 智能機器人語音識別技術詳細解析
智能機器人語音識別技術詳細解析
語音控制的基礎就是語音識別技術,可以是特定人或者非特定人的。非特定人的應用更為廣泛,對于用戶而言不用訓練,因此也更加方便。語音識別可以分為孤立詞識別,連接詞識別,以及大詞匯量的連續詞識別。對于智能機器人這類嵌入式應用而言,語音可以提供直接可靠的交互方式,語音識別技術的應用價值也就不言而喻。
如今智能語音設備或者機器人很多,如智能手機(例如Cortana,Siri,Ok Google,。。。),個人助理(例如Google Home,Amazon Echo,。。。),交互式語音應答(銀行,應答機, 。。。。。。),語音機器人(電話機器人、客服機器人、電銷機器人,……),在生活中很常見,表現都讓人驚喜。同時他們工作原理也大致相同。
1 語音識別概述
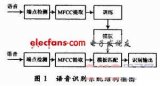
語音識別技術最早可以追溯到20世紀50年代,是試圖使機器能“聽懂”人類語音的技術。按照目前主流的研究方法,連續語音識別和孤立詞語音識別采用的聲學模型一般不同。孤立詞語音識別一般采用DTW動態時間規整算法。連續語音識別一般采用HMM模型或者HMM與人工神經網絡ANN相結合。 語音的能量來源于正常呼氣時肺部呼出的穩定氣流,喉部的聲帶既是閥門,又是振動部件。語音信號可以看作是一個時間序列,可以由隱馬爾可夫模型(HMM)進行表征。語音信號經過數字化及濾噪處理之后,進行端點檢測得到語音段。對語音段數據進行特征提取,語音信號就被轉換成為了一個向量序列,作為觀察值。在訓練過程中,觀察值用于估計HMM的參數。這些參數包括觀察值的概率密度函數,及其對應的狀態,狀態轉移概率等。當參數估計完成后,估計出的參數即用于識別。此時經過特征提取后的觀察值作為測試數據進行識別,由此進行識別準確率的結果統計。訓練及識別的結構框圖如圖1所示。
圖1 語音識別系統結構框圖
1. 1 端點檢測
找到語音信號的起止點,從而減小語音信號處理過程中的計算量,是語音識別過程中一個基本而且重要的問題。端點作為語音分割的重要特征,其準確性在很大程度上影響系統識別的性能。
能零積定義:一幀時間范圍內的信號能量與該段時間內信號過零率的乘積。
能零積門限檢測算法可以在不丟失語音信息的情況下,對語音進行準確的端點檢測,經過450個孤立詞(數字“0~9”)測試準確率為98%以上,經該方法進行語音分割后的語音,在進入識別模塊時識別正確率達95%。
圖2 檢測結果的效果示意圖 當話者帶有呼吸噪聲,或周圍環境出現持續時間較短能量較高的噪聲,或者持續時間長而能量較弱的噪聲時,能零積門限檢測算法就不能對這些噪聲進行濾除,進而被判作語音進入識別模塊,導致誤識。圖2(a)所示為室內環境,正常情況下采集到的帶有呼氣噪聲的數字“0~9”的語音信號,利用能零積門限檢測算法得到的效果示意圖。最前面一段信號為呼氣噪聲,之后為數字“0~9”的語音。
從圖2(a)直觀的顯示出能零積算法在對付能量較弱,但持續時間長的噪音無能為力。由此引出了雙門限能零積檢測算法。 所謂的雙門限能零積算法指的是進行兩次門限判斷。第一門限采用能零積,第二門限為單詞能零積平均值。也即在前面介紹的能零積檢測算法的基礎上再進行一次能零積平均值的判決。其中,第二門限的設定依據取決于所有實驗樣本中呼氣噪聲的平均能零積及最小的語音單詞能零積之間的一個常數。如圖2(b)所示,即為圖2(a)中所示的語音文件經過雙門限能零積檢測算法得到的檢測結果。可以明顯看到,最前一段信號,即呼氣噪聲已經被視為噪音濾除。
1.2 隱馬爾可夫模型HMM
隱馬爾可夫模型,即HMM是一種基于概率方法的模式匹配方法。它的應用是20世紀80年代以來語音識別領域取得的重要成果。
一個HMM模型可以表示為:
式中:π為初始狀態概率分布,πi=P(q1=θi),1≤i≤N,表示初始狀態處于θi的概率;A為狀態轉移概率矩陣,(aij)N×N,aij=P(qt+1 =θj|qt=θi),1≤i,j≤N;B為觀察值概率矩陣,B={bj(ot)},j=1,2,…,N,表示觀察值輸出概率分布,也就是觀察值ot處于狀態j的概率。
1.3 模型訓練
HMM有多種結構類型,并且有不同的分類方法。根據狀態轉移矩陣(A參數)和觀察值輸出矩陣(B參數)的不同有不同類型的HMM。
對于CHMM模型,當有多個觀察值序列時,其重估公式由參考文檔給出,此處不再贅述。
1.4 概率計算
利用HMM的定義可以得出P(O|λ)的直接求取公式:
式(2)計算量巨大,是不能接受的。Rabiner提出了前向后向算法,計算量大大減小。定義前向概率:
那么有 (1)初始化
(2)遞推
(3)終止
