 電子發燒友App
電子發燒友App


自從google發表著名的GFS、MapReduce、BigTable三篇paper以后,互聯網正式迎來了大數據時代。大數據的顯著特點是大,哪里都大的大。本篇主要針對volume大的數據時,使用機器學習來進行數據處理過程中遇到的架構方面的問題做一個系統的梳理。
有了GFS我們有能力積累海量的數據樣本,比如在線廣告的曝光和點擊數據,天然具有正負樣本的特性,累積一兩個月往往就能輕松獲得百億、千億級的訓練樣本。這樣海量的樣本如何存儲?用什么樣的模型可以學習海量樣本中有用的pattern?這些問題不止是工程問題,也值得每個做算法的同學去深入思考。
1.1簡單模型or復雜模型
在深度學習概念提出之前,算法工程師手頭能用的工具其實并不多,就LR、SVM、感知機等寥寥可數、相對固定的若干個模型和算法;那時候要解決一個實際的問題,算法工程師更多的工作主要是在特征工程方面。而特征工程本身并沒有很系統化的指導理論(至少目前沒有看到系統介紹特征工程的書籍),所以很多時候特征的構造技法顯得光怪陸離,是否有用也取決于問題本身、數據樣本、模型以及運氣。
在特征工程作為算法工程師主要工作內容的時候,構造新特征的嘗試往往很大部分都不能在實際工作中work。據我了解,國內幾家大公司在特征構造方面的成功率在后期一般不會超過20%。也就是80%的新構造特征往往并沒什么正向提升效果。如果給這種方式起一個名字的話,大概是簡單模型+復雜特征;簡單模型說的是算法比如LR、SVM本身并不服務,參數和表達能力基本呈現一種線性關系,易于理解。復雜特征則是指特征工程方面不斷嘗試使用各種奇技淫巧構造的可能有用、可能沒用的特征,這部分特征的構造方式可能會有各種trick,比如窗口滑動、離散化、歸一化、開方、平方、笛卡爾積、多重笛卡爾積等等;順便提一句,因為特征工程本身并沒有特別系統的理論和總結,所以初入行的同學想要構造特征就需要多讀paper,特別是和自己業務場景一樣或類似的場景的paper,從里面學習作者分析、理解數據的方法以及對應的構造特征的技法;久而久之,有望形成自己的知識體系。
深度學習概念提出以后,人們發現通過深度神經網絡可以進行一定程度的表示學習(representation learning),例如在圖像領域,通過CNN提取圖像feature并在此基礎上進行分類的方法,一舉打破了之前算法的天花板,而且是以極大的差距打破。這給所有算法工程師帶來了新的思路,既然深度學習本身有提取特征的能力,干嘛還要苦哈哈的自己去做人工特征設計呢?
深度學習雖然一定程度上緩解了特征工程的壓力,但這里要強調兩點:1.緩解并不等于徹底解決,除了圖像這種特定領域,在個性化推薦等領域,深度學習目前還沒有完全取得絕對的優勢;究其原因,可能還是數據自身內在結構的問題,使得在其他領域目前還沒有發現類似圖像+CNN這樣的完美CP。2.深度學習在緩解特征工程的同時,也帶來了模型復雜、不可解釋的問題。算法工程師在網絡結構設計方面一樣要花很多心思來提升效果。概括起來,深度學習代表的簡單特征+復雜模型是解決實際問題的另一種方式。
