 電子發燒友App
電子發燒友App


Hadoop 由許多元素構成。其最底部是 Hadoop Distributed File System(HDFS),它存儲 Hadoop 集群中所有存儲節點上的文件。HDFS(對于本文)的上一層是MapReduce 引擎,該引擎由 JobTrackers 和 TaskTrackers 組成。通過對Hadoop分布式計算平臺最核心的分布式文件系統HDFS、MapReduce處理過程,以及數據倉庫工具Hive和分布式數據庫Hbase的介紹,基本涵蓋了Hadoop分布式平臺的所有技術核心。
Hadoop 設計之初的目標就定位于高可靠性、高可拓展性、高容錯性和高效性,正是這些設計上與生俱來的優點,才使得Hadoop 一出現就受到眾多大公司的青睞,同時也引起了研究界的普遍關注。到目前為止,Hadoop 技術在互聯網領域已經得到了廣泛的運用,例如,Yahoo 使用4 000 個節點的Hadoop集群來支持廣告系統和Web 搜索的研究;Facebook 使用1 000 個節點的集群運行Hadoop,存儲日志數據,支持其上的數據分析和機器學習;
百度用Hadoop處理每周200TB 的數據,從而進行搜索日志分析和網頁數據挖掘工作;中國移動研究院基于Hadoop 開發了“大云”(Big Cloud)系統,不但用于相關數據分析,還對外提供服務;淘寶的Hadoop 系統用于存儲并處理電子商務交易的相關數據。國內的高校和科研院所基于Hadoop 在數據存儲、資源管理、作業調度、性能優化、系統高可用性和安全性方面進行研究,相關研究成果多以開源形式貢獻給Hadoop 社區。
除了上述大型企業將Hadoop 技術運用在自身的服務中外,一些提供Hadoop 解決方案的商業型公司也紛紛跟進,利用自身技術對Hadoop 進行優化、改進、二次開發等,然后以公司自有產品形式對外提供Hadoop 的商業服務。比較知名的有創辦于2008 年的Cloudera 公司,它是一家專業從事基于ApacheHadoop 的數據管理軟件銷售和服務的公司,它希望充當大數據領域中類似RedHat 在Linux 世界中的角色。
該公司基于Apache Hadoop 發行了相應的商業版本Cloudera Enterprise,它還提供Hadoop 相關的支持、咨詢、培訓等服務。在2009 年,Cloudera 聘請了Doug Cutting(Hadoop 的創始人)擔任公司的首席架構師,從而更加加強了Cloudera 公司在Hadoop 生態系統中的影響和地位。最近,Oracle 也表示已經將Cloudera 的Hadoop 發行版和Cloudera Manager 整合到Oracle Big Data Appliance 中。同樣,Intel 也基于Hadoop 發行了自己的版本IDH。從這些可以看出,越來越多的企業將Hadoop 技術作為進入大數據領域的必備技術。
需要說明的是,Hadoop 技術雖然已經被廣泛應用,但是該技術無論在功能上還是在穩定性等方面還有待進一步完善,所以還在不斷開發和不斷升級維護的過程中,新的功能也在不斷地被添加和引入,讀者可以關注Apache Hadoop的官方網站了解最新的信息。得益于如此多廠商和開源社區的大力支持,相信在不久的將來,Hadoop 也會像當年的Linux 一樣被廣泛應用于越來越多的領域,從而風靡全球。
Hadoop技術原理總結
1、Hadoop運行原理
Hadoop是一個開源的可運行于大規模集群上的分布式并行編程框架,其最核心的設計包括:MapReduce和HDFS。基于 Hadoop,你可以輕松地編寫可處理海量數據的分布式并行程序,并將其運行于由成百上千個結點組成的大規模計算機集群上。
基于MapReduce計算模型編寫分布式并行程序相對簡單,程序員的主要工作就是設計實現Map和Reduce類,其它的并行編程中的種種復雜問題,如分布式存儲,工作調度,負載平衡,容錯處理,網絡通信等,均由 MapReduce框架和HDFS文件系統負責處理,程序員完全不用操心。換句話說程序員只需要關心自己的業務邏輯即可,不必關心底層的通信機制等問題,即可編寫出復雜高效的并行程序。如果說分布式并行編程的難度足以讓普通程序員望而生畏的話,開源的 Hadoop的出現極大的降低了它的門檻。
