 電子發燒友App
電子發燒友App


我們已經到了需要為 4 位 HRRG 計算機定義匯編語言的地步,但首先我們需要考慮某些概念。
如今,我們習慣于使用 C/C++、Java、Python 等高級語言對我們的計算機和微控制器進行編程,但生活并不總是那么容易。第一批計算機程序員用機器代碼(處理器本身使用的數值)捕獲他們的程序。由于這太痛苦了,他們很快將抽象階梯向上移動到匯編語言。
另請參閱此索引,其中列出了構成我們的 4 位 HRRG 計算機項目的所有文章,以及一些有趣的相關專欄。
我們必須做的一件事是為我們的 4 位 HRRG 計算機定義這樣一種匯編語言,但在我們滿懷熱情地投入戰斗之前,我們需要先介紹幾個概念。
Big-endian 與 little-endian
當現實世界的計算機使用多個字節來表示數據值或內存地址時,將這些字節存儲在內存中的主要技術有兩種:要么將最高有效字節 (MSB) 存儲在具有最低地址的位置,在這種情況下,我們可以說它是“大端優先”存儲的,或者最低有效字節 (LSB) 存儲在最低地址中,在這種情況下,我們可以說它是“小端優先”存儲的以終為先。”
讓我們在 HRRG 計算機的上下文中考慮這兩種機制,它具有 4 位(1-nybble)數據總線和 12 位(3-nybble)地址總線,通過可視化我們如何在內存中存儲 3-nybble 值 $426 開始在內存位置 $100 如下圖所示:
HRRG 采用大端方法。當然,您可能不會對此感到驚訝——由于各種超出這些討論范圍的技術原因——一些計算機設計師偏愛一種風格,而另一些則采取相反的策略。直到人們開始對創建異構計算環境產生興趣,在該環境中將多臺不同的機器連接在一起以便文件可以在它們之間傳輸,這才真正重要,在這一點上,許多激烈的爭接踵而至。
1980 年,丹尼·科恩 (Danny Cohen) 撰寫的一篇著名論文《論圣戰與和平懇求》使用術語big-endian和little-endian來指代存儲數據的兩種技術。這些至今仍在使用的術語源自盎格魯-愛爾蘭諷刺作家喬納森·斯威夫特所著的《格列佛游記》一書。little-endian 和 big-endian 的綽號來自這個故事的一部分,即兩個國家就應該先吃煮雞蛋的哪一端——小端還是大端——而發生戰爭!
