 神經架構搜索詳解
神經架構搜索詳解
近期谷歌大腦團隊發布了一項新研究:只靠神經網絡架構搜索出的網絡,不訓練,不調參,就能直接執行任務。
這樣的網絡叫做WANN,權重不可知神經網絡。前一陣子在業內引起了不小轟動。
很多同學對其中的關鍵方法“神經網絡架構搜索(NAS)“表現出了極大興趣。那么什么是NAS呢?
谷歌CEO Sundar Pichai曾表示:“設計神經網絡非常耗時,需要具有專門背景知識的人,并且,對專業知識的高要求限制了創業公司和小的社區使用它。
而使用“神經網絡設計神經網絡”的方法被稱為神經結構搜索(NAS),通常使用強化學習或進化算法來設計新的神經網絡結構。
關于NAS,原理是什么?初學者又該如何入門?
圖靈君對下面這篇選自medium技術博客進行了編譯,該文章全面介紹NAS的原理和三種不同方法,希望大家有所幫助。
以下是博文內容:
我們大多數人可能都對ResNet耳熟能詳,它是ILSVRC 2015在圖像分類、檢測和本地化方面的贏家,也是MS COCO 2015檢測和分割的贏家。ResNet是一個巨大的架構,遍布各種跳躍連接。當我使用這個ResNet作為自己機器學習項目的預訓練網絡時,我想的是“怎么會有人提出這樣的體系結構呢?”'
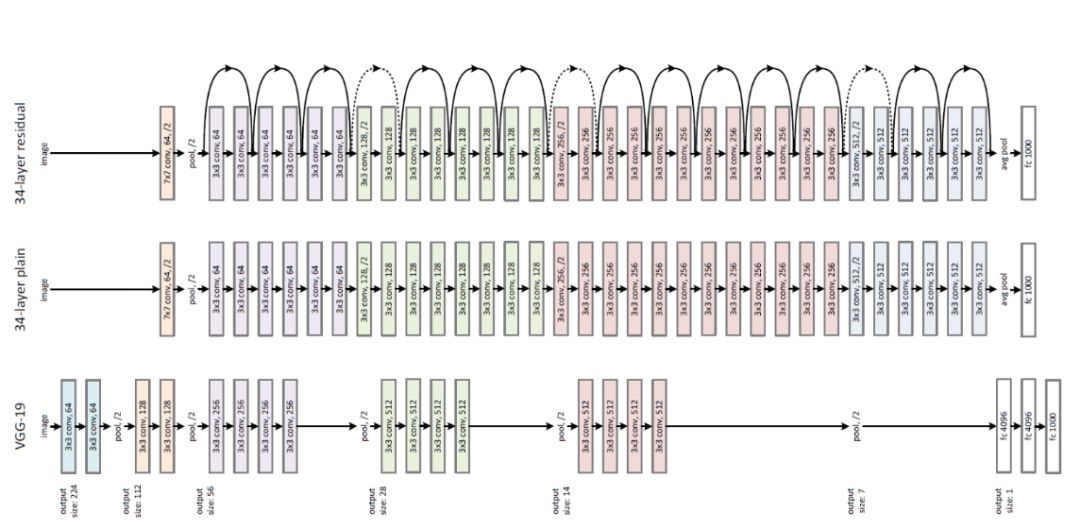
