 電子發(fā)燒友App
電子發(fā)燒友App


一片欣欣向榮背后,深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的瓶頸已至。
提出這個(gè)觀點(diǎn)的,不是外人,正是計(jì)算機(jī)視覺(jué)奠基者之一,約翰霍普金斯大學(xué)教授Alan Yuille,他還是霍金的弟子。
他說(shuō),現(xiàn)在做AI不提神經(jīng)網(wǎng)絡(luò),成果都很難發(fā)表了,這不是個(gè)好勢(shì)頭。
如果人們只追神經(jīng)網(wǎng)絡(luò)的潮流,拋棄所有老方法;如果人們只會(huì)刷榜,不去想怎樣應(yīng)對(duì)深度網(wǎng)絡(luò)的局限性,這個(gè)領(lǐng)域可能很難有更好的發(fā)展。
面對(duì)深度學(xué)習(xí)的三大瓶頸,Yuille教授給出兩條應(yīng)對(duì)之道:靠組合模型培養(yǎng)泛化能力,用組合數(shù)據(jù)測(cè)試潛在的故障。
觀點(diǎn)發(fā)表之后,引發(fā)不少的共鳴。Reddit話題熱度快速超過(guò)200,學(xué)界業(yè)界的AI科學(xué)家們也紛紛在Twitter上轉(zhuǎn)發(fā)。
Reddit網(wǎng)友評(píng)論道,以Yuille教授的背景,他比別人更清楚在深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域現(xiàn)狀如何,為什么出現(xiàn)瓶頸。
深度學(xué)習(xí)的三大瓶頸
Yuille指出,深度學(xué)習(xí)雖然優(yōu)于其他技術(shù),但它不是通用的,經(jīng)過(guò)數(shù)年的發(fā)展,它的瓶頸已經(jīng)凸顯出來(lái),主要有三個(gè):
需要大量標(biāo)注數(shù)據(jù)
深度學(xué)習(xí)能夠?qū)崿F(xiàn)的前提是大量經(jīng)過(guò)標(biāo)注的數(shù)據(jù),這使得計(jì)算機(jī)視覺(jué)領(lǐng)域的研究人員傾向于在數(shù)據(jù)資源豐富的領(lǐng)域搞研究,而不是去重要的領(lǐng)域搞研究。
雖然有一些方法可以減少對(duì)數(shù)據(jù)的依賴,比如遷移學(xué)習(xí)、少樣本學(xué)習(xí)、無(wú)監(jiān)督學(xué)習(xí)和弱監(jiān)督學(xué)習(xí)。但是到目前為止,它們的性能還沒(méi)法與監(jiān)督學(xué)習(xí)相比。
過(guò)度擬合基準(zhǔn)數(shù)據(jù)
深度神經(jīng)網(wǎng)絡(luò)在基準(zhǔn)數(shù)據(jù)集上表現(xiàn)很好,但在數(shù)據(jù)集之外的真實(shí)世界圖像上,效果就差強(qiáng)人意了。
一個(gè)用ImageNet訓(xùn)練來(lái)識(shí)別沙發(fā)的深度神經(jīng)網(wǎng)絡(luò),如果沙發(fā)擺放角度特殊一點(diǎn),就認(rèn)不出來(lái)了。這是因?yàn)椋行┙嵌仍贗mageNet數(shù)據(jù)集里很少見(jiàn)。
在實(shí)際的應(yīng)用中, 如果深度網(wǎng)絡(luò)有偏差,將會(huì)帶來(lái)非常嚴(yán)重的后果。
要知道,用來(lái)訓(xùn)練自動(dòng)駕駛系統(tǒng)的數(shù)據(jù)集中,基本上從來(lái)沒(méi)有坐在路中間的嬰兒。
對(duì)圖像變化過(guò)度敏感
深度神經(jīng)網(wǎng)絡(luò)對(duì)標(biāo)準(zhǔn)的對(duì)抗性攻擊很敏感,這些攻擊會(huì)對(duì)圖像造成人類難以察覺(jué)的變化,但可能會(huì)改變神經(jīng)網(wǎng)絡(luò)對(duì)一個(gè)物體的認(rèn)知。
