 電子發燒友App
電子發燒友App


EAN一13碼的圖像識別系統設計與實現
0 引 言
自動化數據采集技術是信息采集和處理的關鍵技術,條碼技術在自動化數據采集中占重要地位,得到了廣泛的應用。但是普遍的條碼閱讀器是基于激光掃描或者CCD攝像頭的,在生活中不是很常見。如果條碼識讀能用普通的攝像頭(如:手機攝像頭或網絡攝像頭),條碼將會給人們的日常生活帶來更多的方便。近來手機和機器人的應用得到很大發展,手機的一維碼識別、機器人的一維碼識別、自動分揀物品等都有著很好的應用前景。為了拓寬一維碼的應用,基于圖像處理的一維條碼研究有著重要意義。
在最近幾年關于一維碼圖像識別的識別文章中,都是針對比較理想的條碼進行識別的,或者只是講解一維條碼圖像識別的某一個步驟,或者是人為地加上部分噪聲進行處理,很少有從一幅真正拍攝的圖像來識讀的。這里完成了整個條碼識別系統的設計和圖像處理的算法設計,實現了圖像的錄入到譯出條碼的整個過程,并通過實驗詳細闡述了識別流程和效果。
1 EAN—13碼特征
EAN一13是標準商品條碼,它是一種(7,2)碼,即每個字符的總寬度為7個模塊,由兩個條和兩個空交替組成,而每個條空的寬度不超過4個模塊。EAN一13商品條碼由左側空白區,起始符、左側數據符、中間分隔符、右側數據符、、終止符、校驗符、右側空白區組成,如圖1所示。EAN一13碼包含13個字符,但只對12個字符進行編碼,其第13位(從右向左排序)不進行編碼,數值隱含在左側數據符的奇偶排列中,稱為前置符。奇偶性指的是每個字符所含條的模塊數為奇數或者偶數,左側數據符為奇、偶排列,右側數據符為偶排列,左邊的碼字組成方式是“空條空條”,右邊的碼字組成方式是“條空條空”。
由EAN一13條碼的結構知:左側空白區為11個模塊,起始符為3個模塊(3個條空),左側數據符為42個模塊(24個條空),中間分隔符為5個模塊(5個條空),右側數據符為35個模塊(20個條空),檢校符為7個模塊(4個條空),終止符為3個模塊(3個條空),右側空白區為7個模塊,整個編碼區的模塊數為3+42+5+35+7+3=95個,條空數為3+24+5+20+4+3=59個。若將黑色模塊(條)用二進制的“1”表示,白色模塊(空)用二進制的“0”表示,則數據字符的編碼圖案有30種,如表1所示。且有如下編碼:起始符:101中間分隔符010110,終止符101。
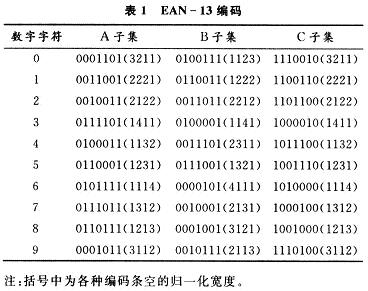
如何確定數字字符是屬于A子集,B子集或者C子集。EAN一13碼左側數據符由A,B子集確定,取決于前置符,右側數據符屬于C子集。前置碼和左側數據符商品條碼字符集的選用規則如表2所示。