大型人類工程圖像分類體系機構
不久之后,我了解到許多工程師和科學家用他們多年的經驗構建了這種架構后。并且還有更多的直覺而不是完整的數學將告訴你“我們現在需要一個5x5過濾器以達到最佳精度”。我們有很好的圖像分類任務架構,但像我這樣的許多年輕學習者通常花費數小時的時間來修復體系結構,同時處理那些不是Image的數據集。我們當然希望別人能為我們做這件事。
因此神經架構搜索(NAS),自動化架構工程的過程就出現了。我們只需要為NAS系統提供數據集,它將為我們提供該數據集的最佳架構。NAS可以被視為AutoML的子域,并且與超參數優化具有明顯的重疊。要了解NAS,我們需要深入研究它在做什么。它通過遵循最大化性能的搜索策略,從所有可能的架構中找到架構。下圖總結了NAS算法。
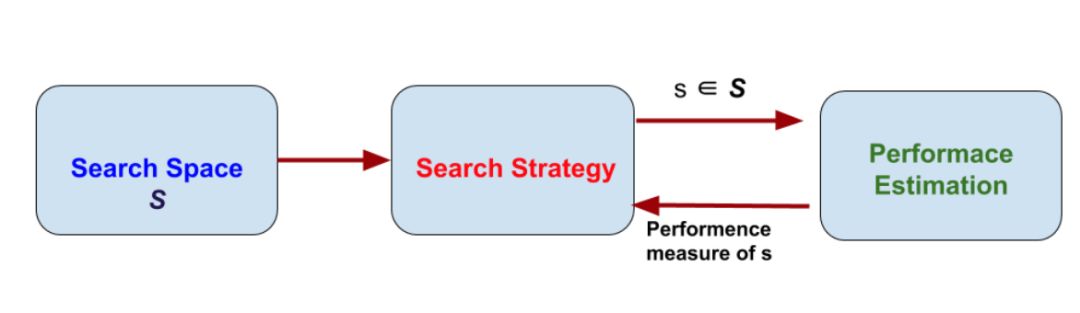
NAS方法的維度
它有3個獨立的維度:搜索空間、搜索策略和性能評估。
搜索空間定義了NAS方法原則上可能發現的神經架構。它可以是鏈狀結構,其中層(n-1)的輸出作為層(n)的輸入饋送。或者它可以是具有跳躍連接(多分支網絡)的現代復雜架構。
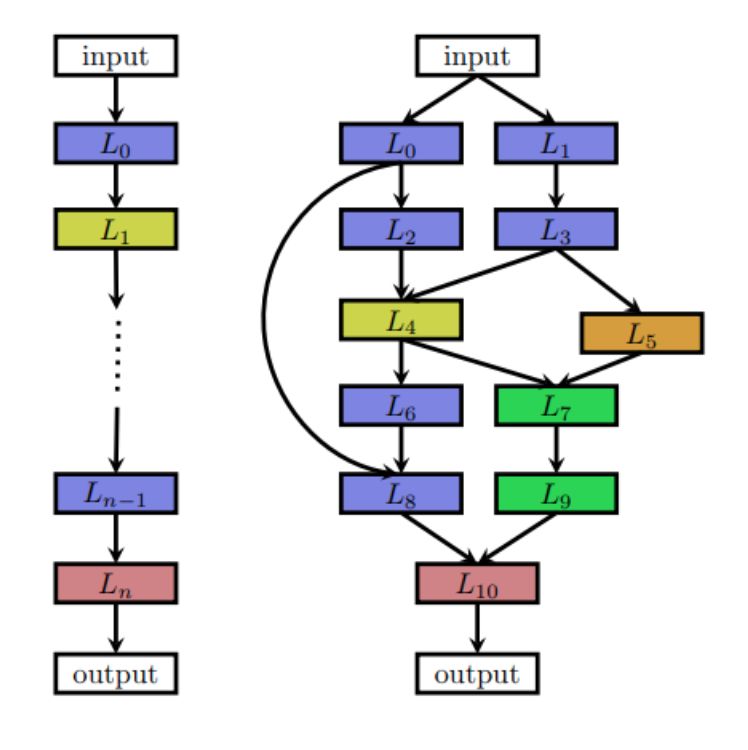
鏈狀網絡和多分支網絡
