 電子發燒友App
電子發燒友App


即時通訊(Instant Messaging,簡稱IM)是一個實時通信系統,允許兩人或多人使用網絡實時的傳遞文字消息、文件、語音與視頻交流。實現方式有兩種。第一種基于Server轉發的,Client雙方通信會經過Server轉發來完成消息傳遞。例如QQ、微信。
第二種是基于P2P(點對點)的。P2P的實現依賴于客戶端之間的互聯,但由于NAT與防火墻的存在,客戶端無法直接互聯,需要coturn服務器用來穿越NAT網絡。
架構設計
本章主要會介紹基于TableStore的現代IM消息系統的架構設計,在詳細介紹架構設計之前,會先介紹一種Timeline邏輯模型,來抽象和簡化對IM消息同步和存儲模型的理解。理解了Timeline模型后,會介紹如何基于此模型對消息的同步以及存儲進行建模。基于Timeline模型,在實現消息同步和存儲時還會有各方面的技術權衡,例如如何對消息同步常見的讀擴散和寫擴散兩種模型進行對比和選擇,以及針對Timeline模型的特征如何來選擇底層數據庫。
傳統架構 vs 現代架構
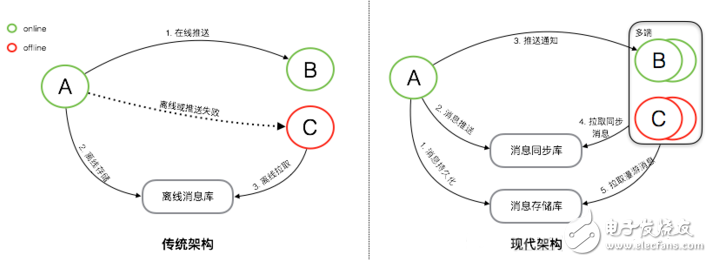
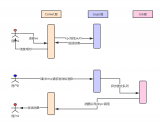
上圖是消息系統傳統架構與現代架構的簡單對比。
傳統架構下,消息是先同步后存儲。對于在線的用戶,消息會直接實時同步到在線的接收方,消息同步成功后,并不會進行持久化。而對于離線的用戶或者消息無法實時同步成功時,消息會持久化到離線庫,當接收方重新連接后,會從離線庫拉取所有未讀消息。當離線庫中的消息成功同步到接收方后,消息會從離線庫中刪除。傳統的消息系統,服務端的主要工作是維護發送方和接收方的連接狀態,并提供在線消息同步和離線消息緩存的能力,保證消息一定能夠從發送方傳遞到接收方。服務端不會對消息進行持久化,所以也無法支持消息漫游。
現代架構下,消息是先存儲后同步。先存儲后同步的好處是,如果接收方確認接收到了消息,那這條消息一定是已經在云端保存了。并且消息會有兩個庫來保存,一個是消息存儲庫,用于全量保存所有會話的消息,主要用于支持消息漫游。另一個是消息同步庫,主要用于接收方的多端同步。消息從發送方發出后,經過服務端轉發,服務端會先將消息保存到消息存儲庫,后保存到消息同步庫。完成消息的持久化保存后,對于在線的接收方,會直接選擇在線推送。但在線推送并不是一個必須路徑,只是一個更優的消息傳遞路徑。對于在線推送失敗或者離線的接收方,會有另外一個統一的消息同步方式。接收方會主動的向服務端拉取所有未同步消息,但接收方何時來同步以及會在哪些端來同步消息對服務端來說是未知的,所以要求服務端必須保存所有需要同步到接收方的消息,這是消息同步庫的主要作用。對于新的同步設備,會有消息漫游的需求,這是消息存儲庫的主要作用,在消息存儲庫中,可以拉取任意會話的全量歷史消息。
以上是傳統架構和現代架構的一個簡單的對比,現代架構上整個消息的同步和存儲流程,并沒有變復雜太多,但是其能實現多端同步以及消息漫游。現代架構中最核心的就是兩個消息庫『消息同步庫』和『消息存儲庫』,是消息同步和存儲最核心的基礎。而本篇文章接下來的部分,都是圍繞這兩個庫的設計和實現來展開。
Timeline模型
在分析『消息同步庫』和『消息存儲庫』的設計和實現之前,在本章會先介紹一個邏輯模型-Timeline。Timeline模型會幫助我們簡化對消息同步和存儲模型的理解,而消息庫的設計和實現也是圍繞Timeline的特性和需求來展開。
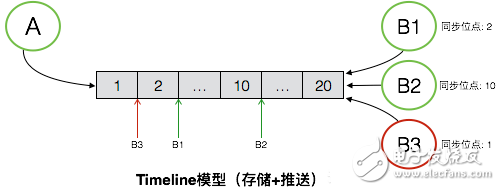
如圖是Timeline模型的一個抽象表述,Timeline可以簡單理解為是一個消息隊列,但這個消息隊列有如下特性:
每個消息擁有一個順序ID(SeqId),在隊列后面的消息的SeqId一定比前面的消息的SeqId大,也就是保證SeqId一定是增長的,但是不要求嚴格遞增。
新的消息永遠在尾部添加,保證新的消息的SeqId永遠比已經存在隊列中的消息都大。
可根據SeqId隨機定位到具體的某條消息進行讀取,也可以任意讀取某個給定范圍內的所有消息。
