 電子發燒友App
電子發燒友App


Java
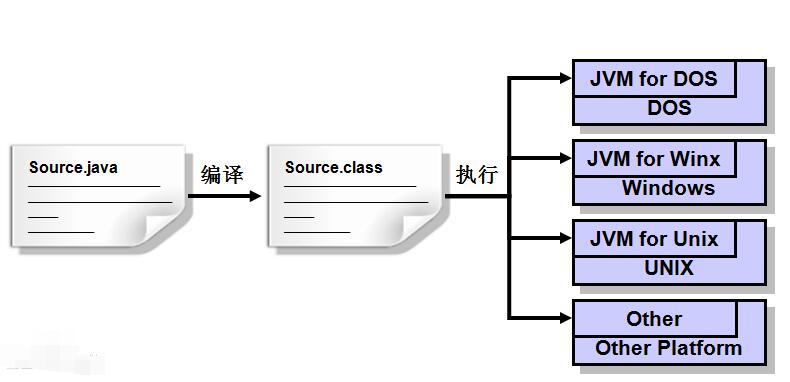
JDK(Java Development Kit)稱為Java開發包或Java開發工具,是一個編寫Java的Applet小程序和應用程序的程序開發環境。JDK是整個Java的核心,包括了Java運行環境(Java Runtime Envirnment),一些Java工具和Java的核心類庫(Java API)。不論什么Java應用服務器實質都是內置了某個版本的JDK。主流的JDK是Sun公司發布的JDK,除了Sun之外,還有很多公司和組織都開發了自己的JDK,例如,IBM公司開發的JDK,BEA公司的Jrocket,還有GNU組織開發的JDK。
另外,可以把Java API類庫中的Java SE API子集和Java虛擬機這兩部分統稱為JRE(JAVA Runtime Environment),JRE是支持Java程序運行的標準環境。
JRE是個運行環境,JDK是個開發環境。因此寫Java程序的時候需要JDK,而運行Java程序的時候就需要JRE。而JDK里面已經包含了JRE,因此只要安裝了JDK,就可以編輯Java程序,也可以正常運行Java程序。但由于JDK包含了許多與運行無關的內容,占用的空間較大,因此運行普通的Java程序無須安裝JDK,而只需要安裝JRE即可[15] 。
編程工具
Eclipse:一個開放源代碼的、基于Java的可擴展開發平臺。
NetBeans:開放源碼的Java集成開發環境,適用于各種客戶機和Web應用。
IntelliJ IDEA:在代碼自動提示、代碼分析等方面的具有很好的功能。
MyEclipse:由Genuitec公司開發的一款商業化軟件,是應用比較廣泛的Java應用程序集成開發環境。
EditPlus:如果正確配置Java的編譯器“Javac”以及解釋器“Java”后,可直接使用EditPlus編譯執行Java程序
理解Java中字符流與字節流的區別
1. 什么是流
Java中的流是對字節序列的抽象,我們可以想象有一個水管,只不過現在流動在水管中的不再是水,而是字節序列。和水流一樣,Java中的流也具有一個“流動的方向”,通常可以從中讀入一個字節序列的對象被稱為輸入流;能夠向其寫入一個字節序列的對象被稱為輸出流。
2. 字節流
Java中的字節流處理的最基本單位為單個字節,它通常用來處理二進制數據。Java中最基本的兩個字節流類是InputStream和OutputStream,它們分別代表了組基本的輸入字節流和輸出字節流。InputStream類與OutputStream類均為抽象類,我們在實際使用中通常使用Java類庫中提供的它們的一系列子類。下面我們以InputStream類為例,來介紹下Java中的字節流。
InputStream類中定義了一個基本的用于從字節流中讀取字節的方法read,這個方法的定義如下:
public abstract int read() throws IOException;
這是一個抽象方法,也就是說任何派生自InputStream的輸入字節流類都需要實現這一方法,這一方法的功能是從字節流中讀取一個字節,若到了末尾則返回-1,否則返回讀入的字節。關于這個方法我們需要注意的是,它會一直阻塞知道返回一個讀取到的字節或是-1。另外,字節流在默認情況下是不支持緩存的,這意味著每調用一次read方法都會請求操作系統來讀取一個字節,這往往會伴隨著一次磁盤IO,因此效率會比較低。有的小伙伴可能認為InputStream類中read的以字節數組為參數的重載方法,能夠一次讀入多個字節而不用頻繁的進行磁盤IO。那么究竟是不是這樣呢?我們來看一下這個方法的源碼:
public int read(byte b[]) throws IOException {