有時人們確實想要使用具有重復主題或單元的手工制作的外部架構(宏觀架構)。在這種情況下,外部結構是固定的,NAS僅搜索單元體系結構。這種類型的搜索稱為微搜索或單元搜索。
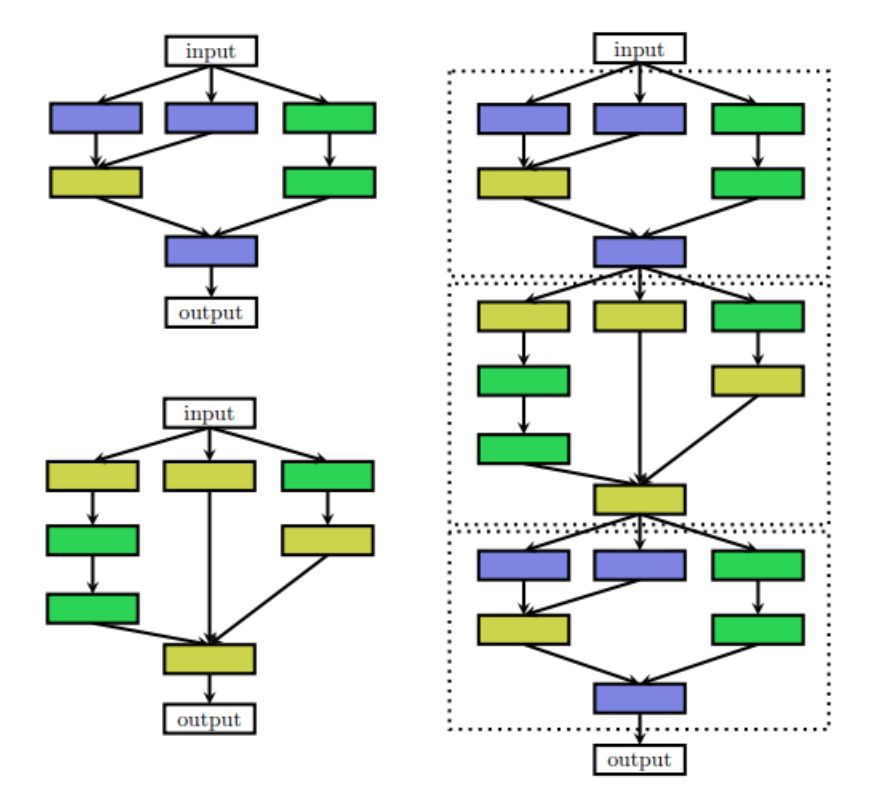
左:單元結構 右:單元放入手工制作的外部結構中
在許多NAS方法中,以分層方式搜索微觀和宏觀結構; 它由幾個層次的主題組成。第一級由原始操作組成,第二級是不同的主題,通過有向無環圖連接原始操作,第三級是編碼如何連接二級圖案的主題,依此類推。
為了解釋搜索策略和性能估計,下面將討論三種不同的NAS方法。
強化學習
我們了解強化學習; 其中根據θ參數化的一些策略執行某些操作。然后,代理從所采取的操作的獎勵更新策略θ。在NAS的情況下,代理生成模型體系結構,子網絡(動作)。然后在數據集上訓練模型,并將模型對驗證數據的性能作為獎勵。
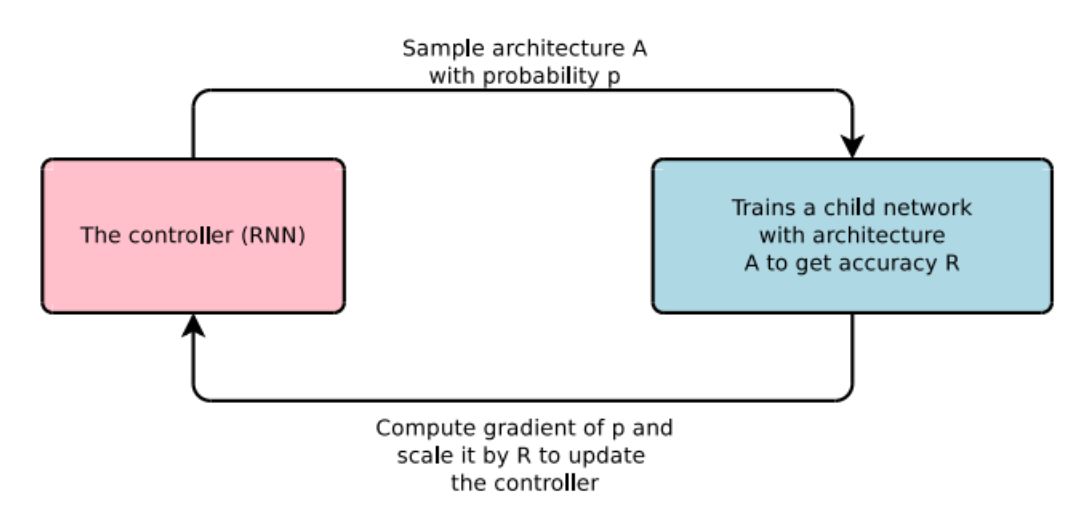
控制器扮演代理的角色,準確性被作為獎勵
通常,遞歸神經網絡(RNN)被視為控制器或代理。它產生字符串,模型是隨機構建的字符串形式。
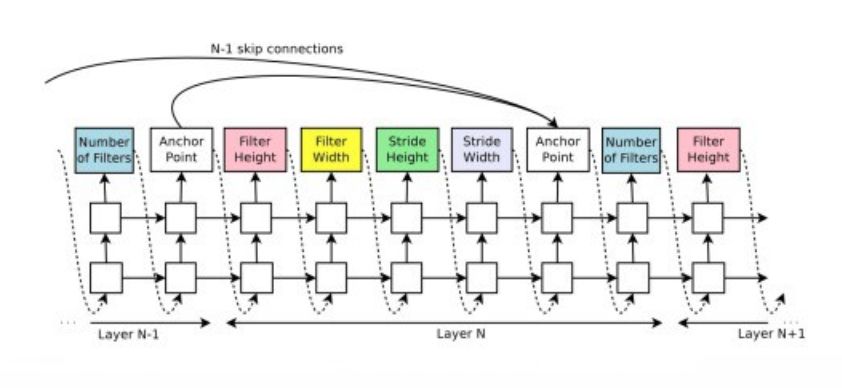
RNN用于創建模型的字符串示例
例如,在圖5中,連續的RNN輸出用于構建濾波器; 從過濾器高度開始到步寬。輸出錨點用于指示跳躍連接。在第N層,錨點將包含N-1個基于內容的sigmoids,以指示需要連接的先前層。
