更容易記住的語法
更好的語法可讀性

Scipy線性代數
SciPy是一個開源的Python算法庫和數學工具包。 SciPy包含的模塊有最優化、線性代數、積分、插值、特殊函數、快速傅里葉變換、信號處理和圖像處理、常微分方程求解和其他科學與工程中常用的計算。 與其功能相類似的軟件還有MATLAB、GNU Octave和Scilab。

Matplotlib
Matplotlib是Python編程語言及其數值數學擴展包NumPy的可視化操作界面。 它為利用通用的圖形用戶界面工具包,如Tkinter, wxPython, Qt或GTK+向應用程序嵌入式繪圖提供了應用程序接口(API)。

使用ggplot2進行數據可視化

Big-O
大O符號(英語:Big O notation),又稱為漸進符號,是用于描述函數漸近行為的數學符號。 更確切地說,它是用另一個(通常更簡單的)函數來描述一個函數數量級的漸近上界。 ... 階)的大O,最初是一個大寫希臘字母“Ο”(omicron),現今用的是大寫拉丁字母“O”。
-
神經網絡
+關注
關注
42文章
4781瀏覽量
101177 -
機器學習
+關注
關注
66文章
8441瀏覽量
133088 -
深度學習
+關注
關注
73文章
5516瀏覽量
121556
原文標題:高清圖解:神經網絡、機器學習、數據科學一網打盡|附PDF
文章出處:【微信號:AI_era,微信公眾號:新智元】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
基于機器學習的第三代神經網絡--脈沖神經網絡的解析
labview BP神經網絡的實現
【PYNQ-Z2試用體驗】神經網絡基礎知識
基于賽靈思FPGA的卷積神經網絡實現設計
【AI學習】第3篇--人工神經網絡
卷積神經網絡模型發展及應用
卷積神經網絡簡介:什么是機器學習?
為什么使用機器學習和神經網絡以及需要了解的八種神經網絡結構
卷積神經網絡和深度神經網絡的優缺點 卷積神經網絡和深度神經網絡的區別
人工神經網絡的原理和多種神經網絡架構方法






 工商網監
工商網監
評論