 電子發燒友App
電子發燒友App


隨著經濟的快速發展,中國機動車保有量突破4.26億輛,成為全球機動車保有量最大的國家,汽車數量的急劇增加導致各類交通事故頻發,造成大量的財產損失和人員傷亡,給社會帶來了巨大的安全隱患。在以往的交通事故中,由于高疲勞、接打電話分心等駕駛員狀態造成的交通事故占比龐大,已經成為威脅生命安全的最大殺手。因此,如何精準預測駕駛員狀態進而提高車輛駕駛安全性已成為人們關注的焦點。
有研究表明,人-車-路多模態特征融合在駕駛員狀態識別中的準確率優于其他單模態的特征,其中駕駛員的生理特征和車輛運行狀態的特征較易獲取,但基于圖像資料對駕駛員的行為及道路狀況等特征的提取仍然面臨著一些挑站,隨著計算機視覺的發展,圖像檢測技術的應用已經為解決這一難題提供了有力的幫助。
01 ? 基于駕駛員-車輛-道路信息的駕駛員狀態識別
首先,駕駛場景的核心三要素為駕駛員、汽車和和道路信息。在外部信息的干擾下,以駕駛員為核心感知道路狀況和車輛狀態,作出正確決策并執行是保證車輛安全運行的關鍵。有研究表明,90% 以上的交通事故與駕駛員的狀態相關,如果我們能夠實時的監測到駕駛員的狀態并及時給予合適的預警將會大大降低交通事故的發生概率,減少人員傷亡和財產損失。
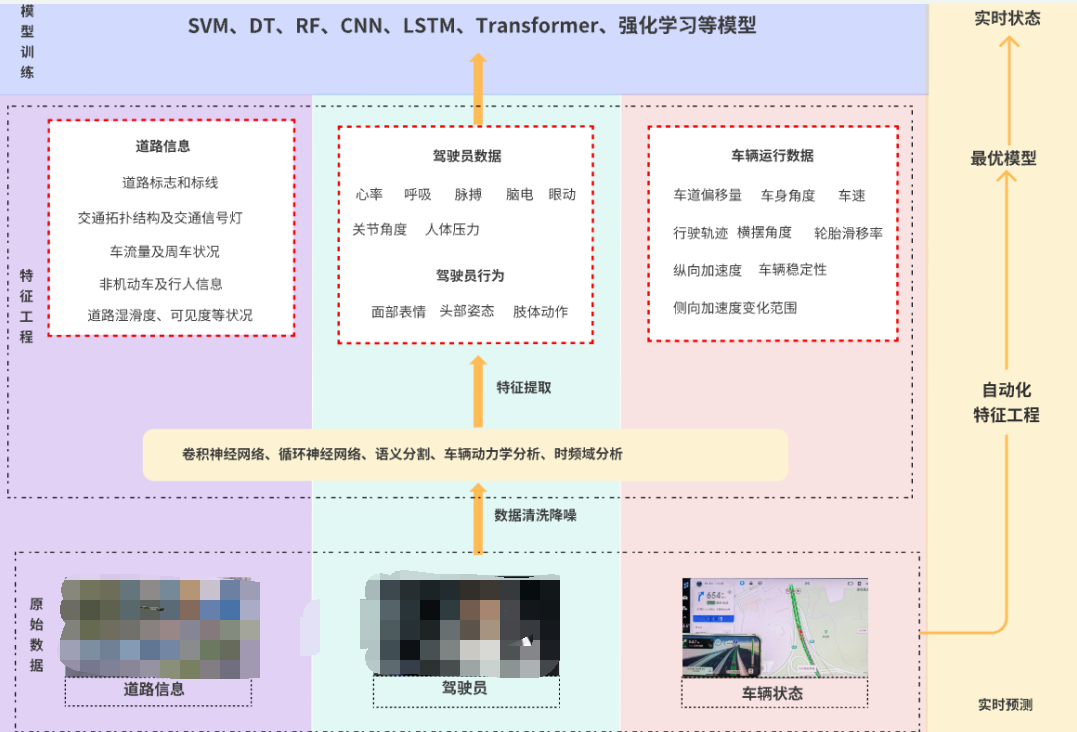
利用人-車-路多模態特征進行駕駛員狀態識別的技術路線如下圖所示:
1首先,將通過多模態生理、眼動、生物力學等傳感器采集到的駕駛員的生理數據,踏板、GPS、IMU及CAN協議采集到的車輛運行數據,音視頻采集到的駕駛員的行為及道路環境數據進行數據降噪。 2其次,利用卷積神經網絡和循環神網絡等深度學習算法,傅里葉變換和拉普拉斯空間濾波等生理信號分析算法,進行多模態人-車-路特征提取,并根據問卷量表等方式進行標簽設置。 2接著,采用特征級融合、決策級融合或者混合融合等不同的方式對特征進行融合,采用主成分分析,方差分析等方式進行特征篩選,構建數據集。 3然后,將最終構建的數據集輸入算法模型中訓練,并根據模型評估結果進行參數調整,找到最優模型。 4最后,利用滑動窗口的方式對實時采集的多模態原始數據進行自動化特征提取,輸入到最優模型中進行預測,輸出駕駛員的實時狀態。
02 ? 機器視覺技術在人車路特征提取中的應用
針對基于圖像資料對駕駛員的行為及道路狀況等特征的提取問題,目前比較流行的兩個思路為圖像分類模型和目標檢測模型,圖像分類模型特別適合用于靜態場景的行為判別,比如駕駛員是否系安全帶。目標檢測模型能夠定位目標的位置,適合需要精確定位和目標檢測的場景,如檢測道路上的速限標志、停車標志、路線指示、交通流量等信息,下文將圍繞這兩個維度對相關的模型展開介紹。