通過策略梯度方法訓練RNN以迭代地更新策略θ。這里省略了詳細的計算,可以在原始論文的第3.2節中找到。
論文地址:
https://openreview.net/pdf?id=r1Ue8Hcxg
漸進式神經架構搜索(PNAS)
PNAS執行本教程的搜索空間部分中討論的單元搜索。他們通過以預定義的方式添加單元來構建來自塊的單元并構建完整網絡。

單元以預定數量串聯連接以形成網絡。并且每個單元由幾個塊(原文中使用的5個)形成。

這些塊由預定義的操作組成。

塊的結構。組合函數只是逐元素相加
操作結果表明,圖中所示為原論文所使用的圖形,可以進行擴展。
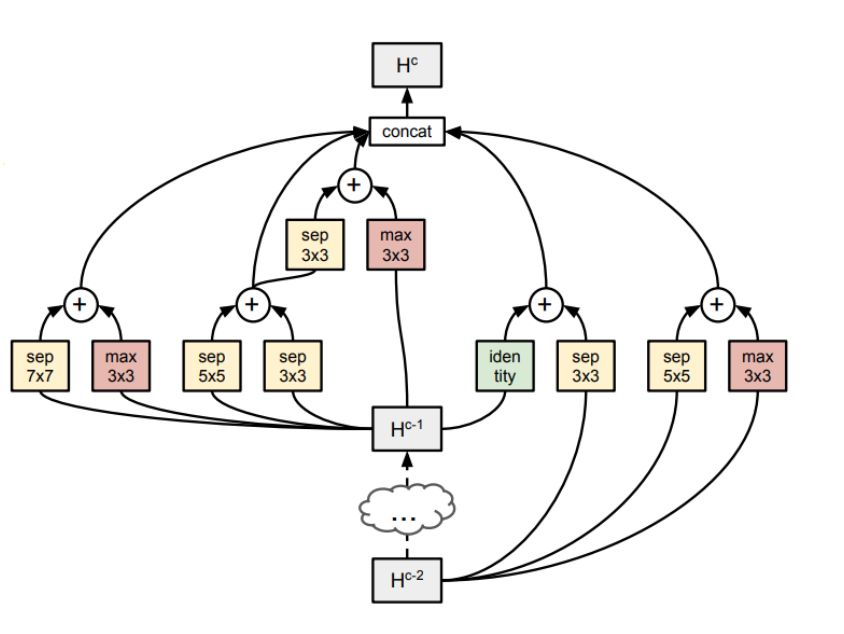
上圖顯示了完整的示例。即使在這種單元胞或微搜索中,也有101?個有效組合來檢查以找到最佳單元結構。
因此,為了降低復雜性,首先僅構建僅具有1個塊的單元。這很容易,因為通過上述操作,只有256個不同的單元是可能的。然后選擇頂部K表現最佳的單元以擴展2個塊單元,并重復最多5個塊。
但是,對于一個合理的K,太多的2塊候選來訓練。作為這個問題的解決方案,我們訓練了僅通過讀取字符串(單元被編碼成字符串)來預測最終性能的“廉價”代理模型。這種訓練的數據是在單元構建、訓練和驗證時收集的。