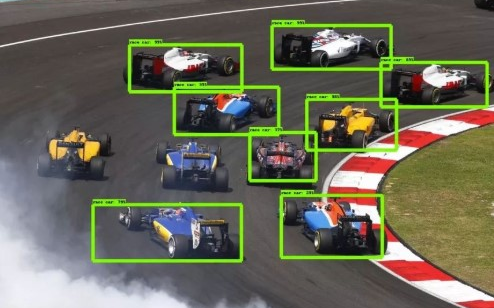
而且,神經(jīng)網(wǎng)絡(luò)對(duì)場(chǎng)景的變化也過(guò)于敏感。比如下面的這張圖,在猴子圖片上放了吉他等物體,神經(jīng)網(wǎng)絡(luò)就將猴子識(shí)別成了人類,吉他識(shí)別成了鳥(niǎo)類。
背后的原因是,與猴子相比,人類更有可能攜帶吉他,與吉他相比,鳥(niǎo)類更容易出現(xiàn)在叢林中。
這種對(duì)場(chǎng)景的過(guò)度敏感,原因在于數(shù)據(jù)集的限制。
對(duì)于任何一個(gè)目標(biāo)對(duì)象,數(shù)據(jù)集中只有有限數(shù)量的場(chǎng)景。在實(shí)際的應(yīng)用中,神經(jīng)網(wǎng)絡(luò)會(huì)明顯偏向這些場(chǎng)景。
對(duì)于像深度神經(jīng)網(wǎng)絡(luò)這樣數(shù)據(jù)驅(qū)動(dòng)的方法來(lái)說(shuō),很難捕捉到各種各樣的場(chǎng)景,以及各種各樣的干擾因素。
想讓深度神經(jīng)網(wǎng)絡(luò)處理所有的問(wèn)題,似乎需要一個(gè)無(wú)窮大的數(shù)據(jù)集,這就給訓(xùn)練和測(cè)試數(shù)據(jù)集帶來(lái)了巨大的挑戰(zhàn)。
為什么數(shù)據(jù)集會(huì)不夠大?
這三大問(wèn)題,還殺不死深度學(xué)習(xí),但它們都是需要警惕的信號(hào)。
Yuille說(shuō),瓶頸背后的原因,就是一個(gè)叫做“組合爆炸”的概念:
就說(shuō)視覺(jué)領(lǐng)域,真實(shí)世界的圖像,從組合學(xué)觀點(diǎn)來(lái)看太大量了。任何一個(gè)數(shù)據(jù)集,不管多大,都很難表達(dá)出現(xiàn)實(shí)的復(fù)雜程度。
那么,組合學(xué)意義上的大,是個(gè)什么概念?
大家想象一下,現(xiàn)在要搭建一個(gè)視覺(jué)場(chǎng)景:你有一本物體字典,要從字典里選出各種各樣的物體,把它們放到不同的位置上。
說(shuō)起來(lái)容易,但每個(gè)人選擇物體、擺放物體的方法都不一樣,搭出的場(chǎng)景數(shù)量是可以指數(shù)增長(zhǎng)的。
就算只有一個(gè)物體,場(chǎng)景還是能指數(shù)增長(zhǎng)。因?yàn)椋梢杂们姘俟值姆绞奖徽趽酰晃矬w所在的背景也有無(wú)窮多種。
人類的話,能夠自然而然適應(yīng)背景的變化;但深度神經(jīng)網(wǎng)絡(luò)對(duì)變化就比較敏感了,也更容易出錯(cuò):
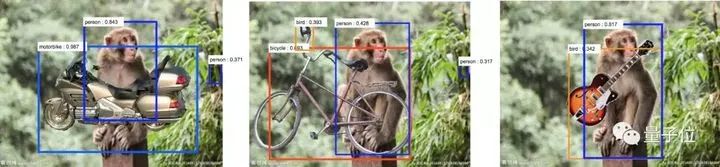
△?是的,前面出現(xiàn)過(guò)了
也不是所有視覺(jué)任務(wù)都會(huì)發(fā)生組合爆炸?(Combinatorial Explosion) 。
比如,醫(yī)學(xué)影像就很適合用深度網(wǎng)絡(luò)來(lái)處理,因?yàn)楸尘吧儆凶兓罕热纾认偻ǔ6紩?huì)靠近十二指腸。
但這樣的應(yīng)用并不常見(jiàn),復(fù)雜多變的情況在現(xiàn)實(shí)中更普遍。如果沒(méi)有指數(shù)意義上的大數(shù)據(jù)集,就很難模擬真實(shí)情況。
而在有限的數(shù)據(jù)集上訓(xùn)練/測(cè)試出來(lái)的模型,會(huì)缺乏現(xiàn)實(shí)意義:因?yàn)閿?shù)據(jù)集不夠大,代表不了真實(shí)的數(shù)據(jù)分布。
那么,就有兩個(gè)新問(wèn)題需要重視:
1、怎樣在有限的數(shù)據(jù)集里訓(xùn)練,才能讓AI在復(fù)雜的真實(shí)世界里也有很好的表現(xiàn)?