01 MSA-CNN模型與駕駛員行為特征提取 ?
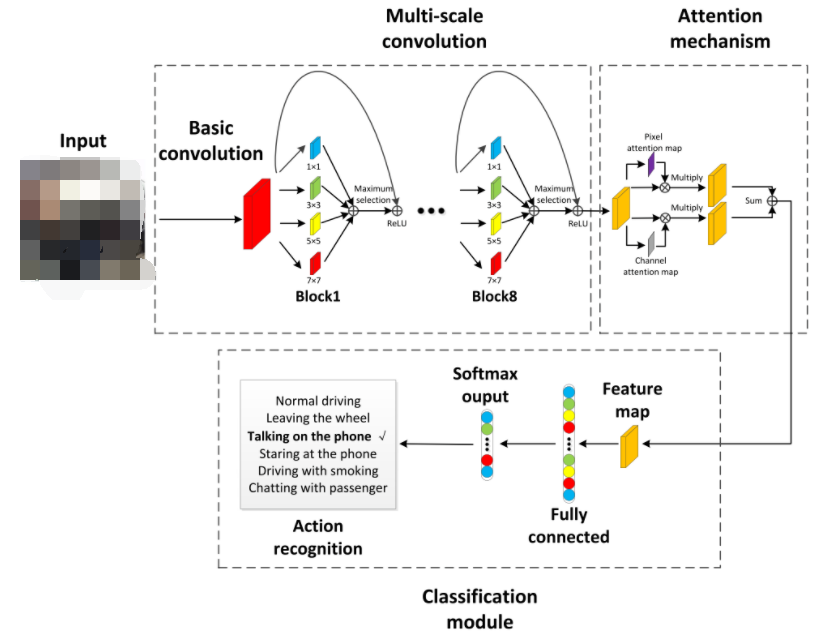
駕駛員在行駛過程中的喝水、打電話和抽煙等注意力分散行為會嚴重的影響道路安全,對這些行為的精準識別在智能駕駛領域有著重要的意義。基于多尺度注意力機制的卷積網絡模型(MSA-CNN)具備輕量化處理和視覺注意力機制等特點,輕量化技術在保證高精度的同時減少了模型的參數量,降低了計算復雜度。視覺注意力機制有利于抑制全局背景信息的干擾,更有效的抽取細粒度行為特征,上述兩個特點有效的提高了該模型對駕駛員行為的辨識能力。
MSA-CNN模型結構 基于多尺度注意力機制的卷積網絡模型(MSA-CNN)包括三個模塊,分別是多尺度卷積模塊、特征強化模塊和分類模型,其中多尺度卷積模塊和特征強化模塊是其核心。
? 01多尺度卷積模塊構成 ?
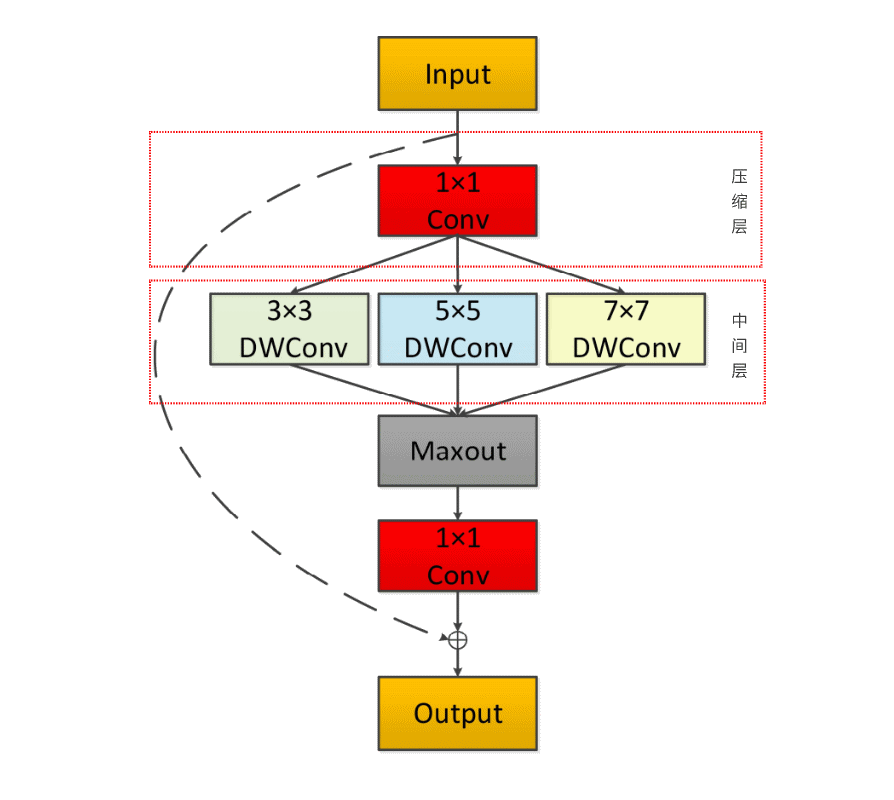
多尺度卷積網絡模塊采用了輕量化的多尺度卷積單元LMCU(light-weight Multi-scale Convolution Unit,LMCU)用于從靜態圖像中提取細粒度的駕駛員行為特征。
1LMCU模塊首先使用了先通道升維后通道降維的Bottleneck結構,在減少模型參數的同時提高模型的性能。 2壓縮層為1×1的卷積網絡,能夠減少特征圖的通道數。 3Bottleneck Layer是模型的中間層包括3×3,5×5,7×7三種深度可分離卷積核,可以同時捕獲不同尺度的特征,提高模型對多尺度信息的敏感性。 4隨后使用Maxout激活函數對特征進行融合,以促進多尺度信息的交互。 5最后,輸出層采用了Residual Unit的跳躍機制進行連接,減輕梯度消失問題,提高網絡的訓練收斂性
? 02多尺度卷積模塊的優勢 ?
