 電子發(fā)燒友App
電子發(fā)燒友App


AI 模型構(gòu)建的過程 模型構(gòu)建主要包括 5 個階段,分別為模型設(shè)計、特征工程、模型訓(xùn)練、模型驗證、模型融合。
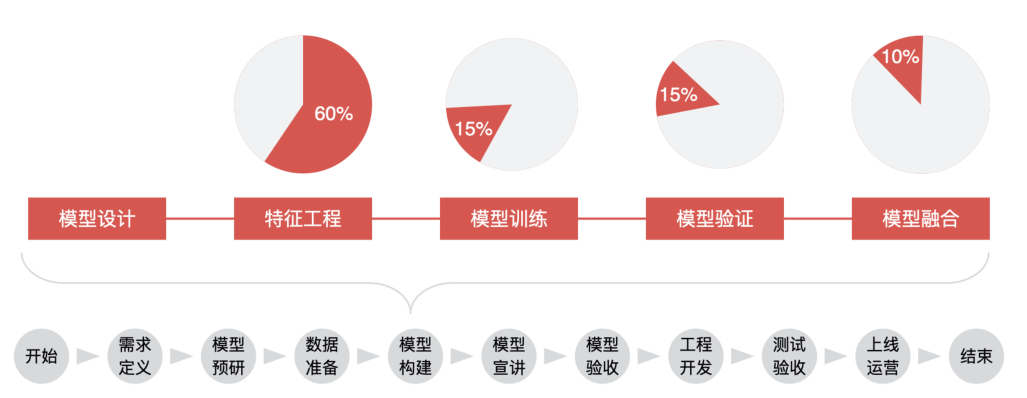
模型設(shè)計 ??????
??在模型設(shè)計環(huán)節(jié),產(chǎn)品經(jīng)理要考慮的問題就是,在當(dāng)前業(yè)務(wù)下,這個模型該不該做,我們有沒有能力做這個模型,目標(biāo)變量應(yīng)該怎么設(shè)置、數(shù)據(jù)源應(yīng)該有哪些、數(shù)據(jù)樣本如何獲取,是隨機(jī)抽取還是分層抽樣。 ????????
在模型設(shè)計階段最重要的就是定義模型目標(biāo)變量,以及抽取數(shù)據(jù)樣本。 ???????
?不同的目標(biāo)變量,決定了這個模型應(yīng)用的場景,以及能達(dá)到的業(yè)務(wù)預(yù)期。 ?????
???接著,我們再來說說數(shù)據(jù)樣本的抽取。模型是根據(jù)我們選擇的樣本來進(jìn)行訓(xùn)練的,所以樣本的選取決定了模型的最終效果。換句話說,樣本是用來做模型的基礎(chǔ)。在選取樣本的時候,你需要根據(jù)模型的目標(biāo)、業(yè)務(wù)的實際場景來選擇合適的樣本。
特征工程 ?????
???我們可以把整個模型的構(gòu)建理解為:從樣本數(shù)據(jù)中提取可以很好描述數(shù)據(jù)的特征,再利用它們建立出對未知數(shù)據(jù)有優(yōu)秀預(yù)測能力的模型。 ???????
?在模型的構(gòu)建過程中,特征工程是一個非常重要的部分。特征挑選得好,不僅可以直接提高模型的性能,還會降低模型的實現(xiàn)復(fù)雜度。
無論特征和數(shù)據(jù)過多或過少,都會影響模型的擬合效果,出現(xiàn)過擬合或欠擬合的情況。
當(dāng)選擇了優(yōu)質(zhì)的特征之后,即使你的模型參數(shù)不是最優(yōu)的,也能得到不錯的模型性能,你也就不需要花費(fèi)大量時間去尋找最優(yōu)參數(shù)了,從而降低了模型實現(xiàn)的復(fù)雜度。
數(shù)據(jù)和特征決定了機(jī)器學(xué)習(xí)的上限,而模型和算法只是逼近這個上限而已。 ???
?????算法工程師們花費(fèi)在特征工程建立上面的時間,基本上占整個模型構(gòu)建的 60%。 ??
??????那什么是特征工程?對一個模型來說,因為它的輸入一定是數(shù)量化的信息,也就是用向量、矩陣或者張量的形式表示的信息。所以,當(dāng)我們想要利用一些字符串或者其他類型的數(shù)據(jù)時,我們也一定要把它們先轉(zhuǎn)換成數(shù)量化的信息。像這種把物體表示成一個向量或矩陣的過程,就叫做特征工程(Feature Engineering)。 ???????