2、Mapreduce原理
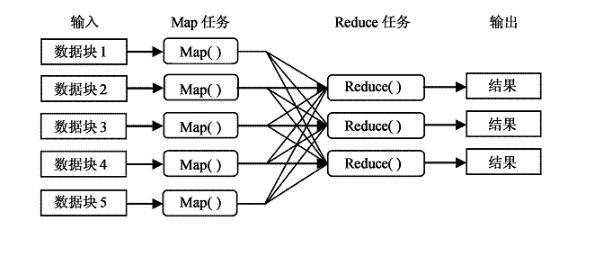
簡單的說:MapReduce框架的核心步驟主要分兩部分:Map和Reduce。當你向MapReduce框架提交一個計算作業時,它會首先把計算作業拆分成若干個Map任務,然后分配到不同的節點上去執行,每一個Map任務處理輸入數據中的一部分,當Map任務完成后,它會生成一些中間文件,這些中間文件將會作為Reduce任務的輸入數據。Reduce對數據做進一步處理之后,輸出最終結果。
MapReduce是Hadoop的核心技術之一,為分布式計算的程序設計提供了良好的編程接口,并且屏蔽了底層通信原理,使得程序員只需關心業務邏輯本事,就可輕易的編寫出基于集群的分布式并行程序。從它名字上來看,大致可以看出個兩個動詞Map和Reduce,“Map(展開)”就是將一個任務分解成為多個子任務并行的執行,“Reduce”就是將分解后多任務處理的結果匯總起來,得出最后的分析結果并輸出。
適合用 MapReduce來處理的數據集(或任務)有一個基本要求:待處理的數據集可以分解成許多小的數據集,而且每一個小數據集都可以完全并行地進行處理。
Map-Reduce的處理過程主要涉及以下四個部分:
?Client進程:用于提交Map-reduce任務job;
?JobTracker進程:其為一個Java進程,其main class為JobTracker;
?TaskTracker進程:其為一個Java進程,其main class為TaskTracker;
?HDFS:Hadoop分布式文件系統,用于在各個進程間共享Job相關的文件;
其中JobTracker進程作為主控,用于調度和管理其它的TaskTracker進程, JobTracker可以運行于集群中任一臺計算機上,通常情況下配置JobTracker進程運行在NameNode節點之上。TaskTracker負責執行JobTracker進程分配給的任務,其必須運行于 DataNode 上,即DataNode 既是數據存儲結點,也是計算結點。 JobTracker將Map任務和Reduce任務分發給空閑的TaskTracker,讓這些任務并行運行,并負責監控任務的運行情況。如果某一個 TaskTracker出故障了,JobTracker會將其負責的任務轉交給另一個空閑的 TaskTracker重新運行。
本地計算-原理
數據存儲在哪一臺計算機上,就由這臺計算機進行這部分數據的計算,這樣可以減少數據在網絡上的傳輸,降低對網絡帶寬的需求。在Hadoop這樣的基于集群的分布式并行系統中,計算結點可以很方便地擴充,而因它所能夠提供的計算能力近乎是無限的,但是由是數據需要在不同的計算機之間流動,故網絡帶寬變成了瓶頸,是非常寶貴的,“本地計算”是最有效的一種節約網絡帶寬的手段,業界把這形容為“移動計算比移動數據更經濟”。
3、HDFS存儲的機制
Hadoop的分布式文件系統 HDFS是建立在Linux文件系統之上的一個虛擬分布式文件系統,它由一個管理節點 ( NameNode )和N個數據節點 ( DataNode )組成,每個節點均是一臺普通的計算機。在使用上同我們熟悉的單機上的文件系統非常類似,一樣可以建目錄,創建,復制,刪除文件,查看文件內容等。但其底層實現上是把文件切割成 Block(塊),然后這些 Block分散地存儲于不同的 DataNode 上,每個 Block還可以復制數份存儲于不同的 DataNode上,達到容錯容災之目的。NameNode則是整個 HDFS的核心,它通過維護一些數據結構,記錄了每一個文件被切割成了多少個 Block,這些 Block可以從哪些 DataNode中獲得,各個 DataNode的狀態等重要信息。
HDFS的數據塊
每個磁盤都有默認的數據塊大小,這是磁盤進行讀寫的基本單位。構建于單個磁盤之上的文件系統通過磁盤塊來管理該文件系統中的塊。該文件系統中的塊一般為磁盤塊的整數倍。磁盤塊一般為512字節.HDFS也有塊的概念,默認為64MB(一個map處理的數據大小).HDFS上的文件也被劃分為塊大小的多個分塊,與其他文件系統不同的是,HDFS中小于一個塊大小的文件不會占據整個塊的空間。