普通卷積的每個通道都要經過一個不一樣的卷積核卷積,然后對得到的所有數據進行相加得到一個新的通道,也就是說經過普通卷積得到的新一層的特征,其每個通道都整合了上一層網絡中所有通道的信息,每個輸出通道都需要一組與原通道數量相同的卷積核來進行卷積。
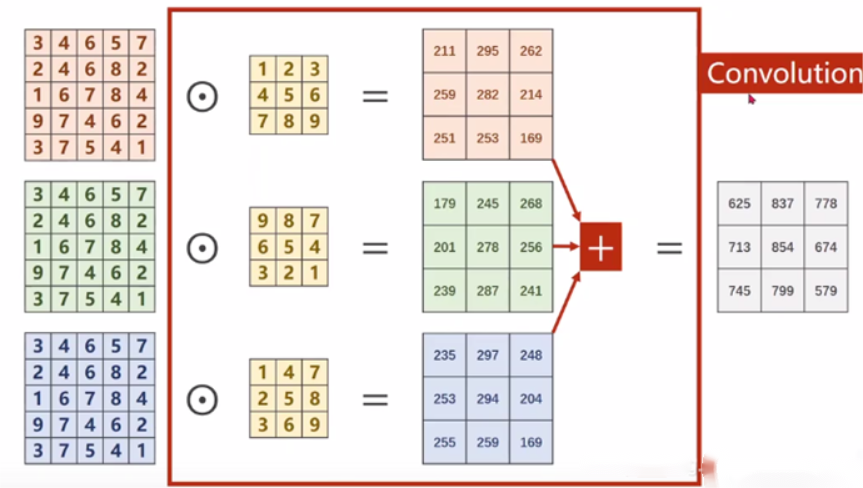
深度可分離卷積包括深度卷積和1×1卷積,深度卷積的每個通道在經過卷積核后并沒有進行相加的操作,根據卷積核個數的不同,一個輸入通道既可以對應一個輸出通道,也可以對應多個輸出通道,即可以對一個通道進行多次信息提取。
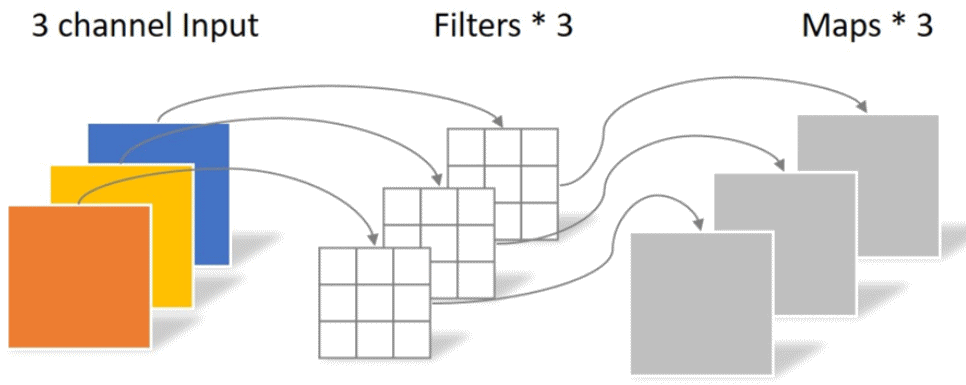
在經過上述處理后,存在兩個問題,首先是通道的數量無法變化,其次輸出通道只包含了對應輸入通道的信息,沒有包含所有輸入通道的信息,沒有起到信息整合的作用。所以進行了逐點卷積,采用1×1×M的卷積核,M為上一層的通道數,這種卷積運算會將上一層的特征圖在深度方向上進行加權組合,生成新的特征圖,有幾個卷積核就會輸出幾個特征圖。