return read(b, 0, b.length);
}
它調用了另一個版本的read重載方法,那我們就接著往下追:
public int read(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if (off 《 0 || len 《 0 || len 》 b.length - off) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return 0;
}
int c = read();
if (c == -1) {
return -1;
}
b[off] = (byte)c;
int i = 1;
try {
for (; i 《 len ; i++) {
c = read();
if (c == -1) {
break;
}
b[off + i] = (byte)c;
}
} catch (IOException ee) {
}
return i;
}
從以上的代碼我們可以看到,實際上read(byte[])方法內部也是通過循環調用read()方法來實現“一次”讀入一個字節數組的,因此本質來說這個方法也未使用內存緩沖區。要使用內存緩沖區以提高讀取的效率,我們應該使用BufferedInputStream。
3. 字符流
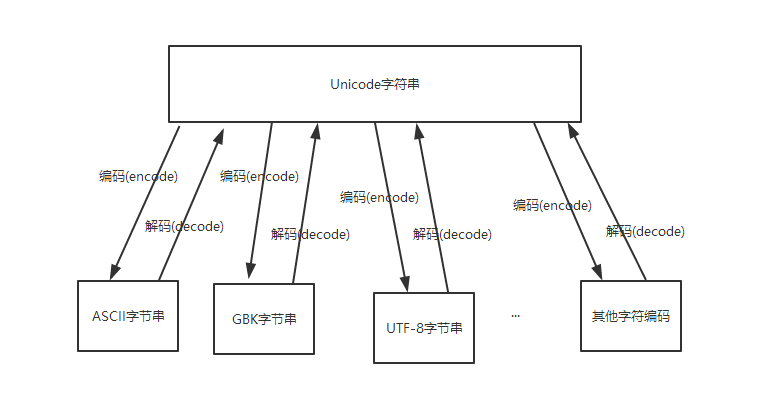
Java中的字符流處理的最基本的單元是Unicode碼元(大小2字節),它通常用來處理文本數據。所謂Unicode碼元,也就是一個Unicode代碼單元,范圍是0x0000~0xFFFF。在以上范圍內的每個數字都與一個字符相對應,Java中的String類型默認就把字符以Unicode規則編碼而后存儲在內存中。然而與存儲在內存中不同,存儲在磁盤上的數據通常有著各種各樣的編碼方式。使用不同的編碼方式,相同的字符會有不同的二進制表示。實際上字符流是這樣工作的:
輸出字符流:把要寫入文件的字符序列(實際上是Unicode碼元序列)轉為指定編碼方式下的字節序列,然后再寫入到文件中;
輸入字符流:把要讀取的字節序列按指定編碼方式解碼為相應字符序列(實際上是Unicode碼元序列從)從而可以存在內存中。
我們通過一個demo來加深對這一過程的理解,示例代碼如下:
import java.io.FileWriter;
import java.io.IOException;
public class FileWriterDemo {
public static void main(String[] args) {
FileWriter fileWriter = null;
try {
try {
fileWriter = new FileWriter(“demo.txt”);
fileWriter.write(“demo”);
} finally {
fileWriter.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
以上代碼中,我們使用FileWriter向demo.txt中寫入了“demo”這四個字符,我們用十六進制編輯器WinHex查看下demo.txt的內容:

從上圖可以看出,我們寫入的“demo”被編碼為了“64 65 6D 6F”,但是我們并沒有在上面的代碼中顯式指定編碼方式,實際上,在我們沒有指定時使用的是操作系統的默認字符編碼方式來對我們要寫入的字符進行編碼。
由于字符流在輸出前實際上是要完成Unicode碼元序列到相應編碼方式的字節序列的轉換,所以它會使用內存緩沖區來存放轉換后得到的字節序列,等待都轉換完畢再一同寫入磁盤文件中。
4. 字符流與字節流的區別
經過以上的描述,我們可以知道字節流與字符流之間主要的區別體現在以下幾個方面:
字節流操作的基本單元為字節;字符流操作的基本單元為Unicode碼元。