?那什么是建立特征工程呢?比較常見的,我們可以通過一個人的年齡、學(xué)歷、工資、信用卡個數(shù)等等一系列特征,來表示這個人的信用狀況,這就是建立了這個人信用狀況的特征工程。同時,我們可以通過這些特征來判斷這個人的信用好壞。 ?????
更具體點來說,建立特征工程的流程是,先做數(shù)據(jù)清洗,再做特征提取,之后是特征篩選,最后是生成訓(xùn)練 / 測試集。
1. 數(shù)據(jù)清洗

????????在建立特征工程的開始階段,算法工程師為了更好地理解數(shù)據(jù),通常會通過數(shù)據(jù)可視化(Data Visualization)的方式直觀地查看到數(shù)據(jù)的特性,比如數(shù)據(jù)的分布是否滿足線性的?數(shù)據(jù)中是否包含異常值?特征是否符合高斯分布等等。然后,才會對數(shù)據(jù)進(jìn)行處理,也就是數(shù)據(jù)清洗,來解決這些數(shù)據(jù)可能存在的數(shù)據(jù)缺失、有異常值、數(shù)據(jù)不均衡、量綱不一致等問題。
數(shù)據(jù)缺失
在數(shù)據(jù)清洗階段是最常見的問題。在遇到數(shù)據(jù)缺失問題時,算法工程師可以通過刪除缺失值或者補(bǔ)充缺失值的手段來解決它。
至于數(shù)值異常的問題,可以選擇的方法就是對數(shù)據(jù)修正或者直接丟棄,當(dāng)然如果你的目標(biāo)就是發(fā)現(xiàn)異常情況,那就需要保留異常值并且標(biāo)注。
對于數(shù)據(jù)不均衡的問題,因為數(shù)據(jù)偏差可能導(dǎo)致后面訓(xùn)練的模型過擬合或者欠擬合,所以處理數(shù)據(jù)偏差問題也是數(shù)據(jù)清洗階段需要考慮的。
針對量綱不一致的問題,也就是同一種數(shù)據(jù)的單位不同,比如金額這個數(shù)據(jù),有的是以萬元為單位,有的是以元為單位,我們一般是通過歸一化讓它們的數(shù)據(jù)單位統(tǒng)一。
2. 特征提取? ? ? ??

????????一般提取出的特征會有 4類常見的形式,分別是數(shù)值型特征數(shù)據(jù)、標(biāo)簽或者描述類數(shù)據(jù)、非結(jié)構(gòu)化數(shù)據(jù)、網(wǎng)絡(luò)關(guān)系型數(shù)據(jù)。 數(shù)值型特征數(shù)據(jù)
數(shù)據(jù)一般包含大量的數(shù)值特征。
這類特征可以直接從數(shù)倉中獲取,操作起來非常簡單
一系列聚合函數(shù)也可以去描述特征,比如總次數(shù)、平均次數(shù),當(dāng)前次數(shù)比上過去的平均次數(shù)等等。
標(biāo)簽或描述類數(shù)據(jù)
這類數(shù)據(jù)的特點是包含的類別相關(guān)性比較低,并且不具備大小關(guān)系。
這類特征的提取方法也非常簡單,一般就是將這三個類別轉(zhuǎn)化為特征,讓每個特征值用0、1 來表示,如有房 [0, 1]、有車 [0, 1] 等等。
非結(jié)構(gòu)化數(shù)據(jù)(處理文本特征)
非結(jié)構(gòu)化數(shù)據(jù)一般存在于 UGC(User Generated Content,用戶生成內(nèi)容)內(nèi)容數(shù)據(jù)中。比如我們的用戶流失預(yù)測模型用到了用戶評論內(nèi)容,而用戶評論都是屬于非結(jié)構(gòu)化的文本類數(shù)據(jù)。