例如,我們可以構造所有256個單塊單元并測量它們的性能。并使用這些數據訓練代理模型。然后使用此模型預測2個塊單元的性能,而無需實際訓練和測試它們。當然,代理模型應該能夠處理可變大小的輸入。
然后選擇由模型預測的頂部K表現最佳的2個塊單元。然后對這2個塊單元進行實際訓練,對“替代”模型進行微調,并將這些單元擴展為3個塊并對其進行迭代
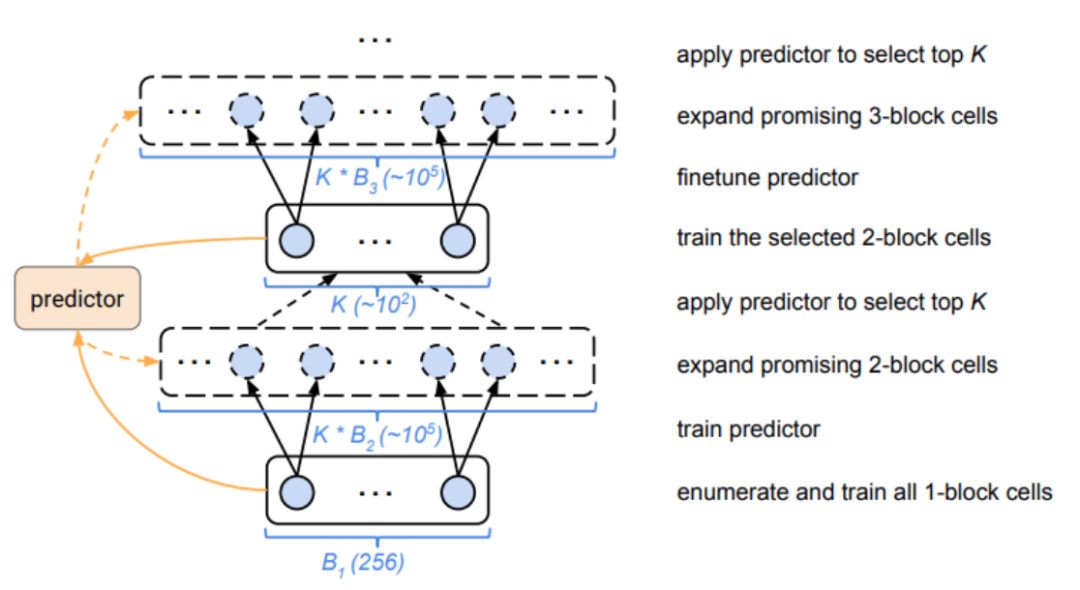
PNAS的步驟
差異化架構搜索(DARTS)
用于神經架構的搜索空間是離散的,即一種架構與另一種架構的不同之處至少在于該架構中有一層或一些參數,例如,5x5濾波器對7x7濾波器。在該方法中,采用連續松弛法進行離散搜索,以實現基于梯度的直接優化。
我們搜索的單元可以是有向無環圖,其中每個節點x是潛在表示(例如卷積網絡中的特征映射),并且每個有向邊(i,j)與某些操作o(i,j)相關聯( 卷積,最大池化等,轉換x(i)并在節點x(j)處存儲潛在表示。
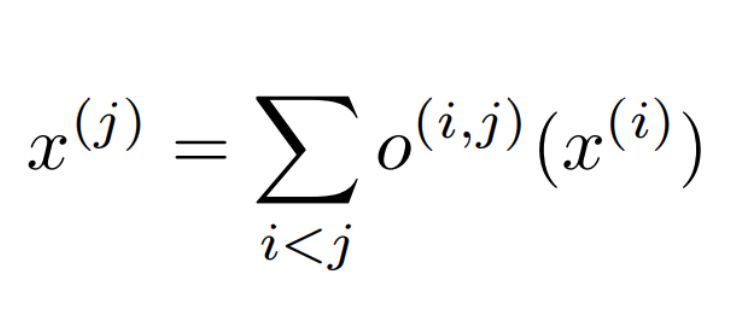
每個節點的輸出可以通過上述的等式計算。以這樣的方式枚舉節點,即從節點x(i)到x(j)存在邊(i,j),然后i