2、怎樣在有限的數(shù)據(jù)集里,高效地給算法做測(cè)試,才能保證它們承受得了現(xiàn)實(shí)里大量數(shù)據(jù)的考驗(yàn)?
組合爆炸如何應(yīng)對(duì)?
數(shù)據(jù)集是不會(huì)指數(shù)型長(zhǎng)大的,所以要試試從別的地方突破。
可以訓(xùn)練一個(gè)組合模型,培養(yǎng)泛化能力。也可以用組合數(shù)據(jù)來(lái)測(cè)試模型,找出容易發(fā)生的故障。
總之,組合是關(guān)鍵。
訓(xùn)練組合模型
組合性 (Compositionality) 是指,一個(gè)復(fù)雜的表達(dá),它的意義可以通過(guò)各個(gè)組成部分的意義來(lái)決定。
這里,一個(gè)重要的假設(shè)就是,一個(gè)結(jié)構(gòu)是由許多更加基本的子結(jié)構(gòu),分層組成的;背后有一些語(yǔ)法規(guī)則。
這就表示,AI可以從有限的數(shù)據(jù)里,學(xué)會(huì)那些子結(jié)構(gòu)和語(yǔ)法,再泛化到各種各樣的情景里。
與深度網(wǎng)絡(luò)不同,組合模型 (Compositional Models) 需要結(jié)構(gòu)化的表示方式,才能讓結(jié)構(gòu)和子結(jié)構(gòu)更明確。
組合模型的推斷能力,可以延伸到AI見(jiàn)過(guò)的數(shù)據(jù)之外:推理、干預(yù)、診斷,以及基于現(xiàn)有知識(shí)結(jié)構(gòu)去回答不同的問(wèn)題。
引用Stuart German的一句話:
The world is compositional or God exists. 世界是組合性的,不然,上帝就是存在的。
雖然,深度神經(jīng)網(wǎng)絡(luò)也有些組合性:高級(jí)特征是由低級(jí)特征的響應(yīng)組成的;但在本文所討論的意義上,深度神經(jīng)網(wǎng)絡(luò)并不是組合性的。
組合模型的優(yōu)點(diǎn)已經(jīng)在許多視覺(jué)任務(wù)里面體現(xiàn)了:比如2017年登上Science的、用來(lái)識(shí)別CAPTCHA驗(yàn)證碼的模型。
還有一些理論上的優(yōu)點(diǎn),比如可解釋,以及可以生成樣本。這樣一來(lái),研究人員就更加容易發(fā)現(xiàn)錯(cuò)誤在哪,而不像深度神經(jīng)網(wǎng)絡(luò)是個(gè)黑盒,誰(shuí)也不知道里面發(fā)生了什么。
但要學(xué)習(xí)組合模型,并不容易。因?yàn)檫@里需要學(xué)習(xí)所有的組成部分和語(yǔ)法;
還有,如果要通過(guò)合成 (Synthesis) 來(lái)作分析,就需要有生成模型?(Generative Models) 來(lái)生成物體和場(chǎng)景結(jié)構(gòu)。
就說(shuō)圖像識(shí)別,除了人臉、字母等等少數(shù)幾種很有規(guī)律的圖案之外,其他物體還很難應(yīng)付:
從根本上說(shuō),要解決組合爆炸的問(wèn)題,就要學(xué)習(xí)3D世界的因果模型?(Causal Models) ,以及這些模型是如何生成圖像的。
有關(guān)人類嬰兒的研究顯示,他們是通過(guò)搭建因果模型來(lái)學(xué)習(xí)的,而這些模型可以預(yù)測(cè)他們生活環(huán)境的結(jié)構(gòu)。
對(duì)因果關(guān)系的理解,可以把從有限數(shù)據(jù)里學(xué)到的知識(shí),有效擴(kuò)展到新場(chǎng)景里去。
在組合數(shù)據(jù)里測(cè)試模型
訓(xùn)練過(guò)后,該測(cè)試了。
前面說(shuō)過(guò),世界那么復(fù)雜,而我們只能在有限的數(shù)據(jù)上測(cè)試算法。