提取非結(jié)構(gòu)化特征的一般做法就是,對文本數(shù)據(jù)做清洗和挖掘,挖掘出在一定程度上反映用戶屬性的特征。
網(wǎng)絡(luò)關(guān)系型數(shù)據(jù)
前三類數(shù)據(jù)描述的都是個人,而網(wǎng)絡(luò)關(guān)系型數(shù)據(jù)描述的是這個人和周圍人的關(guān)系。
提取這類特征其實就是,根據(jù)復(fù)雜網(wǎng)絡(luò)的關(guān)系去挖掘任意兩人關(guān)系之間的強(qiáng)弱,像是家庭關(guān)系、同學(xué)關(guān)系、好友關(guān)系等等。
3. 特征選擇

????特征選擇簡單來說,就是排除掉不重要的特征,留下重要特征。
算法工程師會對希望入模的特征設(shè)置對應(yīng)的覆蓋度、IV 等指標(biāo),這是特征選擇的第一步。
然后,再依據(jù)這些指標(biāo)和按照經(jīng)驗定下來的閾值對特征進(jìn)行篩選。
最后,還要看特征的穩(wěn)定性,將不穩(wěn)定的特征去掉。
4. 訓(xùn)練 / 測試集

這一步也是模型正式開始訓(xùn)練前需要做的,簡單來說,就是算法同學(xué)需要把數(shù)據(jù)分成訓(xùn)練集和測試集,他們會使用訓(xùn)練集來進(jìn)行模型訓(xùn)練,會使用測試集驗證模型效果。
模型訓(xùn)練
模型訓(xùn)練是通過不斷訓(xùn)練、驗證和調(diào)優(yōu),讓模型達(dá)到最優(yōu)的一個過程。
決策邊界是判斷一個算法是線性還是非線性最重要的標(biāo)準(zhǔn)。
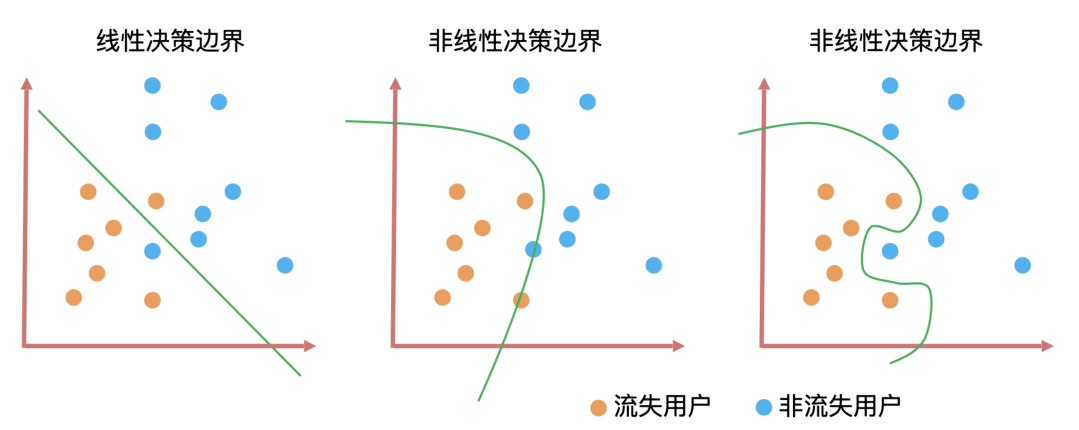
上圖就是三種算法的決策邊界。決策邊界的形式無非就是直線和曲線兩種,并且這些曲線的復(fù)雜度(曲線的平滑程度)和算法訓(xùn)練出來的模型能力息息相關(guān)。一般來說決策邊界曲線越陡峭,模型在訓(xùn)練集上的準(zhǔn)確率越高,但陡峭的決策邊界可能會讓模型對未知數(shù)據(jù)的預(yù)測結(jié)果不穩(wěn)定。
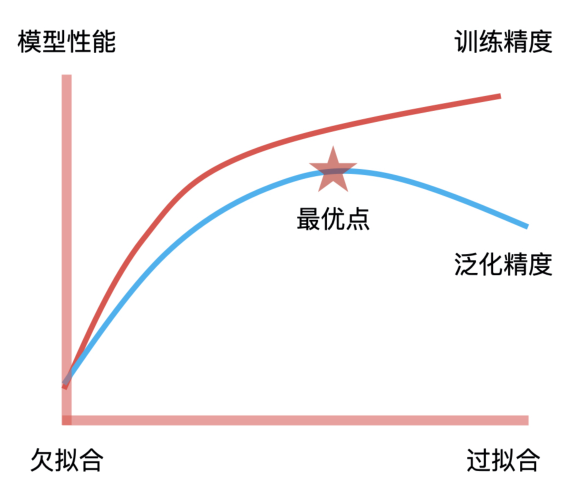
模型訓(xùn)練的目標(biāo)就是找到擬合能力與泛化能力的平衡點。擬合能力代表模型在已知數(shù)據(jù)上表現(xiàn)得好壞,泛化能力代表模型在未知數(shù)據(jù)上表現(xiàn)得好壞。它們之間的平衡點,就是我們通過不斷地訓(xùn)練和驗證找到的模型參數(shù)的最優(yōu)解,因此,這個最優(yōu)解繪制出來的決策邊界就具有最好的擬合和泛化能力。這是模型訓(xùn)練中“最優(yōu)”的意思,也是模型訓(xùn)練的核心目標(biāo)。
一般情況下,算法工程師會通過交叉驗證(Cross Validation)的方式,找到模型參數(shù)的最優(yōu)解。
模型驗證
????????模型驗證主要是對待驗證數(shù)據(jù)上的表現(xiàn)效果進(jìn)行驗證,一般是通過模型的性能指標(biāo)和穩(wěn)定性指標(biāo)來評估。 模型性能 ????????可以理解為模型預(yù)測的效果,你可以簡單理解為“預(yù)測結(jié)果準(zhǔn)不準(zhǔn)”,它的評估方式可以分為兩大類:分類模型評估和回歸模型評估?。
分類模型評估? ? ???? ??????