在連續松弛法中,不是在兩個節點之間進行單個操作。使用每種可能操作的凸組合。為了在圖中對此進行建模,保持兩個節點之間的多個邊緣,每個邊緣對應于特定操作。并且每個邊緣也具有權重α。
離散問題的連續松弛
現在O(i,j)節點x(i)和x(j)之間的操作是一組操作o(i,j)的凸組合,其中o(.)εS,其中S是所有的集合可能的操作。
O(i,j)的輸出由上述方程計算。
L_train和L_val分別表示訓練和驗證損失。兩種損失不僅由架構參數α確定,而且還由網絡中的權重“w”確定。架構搜索的目標是找到最小化驗證損失L_val(w *,α*)的α*,其中通過最小化訓練損失來獲得與架構相關聯的權重'w *'。
w?= argminL_train(w, α? ).
這意味著一個雙層優化問題,α作為上層變量,w作為下層變量:
α *= argminL_val(w ? (α), α)
s.t.w ? (α)= argminL_train(w, α)
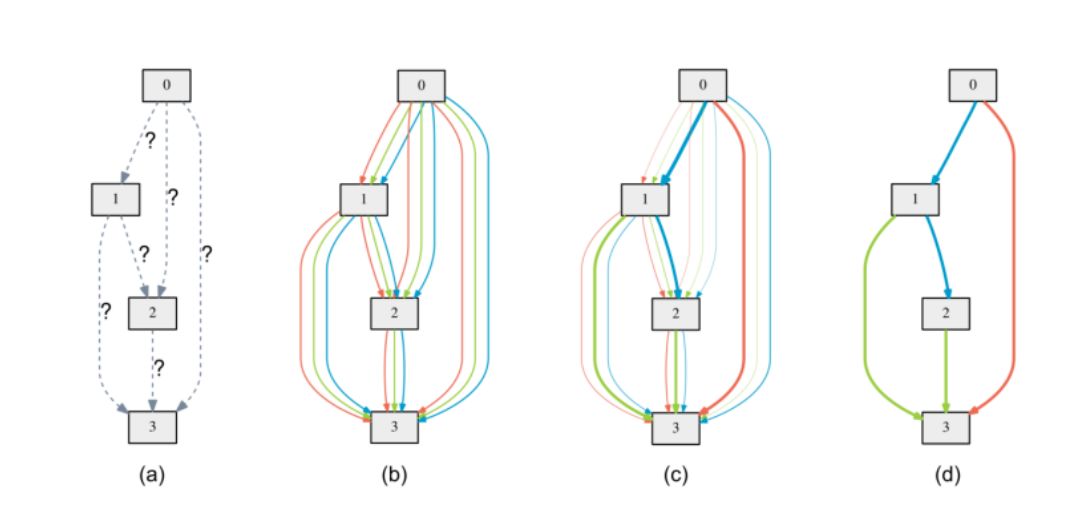
訓練后,某些邊的α變得比其他邊大得多。為了得到這個連續模型的離散架構,在兩個節點之間保留唯一具有最大權重的邊。
a)上的操作最初是未知的。b)通過在每個邊上放置候選操作的混合來連續放松搜索空間c)在雙層優化期間一些權重增加并且一些權重下降d)最終體系結構僅通過采用具有兩個節點之間的最大權重的邊來構建。