要處理組合數(shù)據(jù) (Combinatorial Data) ,博弈論是一種重要的方法:它專注于最壞情況?(Worst Case) ,而不是平均情況 (Average Case) 。
就像前面討論過(guò)的那樣,如果數(shù)據(jù)集沒(méi)有覆蓋到問(wèn)題的組合復(fù)雜性,用平均情況討論出的結(jié)果可能缺乏現(xiàn)實(shí)意義。
而關(guān)注最壞情況,在許多場(chǎng)景下都是有意義的:比如自動(dòng)駕駛汽車的算法,比如癌癥診斷的算法。因?yàn)樵谶@些場(chǎng)景下,算法故障可能帶來(lái)嚴(yán)重的后果。
如果,能在低維空間里捕捉到故障模式 (Failure Modes) ,比如立體視覺(jué)的危險(xiǎn)因子 (Hazard Factors) ,就能用圖形和網(wǎng)格搜索來(lái)研究這些故障。
但是對(duì)于大多數(shù)視覺(jué)任務(wù),特別是那些涉及組合數(shù)據(jù)的任務(wù),通常不會(huì)有能找出幾個(gè)危險(xiǎn)因子、隔離出來(lái)單獨(dú)研究的簡(jiǎn)單情況。
△?對(duì)抗攻擊:稍稍改變紋理,只影響AI識(shí)別,不影響人類
有種策略,是把標(biāo)準(zhǔn)對(duì)抗攻擊?(Adversarial Attacks) 的概念擴(kuò)展到包含非局部結(jié)構(gòu)?(Non-Local Structure) ,支持讓圖像或場(chǎng)景發(fā)生變化的復(fù)雜運(yùn)算,比如遮擋,比如改變物體表面的物理性質(zhì),但不要對(duì)人類的認(rèn)知造成重大改變。
把這樣的方法應(yīng)用到視覺(jué)算法上,還是很有挑戰(zhàn)性的。
不過(guò),如果算法是用組合性?(Compositional) 的思路來(lái)寫(xiě),清晰的結(jié)構(gòu)可能會(huì)給算法故障檢測(cè)帶來(lái)很大的幫助。
關(guān)于Alan Yuille
Alan Yuille,目前就職于約翰霍普金斯大學(xué),是認(rèn)知科學(xué)和計(jì)算機(jī)科學(xué)的杰出教授。
1976年,在劍橋大學(xué)數(shù)學(xué)專業(yè)獲得學(xué)士學(xué)位。之后師從霍金,在1981年獲得理論物理博士學(xué)位。
畢業(yè)之后,轉(zhuǎn)而開(kāi)拓計(jì)算機(jī)視覺(jué)領(lǐng)域。并先后就職于麻省理工學(xué)院的人工智能實(shí)驗(yàn)室,哈佛大學(xué)計(jì)算機(jī)系等等學(xué)術(shù)機(jī)構(gòu)。
2002年加入U(xiǎn)CLA,之后擔(dān)任視覺(jué)識(shí)別與機(jī)器學(xué)習(xí)中心主任,同時(shí)也在心理學(xué)系,計(jì)算機(jī)系,精神病學(xué)和生物行為學(xué)系任客座教授。
2016年,加入約翰霍普金斯大學(xué)。
他曾獲得ICCV的最佳論文獎(jiǎng),2012年,擔(dān)任計(jì)算機(jī)視覺(jué)頂級(jí)會(huì)議CVPR的主席,計(jì)算機(jī)視覺(jué)界的奠基人之一。
此外,Alan Yuille也直接影響了中國(guó)AI的發(fā)展,其嫡系弟子朱瓏博士學(xué)成后,回國(guó)創(chuàng)辦了AI公司依圖科技,現(xiàn)在也是中國(guó)CV領(lǐng)域最知名的創(chuàng)業(yè)公司之一。
這篇文章中的觀點(diǎn),出自Yuille在2018年5月發(fā)表的一篇論文,共同作者是他的博士生Chenxi Liu,在今年一月份,他們對(duì)這篇論文進(jìn)行了更新。
作者:mileistone?