有了這些特性后,消息的同步可以拿Timeline來很簡單的實現。圖中的例子中,消息發送方是A,消息接收方是B,同時B存在多個接收端,分別是B1、B2和B3。A向B發送消息,消息需要同步到B的多個端,待同步的消息通過一個Timeline來進行交換。A向B發送的所有消息,都會保存在這個Timeline中,B的每個接收端都是獨立的從這個Timeline中拉取消息。每個接收端同步完畢后,都會在本地記錄下最新同步到的消息的SeqId,即最新的一個位點,作為下次消息同步的起始位點。服務端不會保存各個端的同步狀態,各個端均可以在任意時間從任意點開始拉取消息。
消息漫游也是基于Timeline,和消息同步唯一的區別是,消息漫游要求服務端能夠對Timeline內的所有數據進行持久化。
基于Timeline,從邏輯模型上能夠很簡單的理解在服務端如何去實現消息同步和存儲,并支持多端同步和消息漫游這些高級功能。落地到實現的難點主要在如何將邏輯模型映射到物理模型,Timeline的實現對數據庫會有哪些要求?我們應該選擇何種數據庫去實現?這些是接下來會討論到的問題。
消息存儲模型
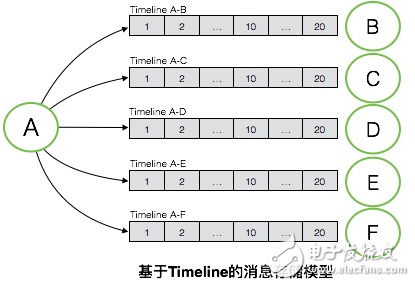
如圖是基于Timeline的消息存儲模型,消息存儲要求每個會話都對應一個獨立的Timeline。如圖例子所示,A與B/C/D/E/F均發生了會話,每個會話對應一個獨立的Timeline,每個Timeline內存有這個會話中的所有消息,服務端會對每個Timeline進行持久化。服務端能夠對所有會話Timeline中的全量消息進行持久化,也就擁有了消息漫游的能力。
消息同步模型
消息同步模型會比消息存儲模型稍復雜一些,消息的同步一般有讀擴散和寫擴散兩種不同的方式,分別對應不同的Timeline物理模型。
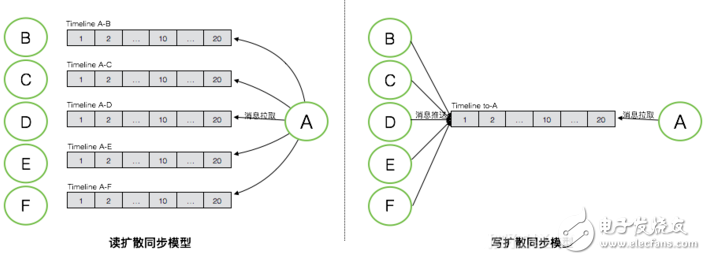
如圖是讀擴散和寫擴散兩種不同同步模式下對應的不同的Timeline模型,按圖中的示例,A作為消息接收者,其與B/C/D/E/F發生了會話,每個會話中的新的消息都需要同步到A的某個端,看下讀擴散和寫擴散兩種模式下消息如何做同步。
讀擴散:消息存儲模型中,每個會話的Timeline中保存了這個會話的全量消息。讀擴散的消息同步模式下,每個會話中產生的新的消息,只需要寫一次到其用于存儲的Timeline中,接收端從這個Timeline中拉取新的消息。優點是消息只需要寫一次,相比寫擴散的模式,能夠大大降低消息寫入次數,特別是在群消息這種場景下。但其缺點也比較明顯,接收端去同步消息的邏輯會相對復雜和低效。接收端需要對每個會話都拉取一次才能獲取全部消息,讀被大大的放大,并且會產生很多無效的讀,因為并不是每個會話都會有新消息產生。
寫擴散:寫擴散的消息同步模式,需要有一個額外的Timeline來專門用于消息同步,通常是每個接收端都會擁有一個獨立的同步Timeline,用于存放需要向這個接收端同步的所有消息。每個會話中的消息,會產生多次寫,除了寫入用于消息存儲的會話Timeline,還需要寫入需要同步到的接收端的同步Timeline。在個人與個人的會話中,消息會被額外寫兩次,除了寫入這個會話的存儲Timeline,還需要寫入參與這個會話的兩個接收者的同步Timeline。而在群這個場景下,寫入會被更加的放大,如果這個群擁有N個參與者,那每條消息都需要額外的寫N次。寫擴散同步模式的優點是,在接收端消息同步邏輯會非常簡單,只需要從其同步Timeline中讀取一次即可,大大降低了消息同步所需的讀的壓力。其缺點就是消息寫入會被放大,特別是針對群這種場景。
在IM這種應用場景下,通常會選擇寫擴散這種消息同步模式。IM場景下,一條消息只會產生一次,但是會被讀取多次,是典型的讀多寫少的場景,消息的讀寫比例大概是10:1。若使用讀擴散同步模式,整個系統的讀寫比例會被放大到100:1。一個優化的好的系統,必須從設計上去平衡這種讀寫壓力,避免讀或寫任意一維觸碰到天花板。所以IM系統這類場景下,通常會應用寫擴散這種同步模式,來平衡讀和寫,將100:1的讀寫比例平衡到30:30。當然寫擴散這種同步模式,還需要處理一些極端場景,例如萬人大群。針對這種極端寫擴散的場景,會退化到使用讀擴散。一個簡單的IM系統,通常會在產品層面限制這種大群的存在,而對于一個高級的IM系統,會采用讀寫擴散混合的同步模式,來滿足這類產品的需求。















 工商網監
工商網監
評論