") 復(fù)合模型擴(kuò)展:一種更好的擴(kuò)展CNN的方法
復(fù)合模型擴(kuò)展:一種更好的擴(kuò)展CNN的方法
開(kāi)發(fā)一個(gè)卷積神經(jīng)網(wǎng)絡(luò)(CNN)的成本通常是固定的。在獲得更多資源時(shí),我們通常會(huì)按比例進(jìn)行擴(kuò)展,以便獲得更優(yōu)的準(zhǔn)確性。例如,ResNet可以通過(guò)增加層數(shù)從ResNet-18擴(kuò)展到ResNet-200,最近,GPipe 網(wǎng)絡(luò)通過(guò)將基準(zhǔn) CNN 模型擴(kuò)展四倍,在 ImageNet Top-1 上獲得了 84.3% 的準(zhǔn)確度。在模型擴(kuò)展方面的操作通常是任意增加 CNN 的深度或?qū)挾龋蛘咴诟筝斎雸D像分辨率上進(jìn)行訓(xùn)練和評(píng)估。雖然這些方法確實(shí)提高模型了準(zhǔn)確性,但它們通常需要繁瑣的手工調(diào)整,而且還不一定能找到最優(yōu)的結(jié)構(gòu)。換言之,我們是否能找到一種擴(kuò)展設(shè)計(jì)方法來(lái)獲得更好的準(zhǔn)確性和效率呢?
在 Google 的 ICML 2019 論文“EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks”中,作者提出了一種新的模型尺度縮放方法,該方法使用簡(jiǎn)單且高效的復(fù)合系數(shù)以更結(jié)構(gòu)化的方式來(lái)擴(kuò)展 CNN。 與任意縮放網(wǎng)絡(luò)尺寸的傳統(tǒng)方法(例如寬度、深度和分辨率)不同,本文使用一個(gè)固定的縮放系數(shù)集合,均勻地縮放每個(gè)維度。 借助這種新的縮放方法和在AutoML 方面的最新進(jìn)展,Google 開(kāi)發(fā)了一系列稱為 EfficientNets 的模型,它超越了 SOTA 的精度,并且將效率提高了10倍(更小、更快)。
復(fù)合模型擴(kuò)展:一種更好的擴(kuò)展 CNN 的方法
為了理解擴(kuò)展網(wǎng)絡(luò)的效果,本文系統(tǒng)地研究了擴(kuò)展模型不同維度帶來(lái)的影響。雖然擴(kuò)展各個(gè)維度可以提高模型性能,但作者觀察到,平衡網(wǎng)絡(luò)寬度、深度和輸入圖像大小這些維度比增加計(jì)算資源,可以更好地提高整體性能。
復(fù)合擴(kuò)展方法的第一步是執(zhí)行網(wǎng)格搜索,用來(lái)找到在固定資源下基準(zhǔn)網(wǎng)絡(luò)不同擴(kuò)展維度之間的關(guān)系。這決定了上文提到的每個(gè)維度的縮放系數(shù)。然后,作者用這些系數(shù)將基準(zhǔn)網(wǎng)絡(luò)擴(kuò)展到所需的目標(biāo)模型大小或預(yù)算的計(jì)算力。
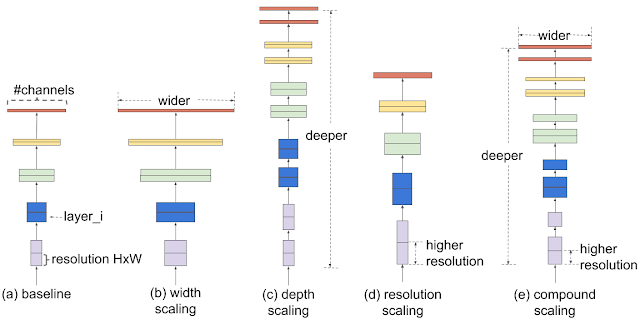
不同縮放方法的比較。 與傳統(tǒng)僅縮放單個(gè)維度的方法(b)-(d)不同,我們的復(fù)合縮放方法以某種方式統(tǒng)一擴(kuò)展所有維度。