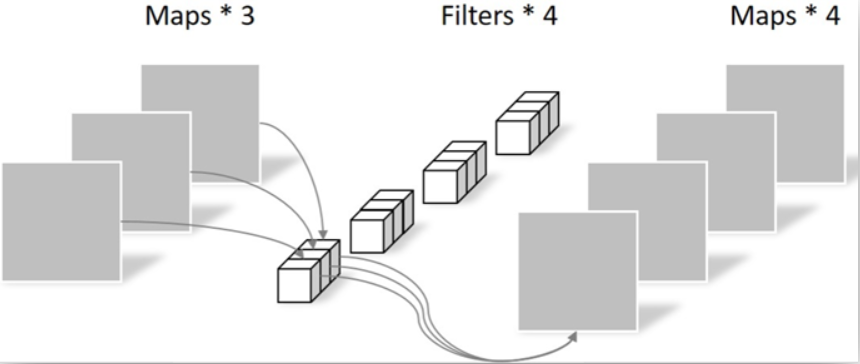
特征圖經過3×3、5×5、7×7的可分離卷積運算之后即可獲得一組多尺度的特征集合,LMCU采用了Maxout激活函數融合多尺度信息,接著,對融合之后的特征圖進行Batch normalization和RELU處理,輸出處理后的特征圖,并使用1*1的卷積對融合之后的特征圖進行降維處理,再使用跳躍連接機制,對結果與原始值進行連接輸出。
03特征強化網絡模塊 ?
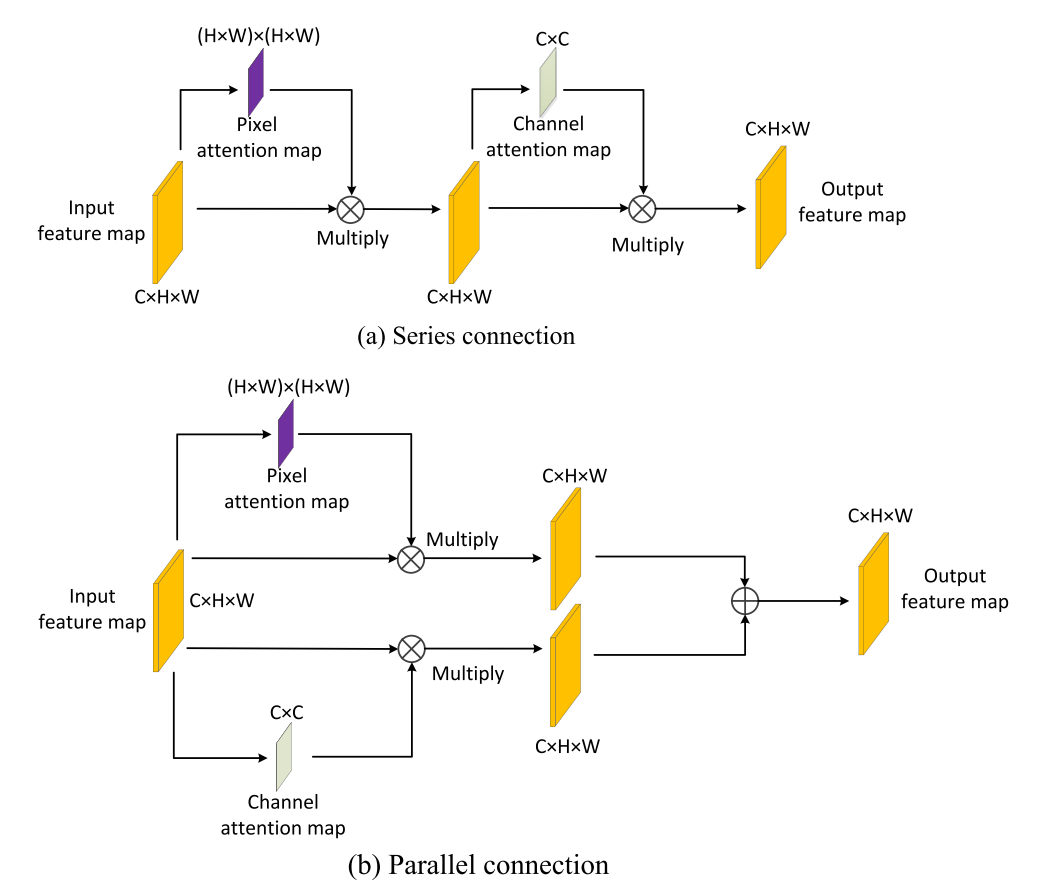
特征強化網絡模塊采用了空間注意力機制和通道注意力機制,其中空間注意力機制用于衡量圖像中不同像素區域的顯著性,通道注意力機制更多的關注不同特征圖之間的相互依賴關系。空間注意力機制和通道注意力機制通常包括系列融合和并聯融合兩種方式,研究表明并聯融合的方式更好。
? 04分類網絡模塊 ?