2 條碼識別
在條碼識別的整個過程中,都是基于以下假設:所處理的圖像正中肯定是包含條碼部分的,這樣可以很好地減少計算量。條碼識別系統分為三個模塊:圖像預處理、圖像提取、譯碼。如圖2所示。
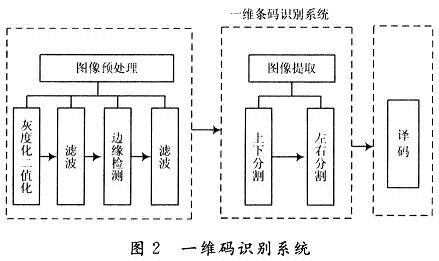
圖像預處理是利用一維條碼的特征對條碼執行灰度化,二值化,濾波和邊緣檢測操作。它為后續的圖像提取做好準備,圖像預處理做得越好,圖像提取效果將更加明顯。
圖像提取是對預處理的圖像進行分割,分為上下分割和左右分割,在各種背景中分割出條碼區域,圖像提取的取決于是否能精確地分割出條碼區域。由于一維條碼是并行長條的,每一條行掃描線都包行了條碼的所有信息,最簡單的方法是只要在條碼圖上確定一根行掃描線,逐個像素判斷,黑的為1,白的為0,計入數組,然后計算寬度就能解碼,這是針對完全干凈的條碼圖的。實際應用的條碼圖像會有很多噪聲,同時條碼區域也不可能完全干凈,因此需要盡量分割出條碼的大部分區域給后續的解碼提供更多的信息,上下分割中把沿條碼方向的部分條碼分割出來,左右分割需把條碼的編碼區全部包含在內。
譯碼是對提取后的條碼區進行處理,計算出條碼中各個條空的寬度,根據一維碼的編碼規則,解出條碼所含的信息。
2.1 圖像預處理
2.1.1 灰度化二值化
灰度處理,為實現數字圖像的閾值變換提供前提條件,要將256色位圖轉變為灰度圖,灰度與RGB值之間的關系為:Y=0.299R+0.587G+O.114B。
二值化是利用點運算中的閾值變換理論將灰度圖轉化為二值圖像。二值化中閾值T的選擇是關鍵,在整幅圖中,我們最關心的是條碼,條碼是由條空(黑白)組成的,根據前面的假設,在整幅圖的中心區域選取50×50個像素點,對其進行灰度處理并得到灰度直方圖,采用雙峰法得到閾值T,此閾值可以有效地把條碼的條空區分出來。按照下式得到二值化圖像g(x,y)。

2.1.2 濾波
由于原圖像各部分亮度不均,背景圖像有不同的情況,得到的二值圖會有很多噪聲,條碼區域有,條碼區域外也有,為了后續部分的條碼提取和條碼譯碼,需要進行濾波處理。考慮到一維條碼的特征:豎直的條和空,采用中值濾波方法,中值濾波模板如圖3所示。被圈部分表示模板遍歷整幅圖時,所對應待檢像素的位置。取待濾波像素上下相鄰的4個像素值,共5個像素值進行排序,用中間值覆蓋待濾波的像素值。此模塊能有效地濾除條碼區的椒鹽噪聲,背景區的噪聲能得到很大抑制。此模塊是根據一維碼的特征設計,可以適合各種一維碼。
2.1.3 邊緣檢測
常用的邊緣檢測算法有梯度算法、Roberts梯度法、Sobel算法和Laplaceian算法等,在充分研究一維條碼的特征后,借鑒各種檢測算法,在此自行設計了一種濾波算法。由于設計實驗時采用的是640×480或320×240的圖像,假設條碼占整個圖像的50 %以上,根據圖2可以算出每個模塊占的像素值為3到4個或l到2個,如果采用3×3或5×5之類的邊緣檢測模板,加上圖像原本的變形,將會誤檢邊緣或邊緣丟失,同時考慮到一維條碼的特征:豎直的條和空,有明顯的豎直邊緣,因此設計了豎直邊緣檢測算法,邊緣檢測模板如圖4所示。