因?yàn)槲覍?duì)計(jì)算機(jī)視覺(jué)比較熟,就從計(jì)算機(jī)視覺(jué)的角度說(shuō)一下自己對(duì)深度學(xué)習(xí)瓶頸的看法。
一、深度學(xué)習(xí)缺乏理論支撐 大多數(shù)文章的idea都是靠直覺(jué)提出來(lái)的,背后的很少有理論支撐。通過(guò)實(shí)驗(yàn)驗(yàn)證有效的idea,不一定是最優(yōu)方向。就如同最優(yōu)化問(wèn)題中的sgd一樣,每一個(gè)step都是最優(yōu),但從全局來(lái)看,卻不是最優(yōu)。
沒(méi)有理論支撐的話,計(jì)算機(jī)視覺(jué)領(lǐng)域的進(jìn)步就如同sgd一樣,雖然有效,但是緩慢;如果有了理論支撐,計(jì)算機(jī)視覺(jué)領(lǐng)域的進(jìn)步就會(huì)像牛頓法一樣,有效且迅猛。
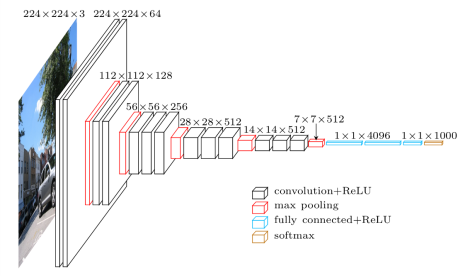
CNN模型本身有很多超參數(shù),比如設(shè)置幾層,每一層設(shè)置幾個(gè)filter,每個(gè)filter是depth wise還是point wise,還是普通conv,filter的kernel size設(shè)置多大等等。
這些超參數(shù)的組合是一個(gè)很大的數(shù)字,如果只靠實(shí)驗(yàn)來(lái)驗(yàn)證,幾乎是不可能完成的。最后只能憑直覺(jué)試其中一部分組合,因此現(xiàn)在的CNN模型只能說(shuō)效果很好,但是絕對(duì)還沒(méi)達(dá)到最優(yōu),無(wú)論是效果還是效率。
以效率舉例,現(xiàn)在resnet效果很好,但是計(jì)算量太大了,效率不高。然而可以肯定的是resnet的效率可以提高,因?yàn)閞esnet里面肯定有冗余的參數(shù)和冗余的計(jì)算,只要我們找到這些冗余的部分,并將其去掉,效率自然提高了。一個(gè)最簡(jiǎn)單而且大多人會(huì)用的方法就是減小各層channel的數(shù)目。
如果一套理論可以估算模型的capacity,一個(gè)任務(wù)所需要模型的capacity。那我們面對(duì)一個(gè)任務(wù)的時(shí)候,使用capacity與之匹配的模型,就能使得效果好,效率優(yōu)。
二、領(lǐng)域內(nèi)越來(lái)越工程師化思維 因?yàn)樯疃葘W(xué)習(xí)本身缺乏理論,深度學(xué)習(xí)理論是一塊難啃的骨頭,深度學(xué)習(xí)框架越來(lái)越傻瓜化,各種模型網(wǎng)上都有開(kāi)源實(shí)現(xiàn),現(xiàn)在業(yè)內(nèi)很多人都是把深度學(xué)習(xí)當(dāng)樂(lè)高用。