與傳統(tǒng)的縮放方法相比,這種復(fù)合縮放方法可以用于提高多個(gè)模型的準(zhǔn)確性和效率,如MobileNet(+ 1.4%圖像網(wǎng)精度)和ResNet(+ 0.7%)。
高效的網(wǎng)絡(luò)架構(gòu)
模型縮放的有效性也在很大程度上依賴于基準(zhǔn)網(wǎng)絡(luò)。 因此,為了進(jìn)一步提高性能,作者使用了 AutoML MNAS 框架(該框架在準(zhǔn)確性和效率上都做了優(yōu)化),利用神經(jīng)架構(gòu)搜索來(lái)開(kāi)發(fā)新的基準(zhǔn)網(wǎng)絡(luò)。 由此產(chǎn)生的架構(gòu)使用了移動(dòng)端的逆向 bottleneck 卷積(MBConv),類似于 MobileNetV2 和 MnasNet,但由于有更多的 FLOP 預(yù)算,因此結(jié)構(gòu)略大。最終,作者擴(kuò)展了這個(gè)基準(zhǔn)網(wǎng)絡(luò)以獲得一系列模型,稱為 EfficientNets。
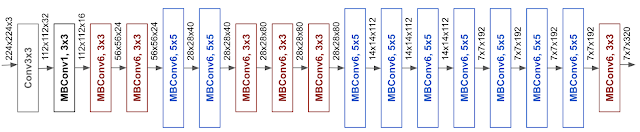
本文的基準(zhǔn)網(wǎng)絡(luò) EfficientNet-B0,其架構(gòu)簡(jiǎn)單干凈,便于擴(kuò)展。
EfficientNet 網(wǎng)絡(luò)的性能
文中將 EfficientNets 與 ImageNet 上其他現(xiàn)有的 CNN 進(jìn)行了比較。 總的來(lái)說(shuō),EfficientNet 模型實(shí)現(xiàn)了比現(xiàn)有 CNN 更高的精度和更高的效率,將參數(shù)大小和 FLOPS 降低了一個(gè)數(shù)量級(jí)。 例如,在高精度下,EfficientNet-B7 在 ImageNet 上達(dá)到了 SOTA 的Top-1,84.4% 的準(zhǔn)確率與 Top-5 97.1% 的準(zhǔn)確率,同時(shí)在 CPU 上的開(kāi)銷比之前的 Gpipe 小 8.4 倍和 6.1 倍。與廣泛使用的 ResNet-50 相比,EfficientNet-B4 在保持相同 FLOPS 開(kāi)銷情況下,將 Top-1 的精度從ResNet-50 的 76.3% 提高到 82.6%(+ 6.3%)。
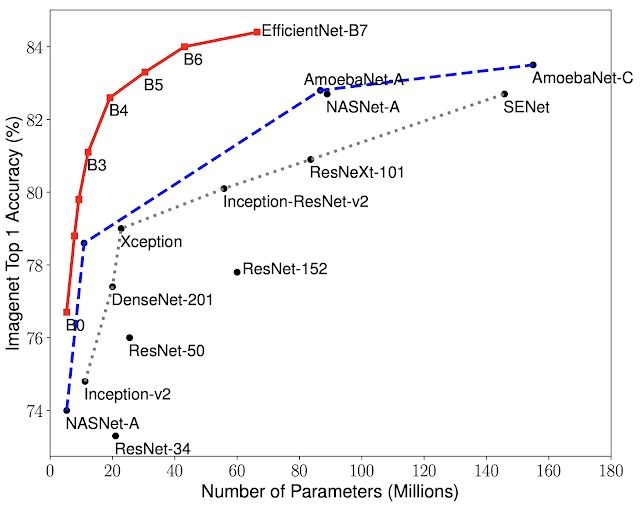
模型尺寸與精度比較。 EfficientNet-B0 是由 AutoML MNAS 開(kāi)發(fā)的基準(zhǔn)網(wǎng)絡(luò),而 Efficient-B1 到 B7 是通過(guò)擴(kuò)展基準(zhǔn)網(wǎng)絡(luò)得到。特別是,EfficientNet-B7 實(shí)現(xiàn)了 SOTA 的 Top-1,84.4% 準(zhǔn)確率與 Top-5,97.1% 的準(zhǔn)確率,同時(shí)比現(xiàn)有最佳的 CNN 小 8.4 倍。