待檢像素的值由其鄰域內10個像素的值決定,這10個值按模板中的權值相加的絕對值為s(x,y)。由于進行邊緣檢測的圖像是二值圖,非黑(0)即白(255),設定邊緣檢測的閾值T1=255×4=1 020,即鄰域內至少有4處黑白突變才能說明待檢像素為一邊緣值,按照下式得到邊緣檢測圖像h(x,y)。
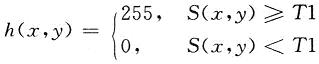
2.2 圖像提取
圖像提取是把圖像中的條碼部分割出來,用于后續的條碼譯碼。圖像提取的步驟分為:上下分割和左右分割。根據條碼的特征,分別設計了上下分割和左右分割的算法。
2.2.1 上下分割
基于前文的假設,設計了如下分割算法,上下分割的流程如圖5(a)所示,此流程的設計應用了條碼的兩個特征:條空數為59個,即邊緣數為60個;條碼的上下部分都有空白區。當然一般情況下,條碼區域所在行肯定還會存在噪聲,因此邊緣數是肯定大于60的,而在條碼上下的空白區所在行經過圖像預處理基本沒多少噪聲,邊緣數基本不會大于60,通過對100幅圖像的試驗只有背景很復雜的2幅圖例外。但是沒分割出來不代表沒譯碼出來,后面譯碼部分對分割有補充修正。根據各種圖像的不同,上下分割不會把整個條碼區域分割出來,但分割出來的圖像信息足以用來解碼。上下分割可以去除圖像中上下部分的非條碼區同時為譯碼減少了計算量。

2.2.2 左右分割
左右分割是在行方向把條碼分割出來,流程如圖5(b)所示,此流程的設計應用了條碼的兩個特征:
(1)條碼的左側空白區有11個模塊,右側空白區有7個模塊;
(2)條碼的起始符為101,結束符為101。
當然圖像一般都會有傾斜,這樣按照x1,x2分割時會把條碼區域有用信息分割掉,因此可以加一個經驗修正,把x1向左移一點,把x2向右移一點。
在檢測101和計算一個模塊的長度時,都是通過邊緣間的距離計算的,由于圖像有變形和扭曲,因此計算長度是要用平均值和比值。
設連續3個邊緣的距離為L1,L2,L3,當0.5 2.3 譯碼 譯碼過程通過對分割后的二值圖進行處理,得到條空的寬度,按照條碼的編碼方式,譯出條碼結果。譯碼步驟如下: (1)對二值圖進行逐行掃描,檢測邊緣數是否為60(EAN-13碼有59條空,60個邊緣),是則記錄下邊緣坐標,否則把這行舍棄; (2)根據每行的邊緣坐標,算出每個條空的寬度:為了減小圖像中的條碼扭曲及其他干擾的影響,計算條空寬度的平均值; (3)按照如下歸一化方法確定條空歸一化寬度。設一個字符(7個模塊)的寬度為W,條空的平均寬度為Wa,則條空的歸一化結果Wg由下式確定: (4)根據條碼左側數據區的奇偶性確定前置碼,如表1所示; (5)根據前置碼確定左側數據區的字符集,右側字符集為C; (6)根據數據區條碼的歸一化寬度,查找字符集,根據表2得出條碼值,譯碼完成; (7)檢校。 此譯碼流程不僅按照編碼標準快速有效的譯出了條碼,同時也起到了濾波作用,把有噪聲的行全部濾除,完成精確解碼。按照上述條碼識別的步驟和算法,用Visual C++編寫了程序。圖6展示從一幅帶有條碼的RGB圖到譯碼的全部過程。 3 結語 對100幅640 x 320圖像進行實驗,解碼率達100%,可以說本文的算法和譯碼步驟有著很好的可靠性,對適當扭曲和污染并有復雜背景的條碼圖有著較好的抗干擾性。在此通過對EAN-13碼特征的分析和掌握,設計了濾波模板,邊緣檢測模板和圖像提取算法,并實現了EAN-13碼的譯碼系統,通過實驗詳細描述了整個解碼過程。此識別系統有以下特點:充分考慮了EAN-13碼的特點,設計了適合該條碼的算法,識讀準確率高,速度快;此系統架構和算法可以很快的應用于其他一維碼的圖像識別中;可以很容易的移植到帶有CMOS攝像頭的各個平臺,實現基于EAN-13碼的各種應用。 






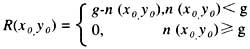









 工商網監
工商網監
評論