面對(duì)一個(gè)任務(wù),把當(dāng)前最好的幾個(gè)模型的開(kāi)源實(shí)現(xiàn)git clone下來(lái),看看這些模型的積木搭建說(shuō)明書(shū)(也就是論文),思考一下哪塊積木可以改一改,積木的順序是否能調(diào)換一樣,加幾個(gè)積木能不能讓效果更好,減幾個(gè)積木能不能讓效率更高等等。
思考了之后,實(shí)驗(yàn)跑起來(lái),實(shí)驗(yàn)效果不錯(cuò),文章發(fā)起來(lái),實(shí)驗(yàn)效果不如預(yù)期,重新折騰一遍。
這整個(gè)過(guò)程非常的工程師化思維,基本就是憑感覺(jué)trial and error,深度思考缺位。很少有人去從理論的角度思考模型出了什么問(wèn)題,針對(duì)這個(gè)問(wèn)題,模型應(yīng)該做哪些改進(jìn)。
舉一個(gè)極端的例子,一個(gè)數(shù)據(jù)實(shí)際上是一次函數(shù),但是我們卻總二次函數(shù)去擬合,發(fā)現(xiàn)擬合結(jié)果不好,再用三次函數(shù)擬合,三次不行,四次,再不行,就放棄。我們很少思考,這個(gè)數(shù)據(jù)是啥分布,針對(duì)這樣的分布,有沒(méi)有函數(shù)能擬合它,如果有,哪個(gè)函數(shù)最合適。
深度學(xué)習(xí)本應(yīng)該是一門(mén)科學(xué),需要用科學(xué)的思維去面對(duì)她,這樣才能得到更好的結(jié)果。
三、對(duì)抗樣本是深度學(xué)習(xí)的問(wèn)題,但不是深度學(xué)習(xí)的瓶頸 我認(rèn)為對(duì)抗樣本雖然是深度學(xué)習(xí)的問(wèn)題,但并不是深度學(xué)習(xí)的瓶頸。機(jī)器學(xué)習(xí)中也有對(duì)抗樣本,機(jī)器學(xué)習(xí)相比深度學(xué)習(xí)有著更多的理論支撐,依然沒(méi)能把對(duì)抗樣本的問(wèn)題解決。
之所以我們覺(jué)得對(duì)抗樣本是深度學(xué)習(xí)的瓶頸是因?yàn)椋瑘D像很直觀,當(dāng)我們看到兩張幾乎一樣的圖片,最后深度學(xué)習(xí)模型給出兩種完全不一樣的分類結(jié)果,這給我們的沖擊很大。
如果修改一個(gè)原本類別是A的feature中某個(gè)元素的值,然后使得svm的分類改變?yōu)锽,我們會(huì)覺(jué)得不以為然,“你改變了這個(gè)feature中某個(gè)元素的值,它的分類結(jié)果改變很正常啊”。
作者:PENG Bo?
個(gè)人認(rèn)為,當(dāng)前深度學(xué)習(xí)的瓶頸,可能在于 scaling。是的,你沒(méi)有聽(tīng)錯(cuò)。
我們已經(jīng)有海量的數(shù)據(jù),海量的算力,但我們卻難以訓(xùn)練大型的深度網(wǎng)絡(luò)模型(GB 到 TB 級(jí)別的模型),因?yàn)?BP 難以大規(guī)模并行化。數(shù)據(jù)并行不夠,用模型并行后加速比就會(huì)大打折扣。即使在加入諸多改進(jìn)后,訓(xùn)練過(guò)程對(duì)帶寬的要求仍然太高。