分類網絡模塊包含全連接層和softmax分類器,全連接層用于特征學習及數據的扁平化處理,softmax分類器用于特征分類并估計不同類別的概率分布,最終輸出駕駛員行為識別結果。
05模型性能評估 ?
本研究從識別精度和計算效率兩個方面評估了MSA-CNN模型的性能,并與現有的駕駛員行為識別方法和模型做了對比,表明MSA-CNN模型在大部分數據集上的精確度高于其他對比方法,計算效率較高,處理速度達到了25fps,且達到了準確率和計算時間的良好平衡。
02RefineDet模型與道路特征提取 ?
交通標識的準確識別在日常出行中具有重要意義,它能夠為駕駛員提供及時的交通規則信息,避免道路擁堵,促進駕駛規范,提高道路安全。交通標識檢測和識別的核心技術是目標檢測,然而在對交通標識進行檢測時,通常面臨三個嚴峻的挑戰,首先,交通標識的尺寸通常比較小,在原始圖像中所占的比例也有限,進行檢測時輸出的特征包含的信息也相對較少,從而導致漏檢或者誤檢。其次,相似性交通標識比較多,每一大類交通標識有相同的顏色或者形狀,這種情況下就比較容易出現誤檢現象。同時,駕駛中速度一般較高,對時效性的要求也較高。
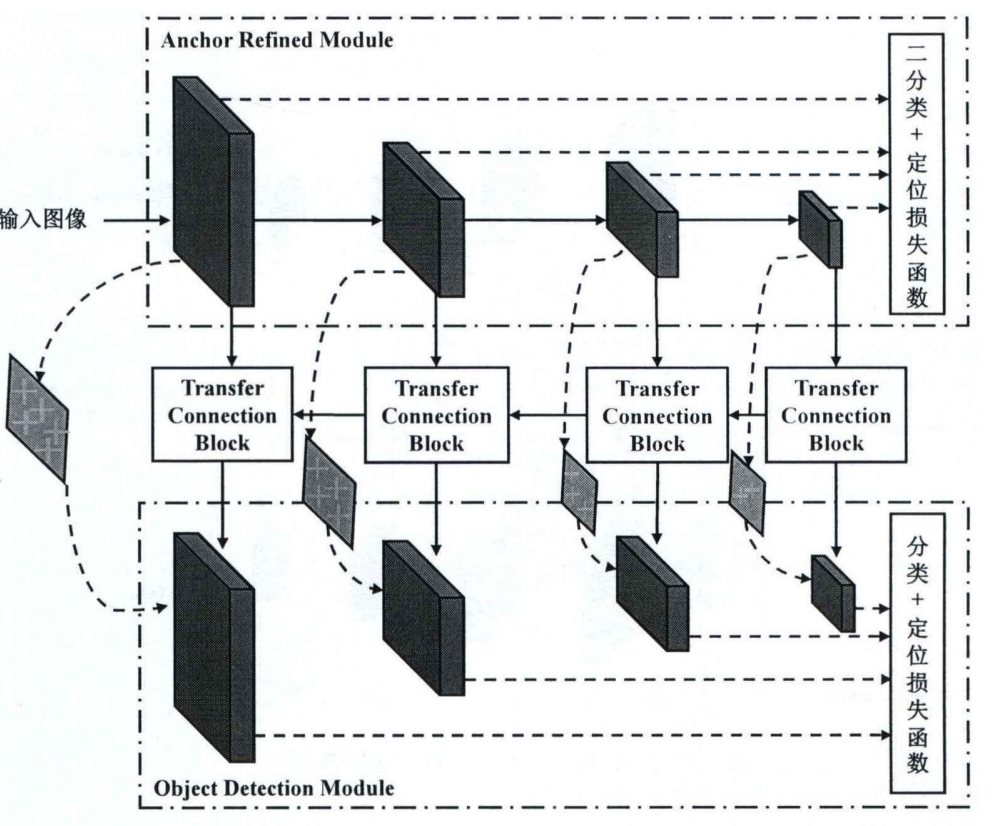
Dense-RefineDet模型結構
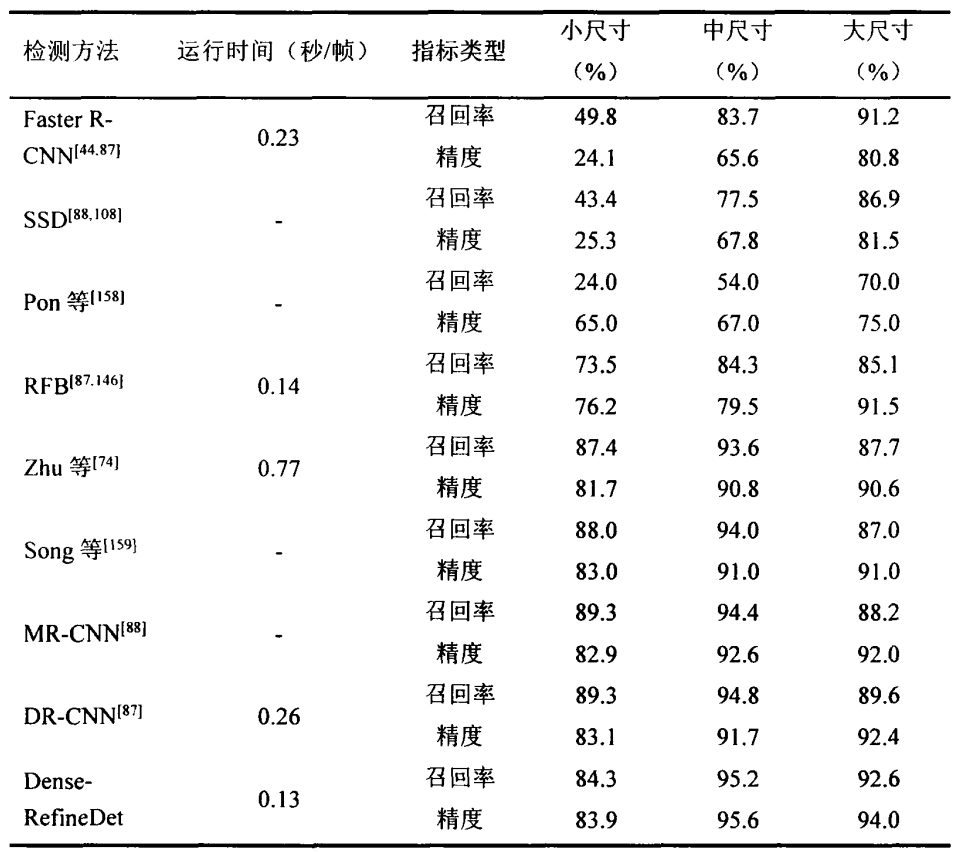