如果你想知道的偶然機會,斯威夫特在 1726 年寫下了他的偉大作品,那是在發明臺球桿之前的 9 年(在此之前,球員過去常常用小釘頭錘擊球)。
尋址模式
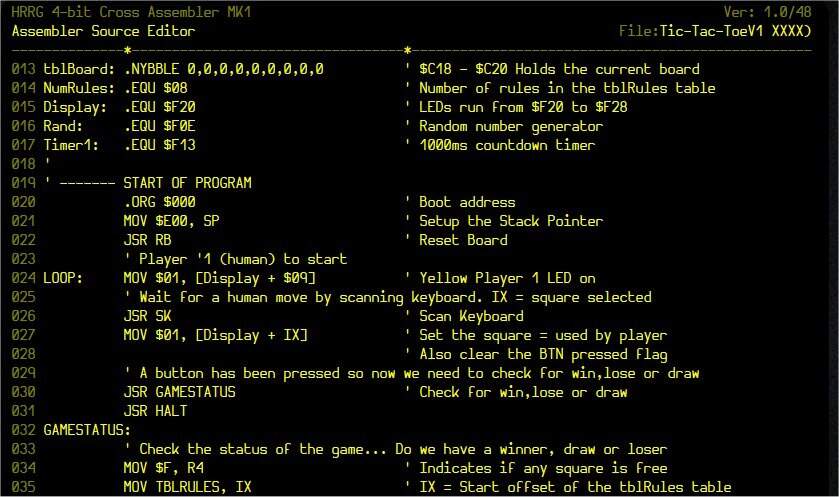
術語尋址模式是指指定指令操作數的方式。這些小流氓有無數不同的名稱和口味,因此以下內容應視為僅代表一個概述。
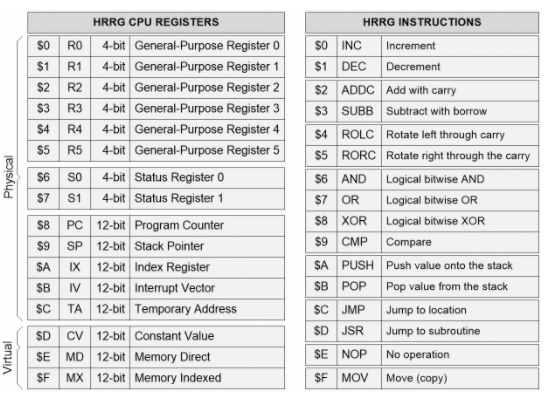
出于這些討論的目的,我們將假設 HRRG 型架構具有 4 位(1-nybble)數據總線和 12 位(3-nybble)地址總線。但是,下面介紹的寄存器和指令助記符是虛構的,僅用于這些審議。
隱含(又名隱含):在隱含(有時稱為隱含)尋址模式的情況下,目標是由指令本身隱含的。例如,假設我們有一個名為 Q 的寄存器和一個名為 INCQ 的指令,其目的是增加(加 1 到)寄存器 Q 的內容。在這種情況下,我們將只有一個沒有操作數的 INCQ 操作碼,如圖所示以下:
假設程序計數器 (PC) 從地址 $100 開始,CPU 將讀取并執行隱含的操作碼。我們最終將 PC 指向地址 $101,這是 CPU 期望在程序中找到下一個操作碼的地方。
立即:在立即尋址模式的情況下,數據立即出現在操作碼之后。例如,假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用立即尋址模式將 nybble 數據加載到寄存器 Q 中,如下所示:
假設程序計數器(PC)從地址 $100 開始,CPU 讀取操作碼,實現此操作碼使用立即模式,并將數據 nybble(本例中為 $F)加載到 Q 寄存器中。我們最終將 PC 指向地址 $102,這是 CPU 期望在程序中找到下一個操作碼的地方。
相對:在相對尋址模式的情況下,目標地址被指定為相對于程序計數器 (PC) 中當前值的偏移量。這樣的偏移量將被視為可以表示正值和負值的有符號二進制數。
假設我們的偏移量表示為 2-nybble 值。由于 2-nybble 字段可以表示 -128 到 +127 范圍內的有符號數,這意味著偏移量可以指向當前 PC 值之前的 128 個位置(即較低的內存地址)和之后的127 個位置之間的某個內存位置。當前 PC 值(即更高的內存地址)。