這就是為什么 nVidia 的 DGX-2 只有 16 塊 V100,但就是要賣到 250 萬(wàn)。因?yàn)殡m然用少得多的錢(qián)就可以湊出相同的總算力,但很難搭出能高效運(yùn)用如此多張顯卡的機(jī)器。
而且 DGX-2 內(nèi)部的 GPU 也沒(méi)有完全互聯(lián):
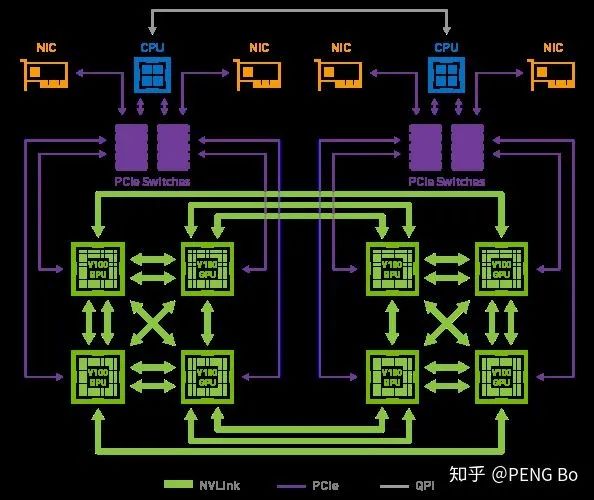
又例如 AlphaGo Zero 的訓(xùn)練,實(shí)際用于訓(xùn)練的只是很少的 TPU。即使有幾千幾萬(wàn)張 TPU,也并沒(méi)有辦法將他們高效地用于訓(xùn)練網(wǎng)絡(luò)。
如果什么時(shí)候深度學(xué)習(xí)可以無(wú)腦堆機(jī)器就能不斷提高訓(xùn)練速度(就像挖礦可以堆礦機(jī)),從而可以用超大規(guī)模的多任務(wù)網(wǎng)絡(luò),學(xué)會(huì) PB EB 級(jí)別的各類數(shù)據(jù),那么所能實(shí)現(xiàn)的效果很可能會(huì)是令人驚訝的。
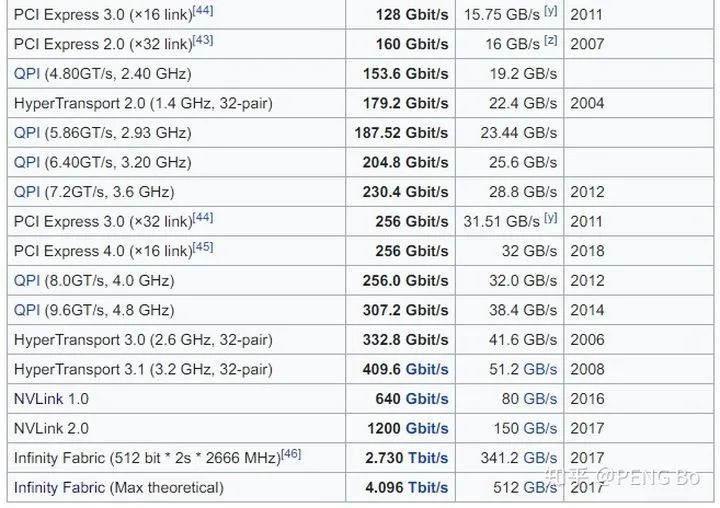
那么我們看現(xiàn)在的帶寬:
https://en.wikipedia.org/wiki/List_of_interface_bit_rates
2011年出了PCI-E 3.0 x16,是 15.75 GB/s,現(xiàn)在消費(fèi)級(jí)電腦還是這水平,4.0還是沒(méi)出來(lái),不過(guò)可能是因?yàn)榇蠹覜](méi)動(dòng)力(游戲?qū)捯鬀](méi)那么高)。
NVLink 2.0是 150 GB/s,對(duì)于大型并行化還是完全不夠的。
大家可能會(huì)說(shuō),帶寬會(huì)慢慢提上來(lái)的。
很好,那么,這就來(lái)到了最奇怪的問(wèn)題,我想這個(gè)問(wèn)題值得思考:
AI芯片花了這么大力氣還是帶寬受限,那么人腦為何沒(méi)有受限于帶寬?
我的想法是:
人腦的并行化做得太好了,因此神經(jīng)元之間只需要kB級(jí)的帶寬。值得AI芯片和算法研究者學(xué)習(xí)。
人腦的學(xué)習(xí)方法比BP粗糙得多,所以才能這樣大規(guī)模并行化。
人腦的學(xué)習(xí)方法是去中心化的,個(gè)人認(rèn)為,更接近 energy-based 的方法。
人腦的其它特點(diǎn),用現(xiàn)在的遷移學(xué)習(xí)+多任務(wù)學(xué)習(xí)+持續(xù)學(xué)習(xí)已經(jīng)可以模仿。
人腦還會(huì)用語(yǔ)言輔助思考。如果沒(méi)有語(yǔ)言,人腦也很難快速學(xué)會(huì)復(fù)雜的事情。
編輯:黃飛
?


















 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論