 電子發(fā)燒友App
電子發(fā)燒友App


HBase簡(jiǎn)介
HBase是一個(gè)分布式的、面向列的開源數(shù)據(jù)庫,該技術(shù)來源于 Fay Chang 所撰寫的Google論文“Bigtable:一個(gè)結(jié)構(gòu)化數(shù)據(jù)的分布式存儲(chǔ)系統(tǒng)”。就像Bigtable利用了Google文件系統(tǒng)(File System)所提供的分布式數(shù)據(jù)存儲(chǔ)一樣,HBase在Hadoop之上提供了類似于Bigtable的能力。HBase是Apache的Hadoop項(xiàng)目的子項(xiàng)目。HBase不同于一般的關(guān)系數(shù)據(jù)庫,它是一個(gè)適合于非結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)的數(shù)據(jù)庫。另一個(gè)不同的是HBase基于列的而不是基于行的模式。
什么時(shí)候需要HBase呢?
半結(jié)構(gòu)化或非結(jié)構(gòu)化數(shù)據(jù),對(duì)于數(shù)據(jù)結(jié)構(gòu)字段不夠確定或雜亂無章很難按一個(gè)概念去進(jìn)行抽取的數(shù)據(jù)適合用HBase。當(dāng)業(yè)務(wù)發(fā)展需要存儲(chǔ)author的email,phone,address信息時(shí)RDBMS需要停機(jī)維護(hù),而HBase支持動(dòng)態(tài)增加。
記錄非常稀疏
RDBMS的行有多少列是固定的,為null的列浪費(fèi)了存儲(chǔ)空間。而如上文提到的,HBase為null的Column不會(huì)被存儲(chǔ),這樣既節(jié)省了空間又提高了讀性能。
多版本數(shù)據(jù)
如上文提到的根據(jù)Row key和Column key定位到的Value可以有任意數(shù)量的版本值,因此對(duì)于需要存儲(chǔ)變動(dòng)歷史記錄的數(shù)據(jù),用HBase就非常方便了。比如上例中的author的Address是會(huì)變動(dòng)的,業(yè)務(wù)上一般只需要最新的值,但有時(shí)可能需要查詢到歷史值。
超大數(shù)據(jù)量
當(dāng)數(shù)據(jù)量越來越大,RDBMS數(shù)據(jù)庫撐不住了,就出現(xiàn)了讀寫分離策略,通過一個(gè)Master專門負(fù)責(zé)寫操作,多個(gè)Slave負(fù)責(zé)讀操作,服務(wù)器成本倍增。隨著壓力增加,Master撐不住了,這時(shí)就要分庫了,把關(guān)聯(lián)不大的數(shù)據(jù)分開部署,一些join查詢不能用了,需要借助中間層。隨著數(shù)據(jù)量的進(jìn)一步增加,一個(gè)表的記錄越來越大,查詢就變得很慢,于是又得搞分表,比如按ID取模分成多個(gè)表以減少單個(gè)表的記錄數(shù)。經(jīng)歷過這些事的人都知道過程是多么的折騰。采用HBase就簡(jiǎn)單了,只需要加機(jī)器即可,HBase會(huì)自動(dòng)水平切分?jǐn)U展,跟Hadoop的無縫集成保障了其數(shù)據(jù)可靠性(HDFS)和海量數(shù)據(jù)分析的高性能(MapReduce)。
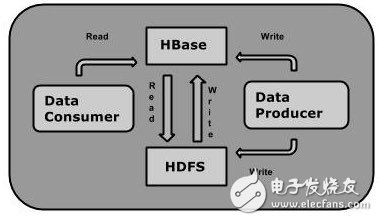
HTable一些基本概念
Row key
行主鍵, HBase不支持條件查詢和Order by等查詢,讀取記錄只能按Row key(及其range)或全表掃描,因此Row key需要根據(jù)業(yè)務(wù)來設(shè)計(jì)以利用其存儲(chǔ)排序特性(Table按Row key字典序排序如1,10,100,11,2)提高性能。
Column Family(列族)
在表創(chuàng)建時(shí)聲明,每個(gè)Column Family為一個(gè)存儲(chǔ)單元。在上例中設(shè)計(jì)了一個(gè)HBase表blog,該表有兩個(gè)列族:article和author。
Column(列)
HBase的每個(gè)列都屬于一個(gè)列族,以列族名為前綴,如列article:title和article:content屬于article列族,author:name和author:nickname屬于author列族。
Column不用創(chuàng)建表時(shí)定義即可以動(dòng)態(tài)新增,同一Column Family的Columns會(huì)群聚在一個(gè)存儲(chǔ)單元上,并依Column key排序,因此設(shè)計(jì)時(shí)應(yīng)將具有相同I/O特性的Column設(shè)計(jì)在一個(gè)Column Family上以提高性能。
Timestamp
HBase通過row和column確定一份數(shù)據(jù),這份數(shù)據(jù)的值可能有多個(gè)版本,不同版本的值按照時(shí)間倒序排序,即最新的數(shù)據(jù)排在最前面,查詢時(shí)默認(rèn)返回最新版本。如上例中row key=1的author:nickname值有兩個(gè)版本,分別為1317180070811對(duì)應(yīng)的“一葉渡江”和1317180718830對(duì)應(yīng)的“yedu”(對(duì)應(yīng)到實(shí)際業(yè)務(wù)可以理解為在某時(shí)刻修改了nickname為yedu,但舊值仍然存在)。Timestamp默認(rèn)為系統(tǒng)當(dāng)前時(shí)間(精確到毫秒),也可以在寫入數(shù)據(jù)時(shí)指定該值。
Value
每個(gè)值通過4個(gè)鍵唯一索引,tableName+RowKey+ColumnKey+Timestamp=》value,例如上例中{tableName=’blog’,RowKey=’1’,ColumnName=’author:nickname’,Timestamp=’ 1317180718830’}索引到的唯一值是“yedu”。
存儲(chǔ)類型
TableName 是字符串
RowKey 和 ColumnName 是二進(jìn)制值(Java 類型 byte[])
Timestamp 是一個(gè) 64 位整數(shù)(Java 類型 long)
value 是一個(gè)字節(jié)數(shù)組(Java類型 byte[])。
將HTable的存儲(chǔ)結(jié)構(gòu)理解為
即HTable按Row key自動(dòng)排序,每個(gè)Row包含任意數(shù)量個(gè)Columns,Columns之間按Column key自動(dòng)排序,每個(gè)Column包含任意數(shù)量個(gè)Values。理解該存儲(chǔ)結(jié)構(gòu)將有助于查詢結(jié)果的迭代。











 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論