兩種模式孰優孰劣還難有定論,以點擊率預測為例,在計算廣告領域往往以海量特征+LR為主流,根據VC維理論,LR的表達能力和特征個數成正比,因此海量的feature也完全可以使LR擁有足夠的描述能力。而在個性化推薦領域,深度學習剛剛萌芽,目前google play采用了WDL的結構[1],youtube采用了雙重DNN的結構[2]。
不管是那種模式,當模型足夠龐大的時候,都會出現模型參數一臺機器無法存放的情況。比如百億級feature的LR對應的權重w有好幾十個G,這在很多單機上存儲都是困難的,大規模神經網絡則更復雜,不僅難以單機存儲,而且參數和參數之間還有邏輯上的強依賴;要對超大規模的模型進行訓練勢必要借用分布式系統的技法,本文主要是系統總結這方面的一些思路。
1.2數據并行vs模型并行
數據并行和模型并行是理解大規模機器學習框架的基礎概念,其緣起未深究,第一次看到是在姐夫(Jeff Dean)的blog里,當時匆匆一瞥,以為自己懂了。多年以后,再次開始調研這個問題的時候才想起長者的教訓,年輕人啊,還是圖樣,圖森破。如果你和我一樣曾經忽略過這個概念,今天不放復習一下。
這兩個概念在[3]中沐帥曾經給出了一個非常直觀而經典的解釋,可惜不知道什么原因,當我想引用時卻發現已經被刪除了。我在這里簡單介紹下這個比喻:如果要修兩棟樓,有一個工程隊,怎么操作?第一個方案是將人分成兩組,分別蓋樓,改好了就裝修;第二種做法是一組人蓋樓,等第一棟樓蓋好,另一組裝修第一棟,然后第一組繼續蓋第二棟樓,改完以后等裝修隊裝修第二棟樓。咋一看,第二種方法似乎并行度并不高,但第一種方案需要每個工程人員都擁有“蓋樓”和“裝修”兩種能力,而第二個方案只需要每個人擁有其中一種能力即可。第一個方案和數據并行類似,第二個方案則道出了模型并行的精髓。
數據并行理解起來比較簡單,當樣本比較多的時候,為了使用所有樣本來訓練模型,我們不妨把數據分布到不同的機器上,然后每臺機器都來對模型參數進行迭代,如下圖所示
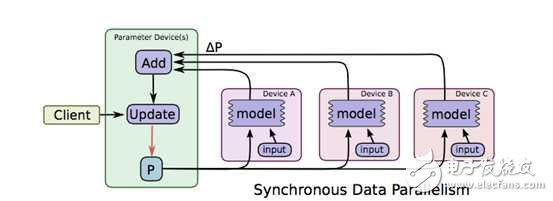
?
圖片取材于TensorFlow的paper[4],圖中ABC代表三臺不同的機器,上面存儲著不同的樣本,模型P在各臺機器上計算對應的增量,然后在參數存儲的機器上進行匯總和更新,這就是數據并行。先忽略synchronous,這是同步機制相關的概念,在第三節會有專門介紹。
數據并行概念簡單,而且不依賴于具體的模型,因此數據并行機制可以作為框架的一種基礎功能,對所有算法都生效。與之不同的是,模型并行因為參數間存在依賴關系(其實數據并行參數更新也可能會依賴所有的參數,但區別在于往往是依賴于上一個迭代的全量參數。而模型并行往往是同一個迭代內的參數之間有強依賴關系,比如DNN網絡的不同層之間的參數依照BP算法形成的先后依賴),無法類比數據并行這樣直接將模型參數分片而破壞其依賴關系,所以模型并行不僅要對模型分片,同時需要調度器來控制參數間的依賴關系。而每個模型的依賴關系往往并不同,所以模型并行的調度器因模型而異,較難做到完全通用。關于這個問題,CMU的Erix Xing在[5]中有所介紹,感興趣的可以參考。
模型并行的問題定義可以參考姐夫的[6],這篇paper也是tensorflow的前身相關的總結,其中圖