RefineDet通過錨點細化模塊(Anchor Refinement Module,ARM)、檢測模塊(Object Detection Module,ODM)和特征傳遞模塊(Transfer Connection Block,TCB)三個模塊的協同工作,在一階目標檢測中獲得更高的監測精度。錨點細化模塊可以優化描點的位置和尺寸,以更好地匹配目標的實際形狀和大小。檢測模塊利用錨點細化模塊傳遞過來的特征對待檢測目標進行分類和定位處理。特征傳遞模塊的作用是將錨點細化模塊提取的特征傳遞給檢測模塊,同時在過程中進行了特征融合。
Dense-RefineDet模型以RefineDet為基礎框架,構建了基于錨框設計和稠密連接的交通標識識別模型,其骨干網絡是VGG16,輸入圖像尺寸為 640x640。遵循多尺度輸出策略,用于檢測的輸出特征一共有 4 層,分別是 Conv4-3 層、Conv5-3層、Conv7 層和 Conv8-2,對應的特征尺寸大小分別為 80x80、40x40、20x20以及10x10。
? 01小目標錨框設計的優勢 ?
我們圍繞錨框形狀設計和錨框坐標設計提出了一個針對小目標的方法,該方法能夠更好的進行形狀匹配,提高小目標的檢測精度:
1應用K-means確定錨框形狀。以訓練集的所有矩形邊界框為數據集,對其進行K均值聚類,k=4,。 2確定錨框坐標。Dense-RefineDet輸出了四層不同尺寸的特征,為尺寸最大的淺層特征配置兩組尺寸較小的錨框,所有錨框的中心坐標設置為(0,25,0,25),(0,25,0,75),(0,75,0,25)和(0,75,0,75)該層的錨框數量為8。 3對于其余三層而言,配置全部的四組錨框,錨框的中心坐標保持不變,每個特征單元的錨框數量為4,下圖為錨框效果圖。
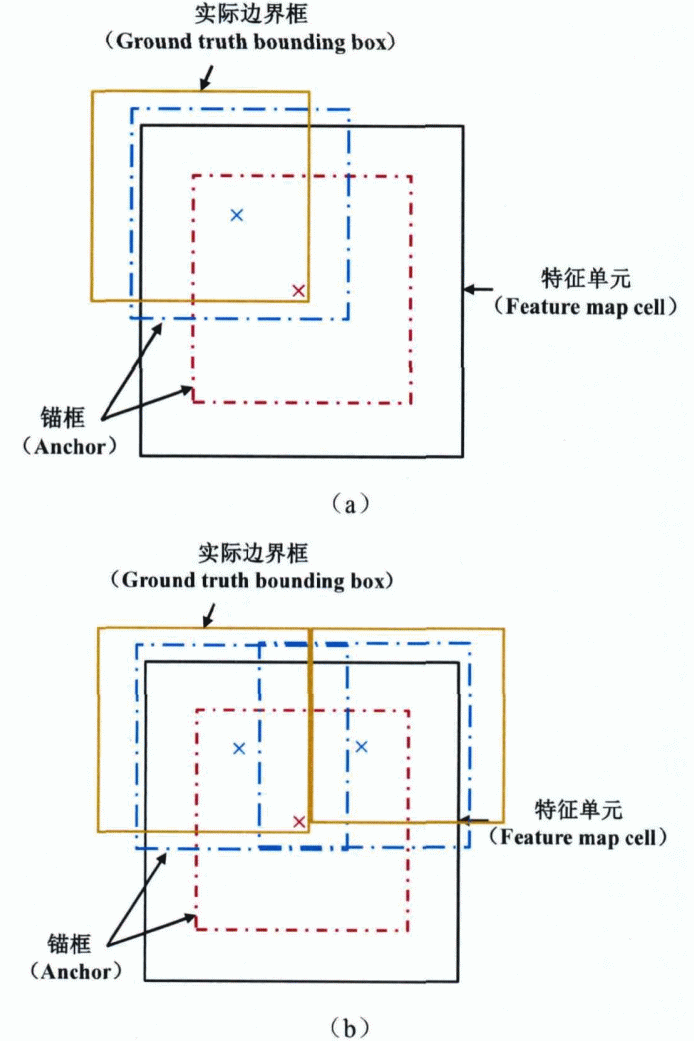
4對于每一個樣本計算其矩形邊界框跟所有錨框的交并比(IOU)。將其中擁有最大交并比的錨框確定為該檢測目標的匹配錨框,同時也將交并比大于某一閾值(一般為0,5)的所有錨框作為該目標檢測的匹配項。 5如圖(a)中的紅色框表示的是形狀確定的錨框,其中心坐標是(0,5,0,5)。藍色框表示的是和紅色框形狀相同的錨框,他的中心坐標為(0,25,0,75)。待檢測目標和紅色錨框之間的IOU要小于和藍色錨框之間的IOU,這表示藍色框更適合定位該目標。 6在(b)中,紅色錨框無法同時匹配兩個待檢測目標,此時,中心位于特征單元邊角位置的兩個藍色錨框則可以同時匹配上述待檢測目標。黑色矩形代表的是特征圖中的特征單元,紅色框和藍色框表示的是形狀確定的錨框,黃色框表示的是待檢測目標。 ?
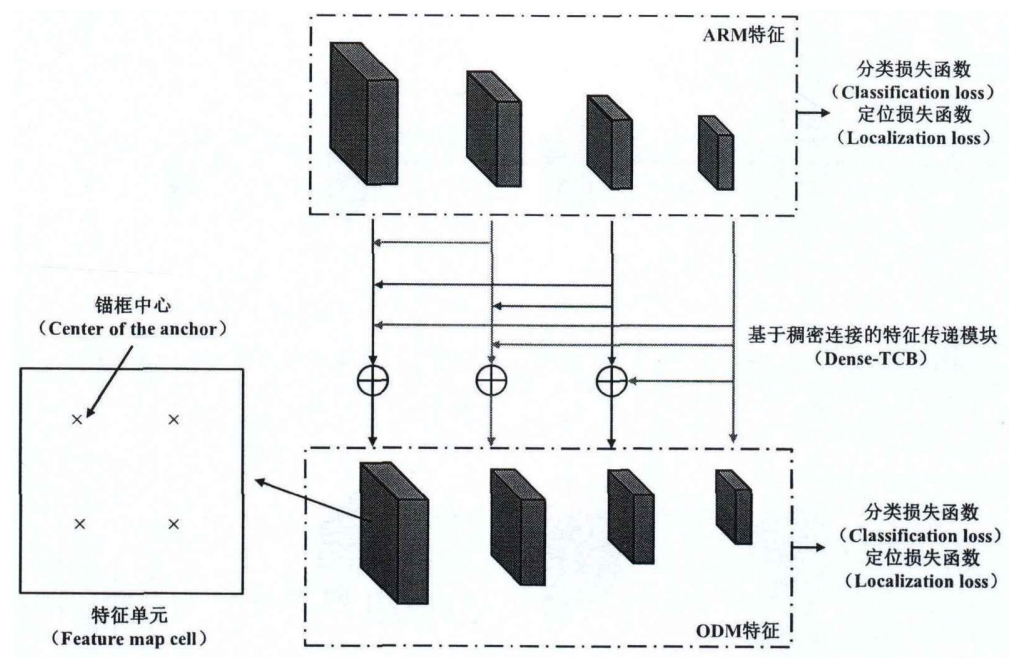
02特征傳遞模塊 ?