任務粒度——數據切片(Splits)
把原始大數據集切割成小數據集時,通常讓小數據集小于或等于 HDFS中一個 Block的大小(缺省是 64M),這樣能夠保證一個小數據集位于一臺計算機上,便于本地計算。有 M個小數據集待處理,就啟動 M個 Map任務,注意這 M個 Map任務分布于 N臺計算機上并行運行,Reduce任務的數量 R則可由用戶指定。
HDFS用塊存儲帶來的第一個明顯的好處一個文件的大小可以大于網絡中任意一個磁盤的容量,數據塊可以利用磁盤中任意一個磁盤進行存儲。第二個簡化了系統的設計,將控制單元設置為塊,可簡化存儲管理,計算單個磁盤能存儲多少塊就相對容易。同時也消除了對元數據的顧慮,如權限信息,可以由其他系統單獨管理。
4、舉一個簡單的例子說明MapReduce的運行機制
以計算一個文本文件中每個單詞出現的次數的程序為例,《k1,v1》可以是 《行在文件中的偏移位置,文件中的一行》,經 Map函數映射之后,形成一批中間結果 《單詞,出現次數》,而 Reduce函數則可以對中間結果進行處理,將相同單詞的出現次數進行累加,得到每個單詞的總的出現次數。

5.MapReduce的核心過程----Shuffle[‘??fl]和Sort
shuffle是mapreduce的心臟,了解了這個過程,有助于編寫效率更高的mapreduce程序和hadoop調優。
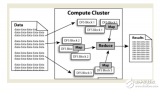
Shuffle是指從Map產生輸出開始,包括系統執行排序以及傳送Map輸出到Reducer作為輸入的過程。如下圖所示:

首先從Map端開始分析,當Map開始產生輸出的時候,他并不是簡單的把數據寫到磁盤,因為頻繁的操作會導致性能嚴重下降,他的處理更加復雜,數據首先是寫到內存中的一個緩沖區,并作一些預排序,以提升效率,如圖:

每個Map任務都有一個用來寫入“輸出數據”的“循環內存緩沖區”,這個緩沖區默認大小是100M(可以通過io.sort.mb屬性來設置具體的大小),當緩沖區中的數據量達到一個特定的閥值(io.sort.mb * io.sort.spill.percent,其中io.sort.spill.percent默認是0.80)時,系統將會啟動一個后臺線程把緩沖區中的內容spill到磁盤。在spill過程中,Map的輸出將會繼續寫入到緩沖區,但如果緩沖區已經滿了,Map就會被阻塞直到spill完成。spill線程在把緩沖區的數據寫到磁盤前,會對他進行一個二次排序,首先根據數據所屬的partition排序,然后每個partition中再按Key排序。輸出包括一個索引文件和數據文件,如果設定了Combiner,將在排序輸出的基礎上進行。Combiner就是一個Mini Reducer,它在執行Map任務的節點本身運行,先對Map的輸出作一次簡單的Reduce,使得Map的輸出更緊湊,更少的數據會被寫入磁盤和傳送到Reducer。Spill文件保存在由mapred.local.dir指定的目錄中,Map任務結束后刪除。
每當內存中的數據達到spill閥值的時候,都會產生一個新的spill文件,所以在Map任務寫完他的最后一個輸出記錄的時候,可能會有多個spill文件,在Map任務完成前,所有的spill文件將會被歸并排序為一個索引文件和數據文件。如圖3所示。這是一個多路歸并過程,最大歸并路數由io.sort.factor控制(默認是10)。如果設定了Combiner,并且spill文件的數量至少是3(由min.num.spills.for.combine屬性控制),那么Combiner將在輸出文件被寫入磁盤前運行以壓縮數據。

對寫入到磁盤的數據進行壓縮(這種壓縮同Combiner的壓縮不一樣)通常是一個很好的方法,因為這樣做使得數據寫入磁盤的速度更快,節省磁盤空間,并減少需要傳送到Reducer的數據量。默認輸出是不被壓縮的,但可以很簡單的設置mapred.compress.map.output為true啟用該功能。壓縮所使用的庫由mapred.map.output.compression.codec來設定。