當找到單元時,這些單元然后用于構建更大的網絡。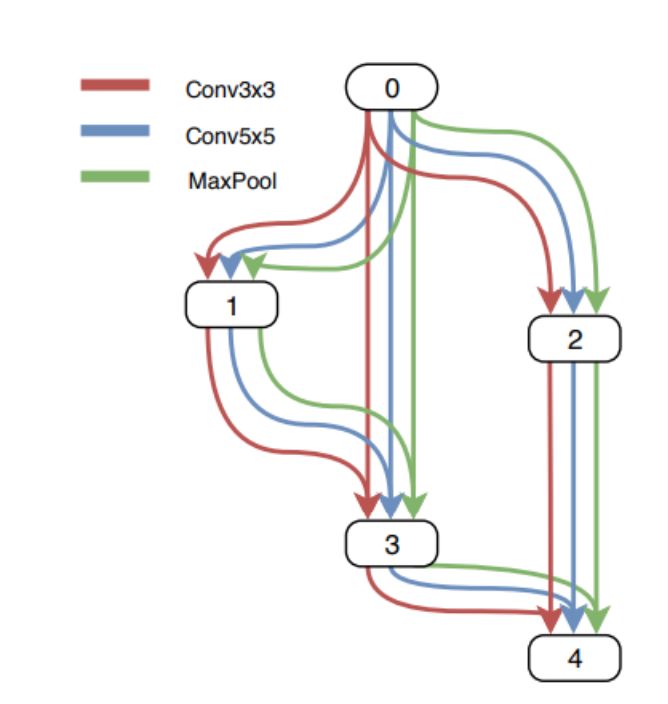

-
神經網絡
+關注
關注
42文章
4779瀏覽量
101171 -
NAS
+關注
關注
11文章
292瀏覽量
112621
原文標題:入門必備 | 一文讀懂神經架構搜索
文章出處:【微信號:rgznai100,微信公眾號:rgznai100】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
相關推薦
華人團隊打造專為GAN量身定制架構搜索方案AutoGAN
ARM Cortex-M系列芯片神經網絡推理庫CMSIS-NN詳解
OpenStack Swift架構詳解
關于Instgram的搜索架構簡要分析
什么是神經架構搜索?機器學習自動化真能普及大眾嗎?

一種新的高效神經架構搜索方法,解決了當前網絡變換方法的局限性
一種利用強化學習來設計mobile CNN模型的自動神經結構搜索方法
神經架構搜索的算法,可以使被AI優化過的AI設計過程加速240多倍
MIT研發“神經架構搜索”算法,將AI優化的AI設計過程加速240倍或更多
以進化算法為搜索策略實現神經架構搜索的方法





 工商網監
工商網監
評論