 電子發燒友App
電子發燒友App


?? ??在2023年投資者會議上,Nvidia展示了其全新的GPU發展藍圖?[1]。與以往兩年一次的更新節奏不同,這次的路線圖將演進周期縮短至一年。預計在2024年,Nvidia將推出H200和B100 GPU;到2025年,X100 GPU也將面世。其AI芯片規劃的戰略核心是“One Architecture”統一架構,支持在任何地方進行模型訓練和部署,無論是數據中心還是邊緣設備,無論是x86架構還是Arm架構。其解決方案適用于超大規模數據中心的訓練任務,也可以滿足企業級用戶的邊緣計算需求。
AI芯片從兩年一次的更新周期轉變為一年一次的更新周期,反映了其產品開發速度的加快和對市場變化的快速響應。其AI芯片布局涵蓋了訓練和推理兩個人工智能關鍵應用,訓練推理融合,并側重推理。同時支持x86和Arm兩種不同硬件生態。在市場定位方面,同時面向超大規模云計算和企業級用戶,以滿足不同需求。Nvidia旨在通過統一的架構、廣泛的硬件支持、快速的產品更新周期以及面向不同市場提供全面的差異化的AI解決方案,從而在人工智能領域保持技術和市場的領先地位。Nvidia是一個同時擁有 GPU、CPU和DPU的計算芯片和系統公司。Nvidia通過NVLink、NVSwitch和NVLink C2C技術將CPU、GPU進行靈活連接組合形成統一的硬件架構,并于CUDA一起形成完整的軟硬件生態。
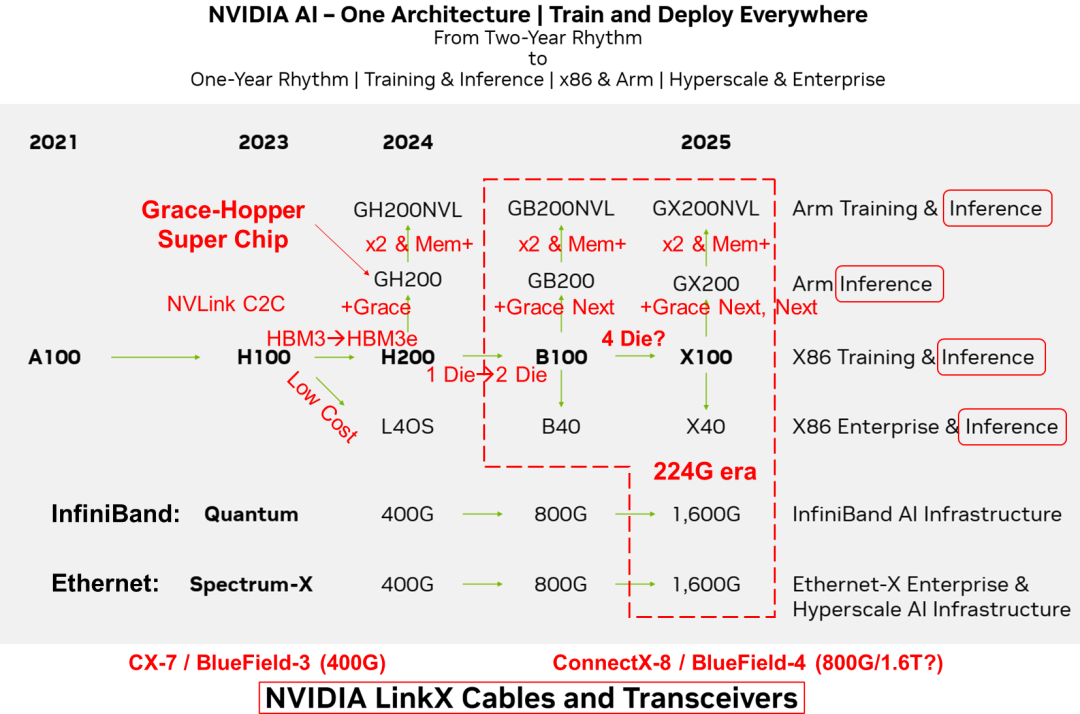
在AI計算芯片架構方面,注重訓練和推理功能的整合,側重推理。圍繞GPU打造ARM和X86兩條技術路線。在Nvidia的AI路線圖中,并沒有顯示提及Grace CPU的技術路線,而是將其納入Grace+GPU的SuperChip超級芯片路標中。
Nvidia Grace CPU會跟隨GPU的演進節奏并與其組合成新一代超級芯片;而其自身也可能根據市場競爭的需求組合成CPU超級芯片,實現“二打一”的差異化競爭力。從需求角度來看,CPU的技術演進速度并不像GPU那樣緊迫,并且CPU對于成本更加敏感。CPU只需按照“摩爾”或“系統摩爾”,以每兩年性能翻倍的速度進行演進即可。而GPU算力需要不到一年就要實現性能翻倍,保持每年大約2.5倍的速率增長。這種差異催生了超級芯片和超節點的出現。
Nvidia將延用SuperChip超級芯片架構,NVLink-C2C和NVLink互聯技術在Nvidia未來的AI芯片架構中將持續發揮關鍵作用。其利用NVLink-C2C互聯技術構建GH200、GB200和GX200超級芯片。更進一步,通過NVLink互聯技術,兩顆GH200、GB200和GX200可以背靠背連接,形成GH200NVL、GB200NVL和GX200NVL模組。Nvidia可以通過NVLink網絡組成超節點,通過InfiniBand或Ethernet網絡組成更大規模的AI集群。
在交換芯片方面,仍然堅持InfiniBand和Ethernet兩條開放路線,瞄準不同市場,前者瞄準AI Factory,后者瞄準AIGC Cloud。但其并未給出NVLink和NVSwitch自有生態的明確計劃。224G代際的速度提升,可能率先NVLink和NVSwitch上落地。以InfiniBand為基礎的Quantum系列和以Ethernet基礎的Spectrum-X系列持續升級。預計到2024年,將商用基于100G SerDes的800G接口的交換芯片;而到2025年,將迎來基于200G SerDes的1.6T接口的交換芯片。其中800G對應51.2T交換容量的Spectrum-4芯片,而1.6T則對應下一代Spectrum-5,其交換容量可能高達102.4T。從演進速度上看,224G代際略有提速,但從長時間周期上看,其仍然遵循著SerDes速率大約3到4年翻倍、交換芯片容量大約2年翻倍的規律。雖然有提到2024年Quantum將會升級到800G,但目前我們只能看到2021年發布的基于7nm工藝,400G接口的25.6T Quantum-2交換芯片。路線圖中并未包含NVSwitch 4.0和NVLink 5.0的相關計劃。有預測指出Nvidia可能會首先在NVSwitch和NVLink中應用224G SerDes技術。NVLink和NVSwitch作為Nvidia自有生態,不會受到標準生態的掣肘,在推出時間和技術路線選擇上更靈活,從而實現差異化競爭力。