字節流默認不使用緩沖區;字符流使用緩沖區。
字節流通常用于處理二進制數據,實際上它可以處理任意類型的數據,但它不支持直接寫入或讀取Unicode碼元;字符流通常處理文本數據,它支持寫入及讀取Unicode碼元。
以上是我對Java中字符流與字節流的一些認識,如有敘述不清晰或是不準確的地方希望大家可以指正,謝謝大家:)
5.字節流與和字符流的使用非常相似,兩者除了操作代碼上的不同之外,是否還有其他的不同呢?實際上字節流在操作時本身不會用到緩沖區(內存),是文件本身直接操作的,而字符流在操作時使用了緩沖區,通過緩沖區再操作文件,如圖12-6所示。
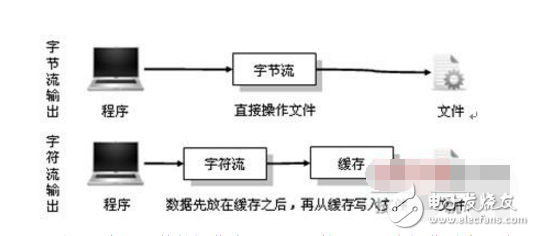
下面以兩個寫文件的操作為主進行比較,但是在操作時字節流和字符流的操作完成之后都不關閉輸出流。
范例:使用字節流不關閉執行
Java代碼 package org.lxh.demo12.byteiodemo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class OutputStreamDemo05 {
public static void main(String[] args) throws Exception { // 異常拋出, 不處理
// 第1步:使用File類找到一個文件
File f = new File(“d:” + File.separator + “test.txt”); // 聲明File 對象
// 第2步:通過子類實例化父類對象
OutputStream out = null;
// 準備好一個輸出的對象
out = new FileOutputStream(f);
// 通過對象多態性進行實例化
// 第3步:進行寫操作
String str = “Hello World!!!”;
// 準備一個字符串
byte b[] = str.getBytes();
// 字符串轉byte數組
out.write(b);
// 將內容輸出
// 第4步:關閉輸出流
// out.close();
// 此時沒有關閉
}
}
程序運行結果:

此時沒有關閉字節流操作,但是文件中也依然存在了輸出的內容,證明字節流是直接操作文件本身的。而下面繼續使用字符流完成,再觀察效果。
范例:使用字符流不關閉執行
Java代碼 package org.lxh.demo12.chariodemo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class WriterDemo03 {
public static void main(String[] args) throws Exception { // 異常拋出, 不處理
// 第1步:使用File類找到一個文件
File f = new File(“d:” + File.separator + “test.txt”);// 聲明File 對象
// 第2步:通過子類實例化父類對象
Writer out = null;
// 準備好一個輸出的對象
out = new FileWriter(f);
// 通過對象多態性進行實例化
// 第3步:進行寫操作
String str = “Hello World!!!”;
// 準備一個字符串
out.write(str);
// 將內容輸出
// 第4步:關閉輸出流
// out.close();
// 此時沒有關閉
}
}
程序運行結果:

程序運行后會發現文件中沒有任何內容,這是因為字符流操作時使用了緩沖區,而 在關閉字符流時會強制性地將緩沖區中的內容進行輸出,但是如果程序沒有關閉,則緩沖區中的內容是無法輸出的,所以得出結論:字符流使用了緩沖區,而字節流沒有使用緩沖區。
提問:什么叫緩沖區?