當spill 文件歸并完畢后,Map 將刪除所有的臨時spill文件,并告知TaskTracker任務已完成。Reducers通過HTTP來獲取對應的數據。用來傳輸partitions數據的工作線程個數由tasktracker.http.threads控制,這個設定是針對每一個TaskTracker的,并不是單個Map,默認值為40,在運行大作業的大集群上可以增大以提升數據傳輸速率。
現在讓我們轉到Shuffle的Reduce部分。Map的輸出文件放置在運行Map任務的TaskTracker的本地磁盤上(注意:Map輸出總是寫到本地磁盤,但是Reduce輸出不是,一般是寫到HDFS),它是運行Reduce任務的TaskTracker所需要的輸入數據。Reduce任務的輸入數據分布在集群內的多個Map任務的輸出中,Map任務可能會在不同的時間內完成,只要有其中一個Map任務完成,Reduce任務就開始拷貝他的輸出。這個階段稱為拷貝階段,Reduce任務擁有多個拷貝線程,可以并行的獲取Map輸出。可以通過設定mapred.reduce.parallel.copies來改變線程數。
Reduce是怎么知道從哪些TaskTrackers中獲取Map的輸出呢?當Map任務完成之后,會通知他們的父TaskTracker,告知狀態更新,然后TaskTracker再轉告JobTracker,這些通知信息是通過心跳通信機制傳輸的,因此針對以一個特定的作業,jobtracker知道Map輸出與tasktrackers的映射關系。Reducer中有一個線程會間歇的向JobTracker詢問Map輸出的地址,直到把所有的數據都取到。在Reducer取走了Map輸出之后,TaskTracker不會立即刪除這些數據,因為Reducer可能會失敗,他們會在整個作業完成之后,JobTracker告知他們要刪除的時候才去刪除。
如果Map輸出足夠小,他們會被拷貝到Reduce TaskTracker的內存中(緩沖區的大小由mapred.job.shuffle.input.buffer.percnet控制),或者達到了Map輸出的閥值的大小(由mapred.inmem.merge.threshold控制),緩沖區中的數據將會被歸并然后spill到磁盤。
拷貝來的數據疊加在磁盤上,有一個后臺線程會將它們歸并為更大的排序文件,這樣做節省了后期歸并的時間。對于經過壓縮的Map輸出,系統會自動把它們解壓到內存方便對其執行歸并。
當所有的Map 輸出都被拷貝后,Reduce 任務進入排序階段(更恰當的說應該是歸并階段,因為排序在Map端就已經完成),這個階段會對所有的Map輸出進行歸并排序,這個工作會重復多次才能完成。
假設這里有50 個Map 輸出(可能有保存在內存中的),并且歸并因子是10(由io.sort.factor控制,就像Map端的merge一樣),那最終需要5次歸并。每次歸并會把10個文件歸并為一個,最終生成5個中間文件。在這一步之后,系統不再把5個中間文件歸并成一個,而是排序后直接“喂”給Reduce函數,省去向磁盤寫數據這一步。最終歸并的數據可以是混合數據,既有內存上的也有磁盤上的。由于歸并的目的是歸并最少的文件數目,使得在最后一次歸并時總文件個數達到歸并因子的數目,所以每次操作所涉及的文件個數在實際中會更微妙些。譬如,如果有40個文件,并不是每次都歸并10個最終得到4個文件,相反第一次只歸并4個文件,然后再實現三次歸并,每次10個,最終得到4個歸并好的文件和6個未歸并的文件。要注意,這種做法并沒有改變歸并的次數,只是最小化寫入磁盤的數據優化措施,因為最后一次歸并的數據總是直接送到Reduce函數那里。在Reduce階段,Reduce函數會作用在排序輸出的每一個key上。這個階段的輸出被直接寫到輸出文件系統,一般是HDFS。在HDFS中,因為TaskTracker節點也運行著一個DataNode進程,所以第一個塊備份會直接寫到本地磁盤。到此,MapReduce的Shuffle和Sort分析完畢。
6、Hadoop中Combiner的作用?