純粹出于與此處所示其他示例相關的示例的考慮,假設我們有一個名為Q的寄存器和一個稱為LDQ的指令,其目的是使用相對尋址模式將一個nyble數據加載到寄存器Q中(雖然我們使用的是相同的助記符,但該LDQ的操作碼與我們在上一個示例中討論的LDQ指令不同)。此外,假設偏移值為$08(十進制+8),如下所示:
假設程序計數器(PC)從地址$100開始,CPU讀取操作碼,實現其使用相對模式,并將包含偏移值的以下兩個nyble復制到內部(臨時)寄存器中。
接下來,它將偏移值添加到PC中的當前值,并使用結果指向包含數據nyble的位置。最后,它將該數據值(本例中為F)加載到Q寄存器中。最后,PC指向地址$103,CPU期望在該地址找到程序中的下一個操作碼。
純粹出于完整性考慮,讓我們考慮第二個相對尋址示例,其中偏移值為$F8(十進制中為-8),如下所示:
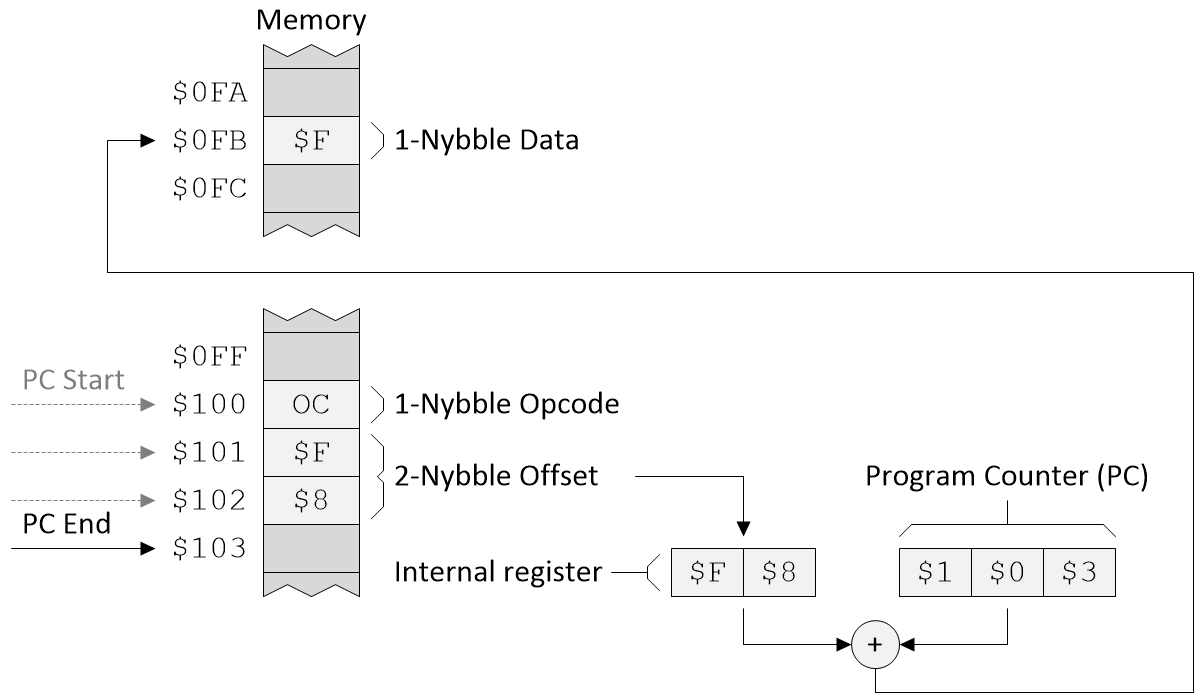
具有負偏移值的相對尋址模式。(來源:Max Maxfield)
需要注意的是,除了如上所示的數據操作指令外,還可以使用相對尋址來執行跳轉或分支指令。
當然,并非所有處理器都支持所有類型指令的所有尋址模式。例如,正如我們在之前的專欄中所討論的,6502 微處理器有一個 8 位數據總線和一個 16 位地址總線。在其 JMP(“無條件跳轉”)指令的情況下,6502 僅支持使用 16 位(2 字節)地址的絕對和間接尋址(下面介紹絕對和間接模式)。但是,6502 還支持一套使用 8 位(1 字節)相對地址的分支指令。正如我在該專欄中指出的那樣:
程序往往會進行大量跳轉——例如循環循環——因此在時鐘有限的日子里,使用 1 字節的分支地址而不是 2 字節的跳轉地址可能會顯著節省空間和時間速度、處理器周期和內存位置。
Zilog Z80 微處理器不支持相對尋址,您必須使用 Intel 8086 才能更好地查看使用相對尋址模式的“短跳轉”指令。
最后一點,我們在上面的討論中多次使用短語“PC 中的當前值”來說明要添加偏移量的值。當“迫在眉睫”時,我們使用了 103 美元的值,這是下一個操作碼的地址。為什么我們使用這個值?使用 $100(原始操作碼的地址)或 $102(偏移量中第二個 nybble 的地址)不是更有意義嗎?