式(2)表示的是初始前向概率,bi(o1)為觀察值序列處于t=1 時刻在狀態i時的輸出概率,由于它服從連續高斯混合分布,故此值往往極小。根據大量實驗觀察,通常小于10-10,此值在定點DSP中已不能用Q格式表示。分析式(3)可以發現,隨著時間t的增加,還會有大量的小數之間的乘法加法運算,使得新的前向概率值at+1更小,逐漸趨向于0,定點DSP采用普通的Q格式進行計算時便會負溢出,即便不發生負溢出也會大大丟失精度。因此必須尋找一種解決方法,在不影響DSP實時性的前提下,既不發生負溢出,又能提高精度。
2 DSP實現語音識別
孤立詞語音識別一般采用DTW動態時間規整算法。連續語音識別一般采用HMM模型或者HMM與人工神經網絡ANN相結合。
為了能實時控制機器人,首先需要考慮的是能夠實現實時地語音識別。而考慮到CHMM的巨大計算量以及成本因素,采用了數據處理能力強大,成本相對較低的定點數字信號處理器,即定點DSP。本實驗采用的是TI公司多媒體芯片TMS320DM642。定點DSP要能準確、實時的實現語音識別,必須考慮2點問題:精度問題和實時性問題。
精度問題的產生原因已經由1.4節詳細闡述,這里不再贅述。因此必須找出一種可以提高精度,而又不會對實時性造成影響的解決方法。基于以上考慮,本文提出了一種動態指數定標方法。這種方法類似于科學計數法,用2個32 b單元,一個單元表示指數部分EXP,另一個單元表示小數部分Frac。首先將待計算的數據按照指數定標格式歸一化,再進行運算。這樣當數據進行運算時,仍然是定點進行,從而避開浮點算法,從而使精度可以達到要求。
對于實時性問題,通常,語音的頻率范圍大約是300~3 400 Hz左右,因而本實驗采樣率取8 kHz,16 b量化。考慮識別的實現,必須將語音進行分幀處理。研究表明,大約在10~30 ms內,人的發音模型是相對穩定的,所以本實驗中取32 ms為一幀,16 ms為幀移的時間間隔。
解決實時性問題必須充分利用DSP芯片的片上資源。利用EDMA進行音頻數據的搬移,提高CPU利用率。采用PING—PONG緩沖區進行數據的緩存,以保證不丟失數據。CHMM訓練的模板放于外部存儲器,由于外部存儲器較片內存儲器的速度更慢,因此開啟CACHE。建立DSP/BIOS任務,充分利用BIOS進行任務之間的調度,實時處理新到的語音數據,檢測語音的起止點,當有語音數據時再進入下一任務進行特征提取及識別。將識別結果用揚聲器播放,并送入到機器人的控制模塊。
實驗中,采用如圖3的程序架構。
圖3機器人識別軟件框圖
3 機器人控制
機器人由自然條件下的語句進行控制。這些語句描述了動作的方向,以及動作的幅度。為了簡單起見,讓機器人只執行簡單命令。由手機進行遙控,DSP模塊識別出語音命令,送控制命令到ARM模塊,驅動左右機械輪執行相應動作。
3.1 硬件結構
機器人的硬件結構如圖4所示。
圖4機器人硬件結構 機器人主要有2大模塊,一個是基于DSP的語音識別模塊;另一個是基于ARM的控制模塊,其機械足為兩滑輪。由語音識別模塊識別語音,由控制模塊控制機器人動作。
3.2 語音控制
首先根據需要,設置了如下幾個簡單命令:前、后、左、右。機器人各狀態之間的轉移關系如圖5所示。其中,等待狀態為默認狀態,當每次執行前后或左右轉命令后停止,即回到等待狀態,此時為靜止狀態。
圖5機器人狀態 語音的訓練模板庫由4個命令加10個阿拉伯數字共14個組成,如下所示。 命令:“前”、“后”、“左”、“右”; 數字:“0~9”。 命令代表動作的方向,數字代表動作的幅度。當執行前后命令時,數字的單位為dm,執行左右轉彎命令時,數字的單位為角度單位的20°。每句命令句法為命令+數字。例如,語音“左2”表示的含義為向左轉彎40°,“前4”表示向前直行4 dm。
機器人語音控制的關鍵在于語音識別的準確率。表1給出了5個男聲樣本的識別統計結果。
表1識別統計結果
4 結語
工作中,成功地將CHMM模型應用于定點DSP上,并實現了對機器人的語音控制。解決了CHMM模型巨大計算量及精度與實時性之間的矛盾。提出了一種新的端點檢測算法,對于對抗短時或較低能量的環境噪音具有明顯效果。同時需要指出的是,當語音識別指令增多時,則需要定義更多的句法,并且識別率也可能會相應降低,計算量也會相應變大。下一步研究工作應更注重提高大詞匯量時的識別率及其魯棒性。
-
神經網絡
+關注
關注
42文章
4779瀏覽量
101169 -
語音識別
+關注
關注
38文章
1742瀏覽量
112923 -
智能機器人
+關注
關注
17文章
872瀏覽量
82539
發布評論請先 登錄
相關推薦
SPCE061A語音識別機器人應用方案
會物體識別和語音識別的nao機器人
智能語音機器人
機器人語音需求
【 平頭哥CB5654語音開發板試用連載】智能取貨機器人語音交互模組
【 平頭哥CB5654語音開發板試用連載】人工智能機器人
設計一個能自由行走并且可以與人語音對話機器人的設計資料分享
智能機器人語音識別技術





 工商網監
工商網監
評論