在很多地方都碰到緩沖區這個名詞,那么到底什么是緩沖區?又有什么作用呢?
回答:緩沖區可以簡單地理解為一段內存區域。
可以簡單地把緩沖區理解為一段特殊的內存。
某些情況下,如果一個程序頻繁地操作一個資源(如文件或數據庫),則性能會很低,此時為了提升性能,就可以將一部分數據暫時讀入到內存的一塊區域之中,以后直接從此區域中讀取數據即可,因為讀取內存速度會比較快,這樣可以提升程序的性能。
在字符流的操作中,所有的字符都是在內存中形成的,在輸出前會將所有的內容暫時保存在內存之中,所以使用了緩沖區暫存數據。
如果想在不關閉時也可以將字符流的內容全部輸出,則可以使用Writer類中的flush()方法完成。
范例:強制性清空緩沖區
Java代碼 package org.lxh.demo12.chariodemo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class WriterDemo04 {
public static void main(String[] args) throws Exception { // 異常拋出不處理
// 第1步:使用File類找到一個文件
File f = new File(“d:” + File.separator + “test.txt”);// 聲明File
對象
// 第2步:通過子類實例化父類對象
Writer out = null;
// 準備好一個輸出的對象
out = new FileWriter(f);
// 通過對象多態性進行實例化
// 第3步:進行寫操作
String str = “Hello World!!!”;
// 準備一個字符串
out.write(str);
// 將內容輸出
out.flush();
// 強制性清空緩沖區中的內容
// 第4步:關閉輸出流
// out.close();
// 此時沒有關閉
}
}
程序運行結果:

此時,文件中已經存在了內容,更進一步證明內容是保存在緩沖區的。這一點在讀者日后的開發中要特別引起注意。
提問:使用字節流好還是字符流好?
學習完字節流和字符流的基本操作后,已經大概地明白了操作流程的各個區別,那么在開發中是使用字節流好還是字符流好呢?
回答:使用字節流更好。
在回答之前,先為讀者講解這樣的一個概念,所有的文件在硬盤或在傳輸時都是以字節的方式進行的,包括圖片等都是按字節的方式存儲的,而字符是只有在內存中才會形成,所以在開發中,字節流使用較為廣泛。
字節流與字符流主要的區別是他們的的處理方式
流分類:
1.Java的字節流
InputStream是所有字節輸入流的祖先,而OutputStream是所有字節輸出流的祖先。
2.Java的字符流
Reader是所有讀取字符串輸入流的祖先,而writer是所有輸出字符串的祖先。
InputStream,OutputStream,Reader,writer都是抽象類。所以不能直接new
字節流是最基本的,所有的InputStream和OutputStream的子類都是,主要用在處理二進制數據,它是按字節來處理的
但實際中很多的數據是文本,又提出了字符流的概念,它是按虛擬機的encode來處理,也就是要進行字符集的轉化
這兩個之間通過 InputStreamReader,OutputStreamWriter來關聯,實際上是通過byte[]和String來關聯
在實際開發中出現的漢字問題實際上都是在字符流和字節流之間轉化不統一而造成的
在從字節流轉化為字符流時,實際上就是byte[]轉化為String時,
public String(byte bytes[], String charsetName)
有一個關鍵的參數字符集編碼,通常我們都省略了,那系統就用操作系統的lang
而在字符流轉化為字節流時,實際上是String轉化為byte[]時,
byte[] String.getBytes(String charsetName)
也是一樣的道理
至于java.io中還出現了許多其他的流,按主要是為了提高性能和使用方便,
如BufferedInputStream,PipedInputStream等

















 工商網監
工商網監
評論