??分類模型解決的是將一個人或者物體進(jìn)行分類,例如在風(fēng)控場景下,區(qū)分用戶是不是“好人”,或者在圖像識別場景下,識別某張圖片是不是包含人臉。對于分類模型的性能評估,我們會用到包括召回率、F1、KS、AUC?這些評估指標(biāo)。
回歸模型評估
????????回歸模型解決的是預(yù)測連續(xù)值的問題,如預(yù)測房產(chǎn)或者股票的價格,所以我們會用到方差和 MSE?這些指標(biāo)對回歸模型評估。? ?????? ????????對于產(chǎn)品經(jīng)理來說,我們除了要知道可以對模型性能進(jìn)行評估的指標(biāo)都有什么,還要知道這些指標(biāo)值到底在什么范圍是合理的。雖然,不同業(yè)務(wù)的合理值范圍不一樣,我們要根據(jù)自己的業(yè)務(wù)場景來確定指標(biāo)預(yù)期,但我們至少要知道什么情況是不合理的。 模型穩(wěn)定性 ????????我們可以使用 PSI 指標(biāo)來判斷模型的穩(wěn)定性,如果一個模型的 PSI > 0.2,那它的穩(wěn)定性就太差了,這就說明算法同學(xué)的工作交付不達(dá)標(biāo)。 ? ?
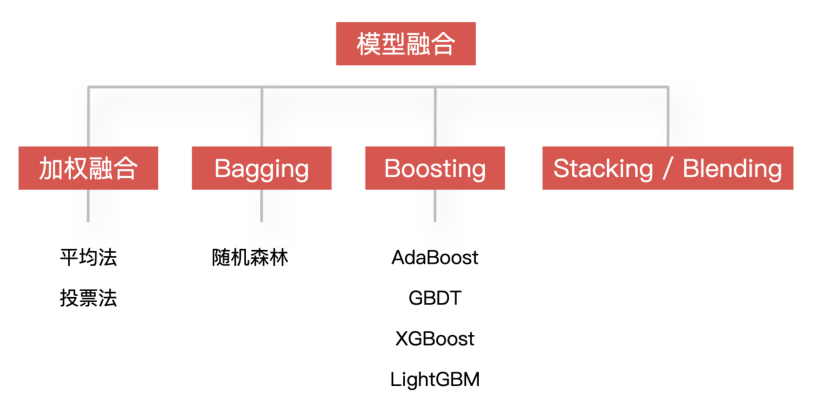
模型融合 ????
????同時訓(xùn)練多個模型,再通過模型集成的方式把這些模型合并在一起,從而提升模型的準(zhǔn)確率。簡單來說,就是用多個模型的組合來改善整體的表現(xiàn)。????????
模型部署? ??????
一般情況下,因為算法團(tuán)隊和工程團(tuán)隊是分開的兩個組織架構(gòu),所以算法模型基本也是部署成獨立的服務(wù),然后暴露一個 HTTP API 給工程團(tuán)隊進(jìn)行調(diào)用,這樣可以解耦相互之間的工作依賴,簡單的機(jī)器學(xué)習(xí)模型一般通過 Flask 來實現(xiàn)模型的部署,深度學(xué)習(xí)模型一般會選 TensorFlow Serving?來實現(xiàn)模型部署。
編輯:黃飛
?























 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論