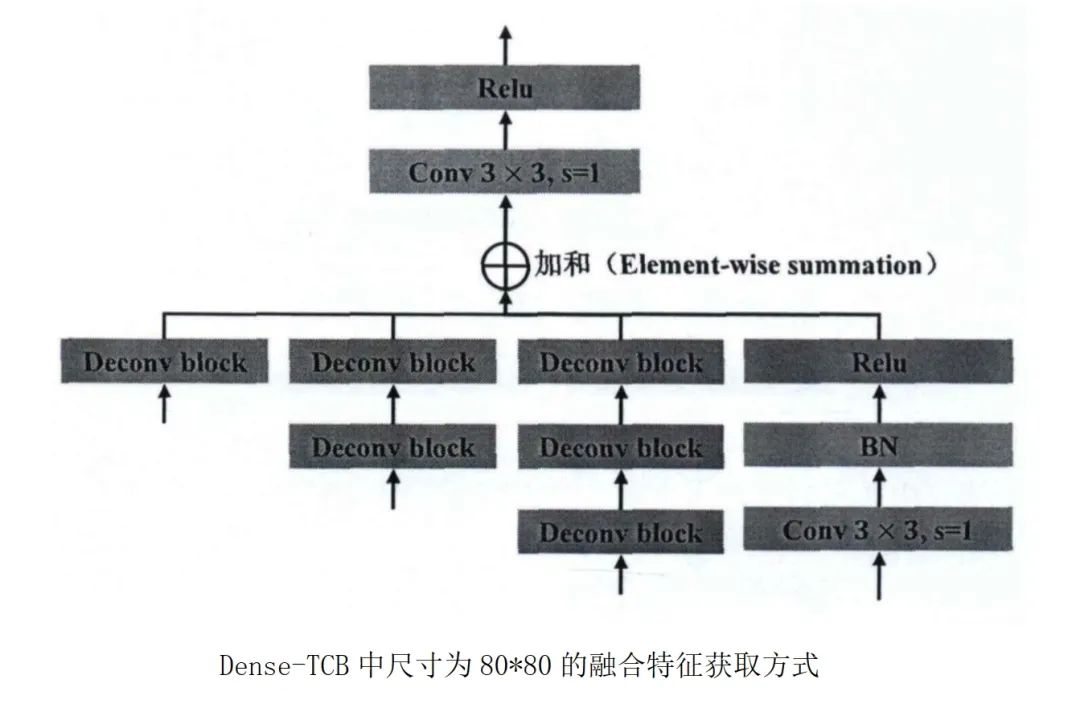
采用稠密連接的方式進行特征傳遞,稠密鏈接將高一層級的特征層(Conv8-2層)進行反卷積得到和自身特征層尺寸相同的特征圖,通過對應元素加和的方式進行融合,得到最終的特征融合層。最后將融合特征傳遞到ODM。對于剩余的特征層,直接將其傳遞到 ODM。這樣做的優勢在于CNN結構中淺層特征圖包含豐富的空間信息,而深層特征圖則包含豐富的語義信息,兩者結合則可以獲取額外的上下文信息,從而提高檢測精度。
? 03模型性能評估 ?
在Tsinghua-Tencent 100K數據集上對比了Dense-RefineDet模型與其他深度學習方法的性能,Dense-RefineDet在中等尺寸和大尺寸交通標識識別上的召回率和精度均由于其他模型,在小尺度模型上的召回率雖略遜于DRMR-CNN,但精度和速度高于前者。同時,Dense-RefineDet模型的速度達到0.13秒/幀,這在業界屬于速度非常快的模型,能夠滿足道路標識檢測中實時性的需求。
? ? 參考文獻
【1】李林糠.基于計算機視覺的安全輔助駕駛系統[D].西安電子科技大學2018.
【2】范延軍基于機器視覺的先進輔助駕駛系統關鍵技術研究[D1. 東南大學2016.
【3】RAGESH N,RAJESH R. Pedestrian detection in automotive safety:understanding state-of-the-art[J].IEEE Access,20197: 47864-47890.
【4】SWATHI M,SURESH K. Automatic traffic sign detection and recognition:A review[C]//2017 International Conference on Algorithms, Methodology,Models and Applications in Emerging Technologies (ICAMMAET), 2017:1-6
【5】HILLEL A B, LERNER R, DAN L, et al. Recent progress in road and lanedetection: a survey[J]. Machine Vision & Applications,2014,25(3): 727-745.
【6】Y. Yanbin, Z. Lijuan, L. Mengjun, S. Ling, Early warning of traffic accident inshanghai based on large data set mining, in: 2016 InternationalConferenceon Intelligent Transportation, Big Data Smart City (ICITBS), 2016, pp. 18-21http://dx.doi.org/10.1109/ICITBS.2016.149.
【7】M. Peden, Global collaboration on road traffic injury prevention, Int. J. Inj[2]Control Saf. Promot.12 (2) (2005) 85-91.
【8】F. Jimnez, J.E. Naranjo, J.J. Anaya, F. Garca, A. Ponz, J.M. Armingol, Advanceddriver assistance system for road environments to improve safety and efficiencyTransp. Res. Procedia 14 (2016) 2245-2254, Transport Research Arena TRA2016
【9】P. Viswanath, K. Chitnis, P. Swami, M. Mody, S. Shivalingappa, S. NagoriM. Mathew, K. Desappan, S. Jagannathan, D. Poddar, A. Jain, H. Garud, VAppia, M. Mangla, S. Dabral, A diverse low cost high performance platform foradvanced driver assistance system (adas) applications, in: 2016 IEEE Conferenceon Computer Vision and Pattern Recognition Workshops (CVPRW), 2016, pp819-827,http://dx.doi.org/10.1109/CVPRW.2016.107.
【10】Y. Ouerhani, A. Alfalou, M. Desthieux, C. Brosseau, Advanced driver assistancesystem: Road sign identification using viapix system and a correlation techniqueOpt. Lasers Eng.89 (2017) 184-194, 3DIM-DS 2015: Optical Image Processingin the context of 3D Imaging, Metrology, and Data Security.
編輯:黃飛
?


















 工商網監
工商網監
評論