?
解釋了模型并行的物理圖景,當一個超大神經網絡無法存儲在一臺機器上時,我們可以切割網絡存到不同的機器上,但是為了保持不同參數分片之間的依賴,如圖中粗黑線的部分,則需要在不同的機器之間進行concurrent控制;同一個機器內部的參數依賴,即途中細黑線部分在機器內即可完成控制。
黑線部分如何有效控制呢?如下圖所示

在將模型切分到不同機器以后,我們將參數和樣本一起在不同機器間流轉,圖中ABC代表模型的不同部分的參數;假設C依賴B,B依賴A,機器1上得到A的一個迭代后,將A和必要的樣本信息一起傳到機器2,機器2根據A和樣本對P2更新得到,以此類推;當機器2計算B的時候,機器1可以展開A的第二個迭代的計算。了解CPU流水線操作的同學一定感到熟悉,是的,模型并行是通過數據流水線來實現并行的。想想那個蓋樓的第二種方案,就能理解模型并行的精髓了。
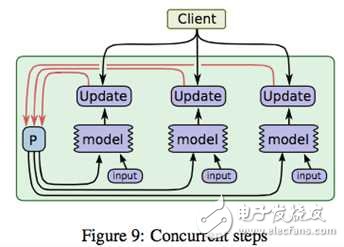
?
上圖則是對控制模型參數依賴的調度器的一個示意圖,實際框架中一般都會用DAG(有向無環圖)調度技術來實現類似功能,未深入研究,以后有機會再補充說明。
理解了數據并行和模型并行對后面參數服務器的理解至關重要,但現在讓我先蕩開一筆,簡單介紹下并行計算框架的一些背景信息。
2. 并行算法演進
2.1 MapReduce路線
從函數式編程中的受到啟發,google發布了MapReduce[7]的分布式計算方式;通過將任務切分成多個疊加的Map+Reduce任務,來完成復雜的計算任務,示意圖如下

?
MapReduce的主要問題有兩個,一是原語的語義過于低級,直接使用其來寫復雜算法,開發量比較大;另一個問題是依賴于磁盤進行數據傳遞,性能跟不上業務需求。
為了解決MapReduce的兩個問題,Matei在[8]中提出了一種新的數據結構RDD,并構建了Spark框架。Spark框架在MR語義之上封裝了DAG調度器,極大降低了算法使用的門檻。較長時間內spark幾乎可以說是大規模機器學習的代表,直至后來沐帥的參數服務器進一步開拓了大規模機器學習的領域以后,spark才暴露出一點點不足。如下圖

從圖中可以看出,spark框架以Driver為核心,任務調度和參數匯總都在driver,而driver是單機結構,所以spark的瓶頸非常明顯,就在Driver這里。當模型規模大到一臺機器存不下的時候,Spark就無法正常運行了。所以從今天的眼光來看,Spark只能稱為一個中等規模的機器學習框架。劇透一句,公司開源的Angel通過修改Driver的底層協議將Spark擴展到了一個高一層的境界。后面還會再詳細介紹這部分。
MapReduce不僅是一個框架,還是一種思想,google開創性的工作為我們找到了大數據分析的一個可行方向,時至今日,仍不過時。只是逐漸從業務層下沉到底層語義應該處于的框架下層。
2.2 MPI技術
沐帥在[9]中對MPI的前景做了簡要介紹;和Spark不同,MPI是類似socket的一種系統通信API,只是支持了消息廣播等功能。因為對MPI研究不深入,這里簡單介紹下優點和缺點吧;優點是系統級支持,性能杠杠的;缺點也比較多,一是和MR一樣因為原語過于低級,用MPI寫算法,往往代碼量比較大。另一方面是基于MPI的集群,如果某個任務失敗,往往需要重啟整個集群,而MPI集群的任務成功率并不高。阿里在[10]中給出了下圖:

?
從圖中可以看出,MPI作業失敗的幾率接近五成。MPI也并不是完全沒有可取之處,正如沐帥所說,在超算集群上還是有場景的。對于工業屆依賴于云計算、依賴于commodity計算機來說,則顯得性價比不夠高。當然如果在參數服務器的框架下,對單組worker再使用MPI未嘗不是個好的嘗試,[10]的鯤鵬系統正式這么設計的。
3. 參數服務器演進
3.1 歷史演進
沐帥在[12]中將參數服務器的歷史劃分為三個階段,第一代參數服務器萌芽于沐帥的導師Smola的[11],如下圖所示:

?
這個工作中僅僅引入memcached來存放key-value數據,不同的處理進程并行對其進行處理。[13]中也有類似的想法,第二代參數服務器叫application-specific參數服務器,主要針對特定應用而開發,其中最典型的代表應該是tensorflow的前身[6]。
第三代參數服務器,也即是通用參數服務器框架是由百度少帥李沐正式提出的,和前兩代不同,第三代參數服務器從設計上就是作為一個通用大規模機器學習框架來定位的。要擺脫具體應用、算法的束縛,做一個通用的大規模機器學習框架,首先就要定義好框架的功能;而所謂框架,往往就是把大量重復的、瑣碎的、做了一次就不想再來第二次的臟活、累活進行良好而優雅的封裝,讓使用框架的人可以只關注與自己的核心邏輯。第三代參數服務器要對那些功能進行封裝呢?沐帥總結了這幾點,我照搬如下:
1)高效的網絡通信:因為不管是模型還是樣本都十分巨大,因此對網絡通信的高效支持以及高配的網絡設備都是大規模機器學習系統不可缺少的;
2)靈活的一致性模型:不同的一致性模型其實是在模型收斂速度和集群計算量之間做tradeoff;要理解這個概念需要對模型性能的評價做些分析,暫且留到下節再介紹。
3)彈性可擴展:顯而易見
4)容災容錯:大規模集群協作進行計算任務的時候,出現Straggler或者機器故障是非常常見的事,因此系統設計本身就要考慮到應對;沒有故障的時候,也可能因為對任務時效性要求的變化而隨時更改集群的機器配置。這也需要框架能在不影響任務的情況下能做到機器的熱插拔。
5)易用性:主要針對使用框架進行算法調優的工程師而言,顯然,一個難用的框架是沒有生命力的。
在正式介紹第三代參數服務器的主要技術之前,先從另一個角度來看下大規模機器學習框架的演進

這張圖可以看出,在參數服務器出來之前,人們已經做了多方面的并行嘗試,不過往往只是針對某個特定算法或特定領域,比如YahooLDA是針對LDA算法的。當模型參數突破十億以后,則可以看出參數服務器一統江湖,再無敵手。
首先我們看看第三代參數服務器的基本架構

?
上圖的resource manager可以先放一放,因為實際系統中這部分往往是復用現有的資源管理系統,比如yarn或者mesos;底下的training data毋庸置疑的需要類似GFS的分布式文件系統的支持;剩下的部分就是參數服務器的核心組件了。
圖中畫了一個server group和三個worker group;實際應用中往往也是類似,server group用一個,而worker group按需配置;server manager是server group中的管理節點,一般不會有什么邏輯,只有當有server node加入或退出的時候,為了維持一致性哈希而做一些調整。
Worker group中的task schedule則是一個簡單的任務協調器,一個具體任務運行的時候,task schedule負責通知每個worker加載自己對應的數據,然后去server node上拉取一個要更新的參數分片,用本地數據樣本計算參數分片對應的變化量,然后同步給server node;server node在收到本機負責的參數分片對應的所有worker的更新后,對參數分片做一次update。
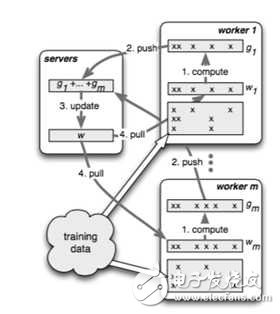
?
如圖所示,不同的worker同時并行運算的時候,可能因為網絡、機器配置等外界原因,導致不同的worker的進度是不一樣的,如何控制worker的同步機制是一個比較重要的課題。詳見下節分解。












 工商網監
工商網監
評論