盡管 EfficientNets 在 ImageNet 上表現(xiàn)較好,但為了驗(yàn)證它的泛化能力,也應(yīng)該在其他數(shù)據(jù)集上進(jìn)行測(cè)試。 為了評(píng)估這一點(diǎn),作者在八個(gè)廣泛使用的遷移學(xué)習(xí)數(shù)據(jù)集上測(cè)試了EfficientNets。EfficientNets 在 8 個(gè)數(shù)據(jù)集中的 5 個(gè)中實(shí)現(xiàn)了 SOTA 的精度,例如 CIFAR-100(91.7%)和 Flowers(98.8%),模型參數(shù)減少了一個(gè)數(shù)量級(jí)(減少了21倍),這表明EfficientNets 也能很好的進(jìn)行遷移。
由于 EfficientNets 顯著提高了模型效率,作者預(yù)計(jì)它可能在未來(lái)會(huì)成為計(jì)算機(jī)視覺(jué)任務(wù)的新基礎(chǔ)。 因此,作者開(kāi)源了所有 EfficientNet 模型。
-
cpu
+關(guān)注
關(guān)注
68文章
10902瀏覽量
213000 -
神經(jīng)網(wǎng)絡(luò)
+關(guān)注
關(guān)注
42文章
4779瀏覽量
101166 -
cnn
+關(guān)注
關(guān)注
3文章
353瀏覽量
22334
原文標(biāo)題:谷歌開(kāi)源新模型EfficientNet,或成計(jì)算機(jī)視覺(jué)任務(wù)新基礎(chǔ)
文章出處:【微信號(hào):rgznai100,微信公眾號(hào):rgznai100】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
請(qǐng)問(wèn)這兩種機(jī)械手模型哪種實(shí)驗(yàn)性能更好,可擴(kuò)展性更好
一種高分辨力角位移傳感器量程擴(kuò)展方法
一種新型可擴(kuò)展的多級(jí)多平面分組交換結(jié)構(gòu)的圖論模型與性能分析
一種復(fù)合故障預(yù)測(cè)動(dòng)態(tài)建模方法
一種改進(jìn)的基于偽相關(guān)反饋的查詢擴(kuò)展
用純軟件擴(kuò)展單片機(jī)串行口的一種方法
系統(tǒng)中多普勒頻移容限擴(kuò)展的一種方法
一種嵌入式手持設(shè)備的無(wú)線數(shù)據(jù)通信模塊擴(kuò)展方法
一種基于DSP的多核SOC中斷擴(kuò)展設(shè)計(jì)與實(shí)現(xiàn)
一種擴(kuò)展的基于角色的訪問(wèn)控制ERBAC模型
語(yǔ)音帶寬擴(kuò)展的激勵(lì)分段擴(kuò)展方法
基于語(yǔ)義向量表示的查詢擴(kuò)展方法的應(yīng)用設(shè)計(jì)
一種利用強(qiáng)化學(xué)習(xí)來(lái)設(shè)計(jì)mobile CNN模型的自動(dòng)神經(jīng)結(jié)構(gòu)搜索方法
基于擴(kuò)展狀態(tài)空間模型和擴(kuò)展非最小狀態(tài)空間模型的方法電子書(shū)免費(fèi)下載





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論