6.1 Partition
把 Map任務輸出的中間結果按 key的范圍劃分成 R份( R是預先定義的 Reduce任務的個數),劃分時通常使用hash函數如: hash(key) mod R,這樣可以保證某一段范圍內的 key,一定是將會由一個Reduce任務來處理,這樣可以簡化 Reduce獲取計算數據的過程。
6.2 Combine操作
在 partition之前,還可以對中間結果先做 combine,即將中間結果中有相同 key的 《key, value》對合并成一對。combine的過程與Reduce的過程類似,很多情況下就可以直接使用 Reduce函數,但 combine是作為 Map任務的一部分,在執行完 Map函數后緊接著執行的,而Reduce必須在所有的Map操作完成后才能進行。Combine能夠減少中間結果中 《key, value》對的數目,從而減少網絡流量。
6.3 Reduce任務從 Map任務結點取中間結果
Map 任務的中間結果在做完 Combine和 Partition之后,以文件形式存于本地磁盤。中間結果文件的位置會通知主控JobTracker,JobTracker再通知 Reduce任務到哪一個 DataNode上去取中間結果。注意所有的 Map任務產生中間結果均按其 Key用同一個Hash函數劃分成了 R份,R個 Reduce任務各自負責一段 Key區間。每個 Reduce需要向許多個原Map任務結點以取得落在其負責的Key區間內的中間結果,然后執行 Reduce函數,形成一個最終的結果文件。
6.4 任務管道
有R個 Reduce任務,就會有 R個最終結果,很多情況下這 R個最終結果并不需要合并成一個最終結果。因為這 R個最終結果又可以做為另一個計算任務的輸入,開始另一個并行計算任務。

這個 MapReduce的計算過程簡而言之,就是將大數據集分解為成百上千的小數據集,每個(或若干個)數據集分別由集群中的一個結點(一般就是一臺普通的計算機)進行處理并生成中間結果,然后這些中間結果又由大量的結點進行合并,形成最終結果。
計算模型的核心是 Map 和 Reduce 兩個函數,這兩個函數由用戶負責實現,功能是按一定的映射規則將輸入的 《key, value》對轉換成另一個或一批 《key, value》對輸出。
6.5、總結
(1)、combiner使用的合適,可以在滿足業務的情況下提升job的速度,如果不合適,則將導致輸出的結果不正確,但是不是所有的場合都適合combiner。根據自己的業務來使用。hadoop就是map和 reduce的過程。服務器上一個目錄節點+多個數據節點。將程序傳送到各個節點,在數據節點上進行計算
(2)、將數據存儲到不同節點,用map方式對應管理,在各個節點進行計算,采用reduce進行合并結果集
(3)、就是通過java程序和目錄節點配合,將數據存放到不同數據節點上
(4)、看上邊的2.注意,分布式注重的是計算,不是每個場景都適合
(5)、將文件存放到不同的數據節點,然后每個節點計算出前十個進行reduce的計算。













 工商網監
工商網監
評論