好吧,假設我們正在執行某種形式的分支指令,而不是執行我們想象的 LDQ 指令。現在考慮如果偏移值為 0 美元會發生什么。如果偏移量是從 $100 處的分支指令操作碼的地址開始的,那么如果執行分支,$0 的偏移量將導致無限循環。或者,如果偏移量來自地址 $102 處操作數的第二個 nybble,那么 $0 的偏移量會導致 CPU 將操作數的第二個 nybble 誤解為操作碼。歸根結底,如果偏移量為 0 美元,那么在我們的原始指令之后立即分支到操作碼是有意義的;因此,我們使用下一個操作碼的地址作為“PC 中的當前值”。
只是為了確認這一切,因為它在我能看到的任何地方都沒有得到很好的記錄,所以我請我的新朋友,基于 6502 的虛擬現實系統的創建者 Nick Bild提供經驗證明。為此,Nick 創建了如下所示的小型 6502 匯編程序:
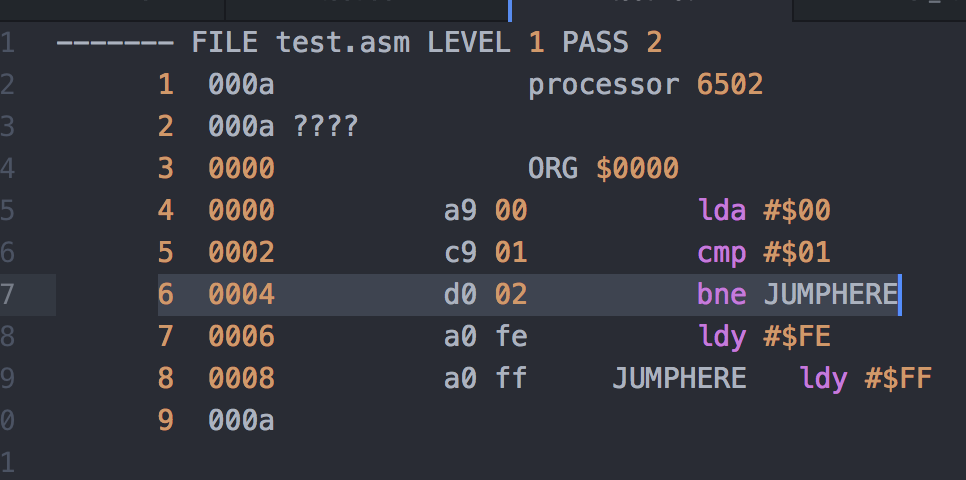
6502 組裝程序(來源:Nick Bild)
請記住,6502 有一個 8 位數據總線和一個 16 位地址總線。觀察地址 $0004 處的 BNE(“如果不相等則分支”)指令。如果滿足分支條件,則該指令將分支到地址 $0008 處的 JUMPHERE 標簽。現在觀察匯編程序生成并存儲在地址 $0005 中的偏移值是 $02。當然,$0008 – $02 = $0006,也就是 LDY(“加載索引寄存器 Y”)指令的地址;也就是說,緊跟在 BNE 指令之后的操作碼。量子點
絕對(又名直接):在絕對(有時稱為直接)尋址模式的情況下,目標地址立即出現在操作碼之后。例如,假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用絕對尋址模式將 nybble 數據加載到寄存器 Q 中,如下所示(再一次,雖然我們使用相同的助記符,但這個 LDQ與我們在前面的例子中討論的 LDQ 指令有不同的操作碼):
假設程序計數器(PC)從地址 $100 開始,CPU 讀取操作碼,實現此操作碼使用絕對模式,并將以下三個半字節(本例中為 $426)加載到內部寄存器中。然后 CPU 使用這個內部寄存器的內容來指向內存中的數據 nybble(在這個例子中是 $F),它加載到 Q 寄存器中。我們最終將 PC 指向地址 $104,這是 CPU 期望在程序中找到下一個操作碼的地方。
與我們想象的 LDQ 指令相反,假設地址 $100 處的操作碼指示 CPU 使用絕對尋址模式執行無條件 JMP。在這種情況下,CPU 將跳轉(設置 PC)到地址 $426。
間接:這是事情開始變得有趣的地方。假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用如下所示的間接尋址模式將 nybble 數據加載到寄存器 Q 中:
至于絕對模式,操作碼后面的三個半字節包含一個地址,該地址被加載到內部寄存器中。然而,在這種情況下,地址并不直接指向數據,而是指向另一個 3 nybble 地址的第一個 nybble,而正是這個第二個地址用于指向數據。
與我們想象的 LDQ 指令相反,假設地址 $100 處的操作碼指示 CPU 使用間接尋址模式執行無條件 JMP。在這種情況下,CPU 最終會跳轉(設置 PC)到地址 $971。
索引(又名絕對索引):此模式與絕對模式非常相似,不同之處在于它還涉及索引 (X) 寄存器。假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用索引尋址模式將 nybble 數據加載到寄存器 Q 中,如下所示:
假設程序計數器 (PC) 從地址 $100 開始,CPU 讀取操作碼,實現此操作碼使用索引模式,并將以下三個半字節(本例中為 $426)加載到內部寄存器中。然后 CPU 將此內部寄存器的內容添加到索引 (X) 寄存器的內容中,并使用結果指向內存中的數據 nybble(本例中為 $F),然后將其加載到 Q 寄存器中。我們最終將 PC 指向地址 $104,這是 CPU 期望在程序中找到下一個操作碼的地方。
與我們想象的 LDQ 指令相反,假設地址 $100 處的操作碼指示 CPU 使用索引尋址模式執行無條件 JMP。在這種情況下,CPU 最終會跳轉(設置 PC)到 549 美元的地址。
索引間接:此模式反映了索引和間接模式的一種可能組合。假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用索引間接尋址模式將 nybble 數據加載到寄存器 Q 中,如下所示:
假設程序計數器(PC)從地址 $100 開始,CPU 讀取操作碼,實現此操作碼使用索引間接模式,并將以下三個半字節(本例中為 $426)加載到內部寄存器中。然后 CPU 將此內部寄存器的內容添加到索引 (X) 寄存器的內容中以生成新地址。然而,在這種情況下,新地址并不直接指向數據,而是指向另一個 3 nybble 地址的第一個 nybble,而第二個地址用于指向將要加載到Q 寄存器。
與我們想象的 LDQ 指令相反,假設地址 $100 處的操作碼指示 CPU 使用索引間接尋址模式執行無條件 JMP。在這種情況下,CPU 最終會跳轉(設置 PC)到 738 美元的地址。
間接索引:此模式反映了索引模式和間接模式的替代組合。假設我們有一個名為 Q 的寄存器和一個名為 LDQ 的指令,其目的是使用間接索引尋址模式將 nybble 數據加載到寄存器 Q 中,如下所示:
假設程序計數器(PC)從地址 $100 開始,CPU 讀取操作碼,實現此操作碼使用間接索引模式,并將以下三個半字節(本例中為 $426)加載到內部寄存器中。該地址指向另一個 3 nybble 地址的第一個 nybble,該地址本身被復制到內部寄存器中。然后 CPU 將第二個內部寄存器的內容添加到索引 (X) 寄存器的內容中,以生成一個新地址,該地址指向將加載到 Q 寄存器中的數據。
與我們想象的 LDQ 指令相反,假設地址 $100 處的操作碼指示 CPU 使用間接索引尋址模式執行無條件 JMP。在這種情況下,CPU 最終會跳轉(設置 PC)到地址 $BD4。
Autoincrement 和 Autodecrement:除了上面討論的基本索引模式之外,一些 CPU 還支持 autoincrement 和 autodecrement 版本,其中索引寄存器在其內容添加到臨時寄存器中的地址后遞增或遞減。
事實上,由于增量/減量發生在加法之后,這些模式應該更恰當地稱為“后自動增量”和“后自動減量”。這是因為一些處理器還支持“pre-autoincrement”和“pre-autodecrement”,其中索引寄存器在其內容添加到臨時寄存器中的地址之前遞增或遞減。
另請注意,所有四種自動增量和自動減量都可以潛在地應用于索引間接和間接索引模式。
我的天啊!真的嗎?
我知道當我們考慮上面討論的所有可能的尋址模式時,有很多事情需要考慮。不要恐慌!HRRG 僅支持這些模式的一個子集,以及最簡單的模式——即隱含、立即、絕對和索引模式。
另一方面,我們構建 HRRG 的方式意味著它有時會在同一指令中使用多種模式。我能說什么?這是一個有趣的舊世界。
在我的下一篇專欄中,我們將開始匯總我們在寄存器和指令集專欄、指令集權衡專欄以及本專欄中介紹的所有內容,以描述 HRRG 的匯編語言和匯編程序實用程序。在此之前,我一如既往地歡迎您提出意見、問題和建議。
審核編輯 黃昊宇











 工商網監
工商網監
評論