SmartNIC智能網卡/DPU數據處理引擎的下一跳ConnectX-8/BlueField-4目標速率為 800G,與1.6T Quantum和Spectrum-X配套的SmartNIC和DPU的路標仍不明晰,NVLink5.0和NVSwitch4.0可能提前發力。Nvidia ConnectX系列SmartNIC智能網卡與InfiniBand技術相結合,可以在基于NVLink網絡的超節點基礎上構建更大規模的AI集群。而BlueField DPU則主要面向云數據中心場景,與Ethernet技術結合,提供更強大的網絡基礎設施能力。相較于NVLink總線域網絡,InfiniBand和Ethernet屬于傳統網絡技術,兩種網絡帶寬比例大約為1比9。例如,H00 GPU用于連接SmartNIC和DPU的PCIE帶寬為128GB/s,考慮到PCIE到Ethernet的轉換,其最大可以支持400G InfiniBand或者Ethernet接口,而NVLink雙向帶寬為900GB/s或者3.6Tbps,因此傳統網絡和總線域網絡的帶寬比為1比9。雖然SmartNIC和DPU的速率增長需求沒有總線域網絡的增速快,但它們與大容量交換芯片需要保持同步的演進速度。它們也受到由IBTA (InfiniBand)?和IEEE802.3 (Ethernet)?定義互通標準的產業生態成熟度的制約。
互聯技術在未來的計算系統的擴展中起到至關重要的作用。Nvidia同步布局的還有LinkX系列光電互聯技術。包括傳統帶oDSP引擎的可插拔光互聯?(Pluggable Optics),線性直驅光互聯LPO (Linear Pluggable Optics),傳統DAC電纜、重驅動電纜?(Redrived Active Copper Cable)、芯片出光?(Co-Packaged Optics)?等一系列光電互聯技術。隨著超節點和集群網絡的規模不斷擴大,互聯技術將在未來的AI計算系統中發揮至關重要的作用,需要解決帶寬、時延、功耗、可靠性、成本等一系列難題。
對Nvidia而言,來自Google、Meta、AMD、Microsoft和Amazon等公司的競爭壓力正在加大。這些公司在軟件和硬件方面都在積極發展,試圖挑戰Nvidia在該領域的主導地位,這或許是Nvidia提出相對激進技術路線圖的原因。Nvidia為了保持其市場地位和利潤率,采取了一種大膽且風險重重的多管齊下的策略。他們的目標是超越傳統的競爭對手如Intel和AMD,成為科技巨頭,與Google、Microsoft、Amazon、Meta和Apple等公司并駕齊驅。Nvidia的計劃包括推出H200、B100和“X100”GPU,以及進行每年度更新的AI GPU。此外,他們還計劃推出HBM3E高速存儲器、PCIE 6.0和PCIE 7.0、以及NVLink、224G SerDes、1.6T接口等先進技術,如果計劃成功,Nvidia將超越所有潛在的競爭對手?[2]。
盡管硬件和芯片領域的創新不斷突破,但其發展仍然受到第一性原理的限制,存在天然物理邊界的約束。通過深入了解工藝制程、先進封裝、內存和互聯等多個技術路線,可以推斷出未來Nvidia可能采用的技術路徑。盡管基于第一性原理的推演成功率高,但仍需考慮非技術因素的影響。例如,通過供應鏈控制,在一定時間內壟斷核心部件或技術的產能,如HBM、TSMC CoWoS先進封裝工藝等,可以影響技術演進的節奏。根據Nvidia 2023年Q4財報,該公司季度收入達到76.4億美元,同比增長53%,創下歷史新高。全年收入更是增長61%,達到269.1億美元的紀錄。數據中心業務在第四季度貢獻了32.6億美元的收入,同比增長71%,環比增長11%。財年全年數據中心收入增長58%,達到創紀錄的106.1億美元?[3]。因此Nvidia擁有足夠大的現金流可以在短時間內對供應鏈,甚至產業鏈施加影響。另外,也存在一些黑天鵝事件也可能產生影響,比如以色列和哈馬斯的戰爭就導致了Nvidia取消了原定于10月15日和16日舉行的AI SUMMIT [4]。業界原本預期,Nvidia將于峰會中展示下一代B100 GPU芯片?[5]。值得注意的是,Nvidia的網絡部門前身Mellanox正位于以色列。
為了避免陷入不可知論,本文的分析主要基于物理規律的第一性原理,而不考慮經濟手段(例如控制供應鏈)和其他可能出現的黑天鵝事件(例如戰爭)等不確定性因素。當然,這些因素有可能在技術鏈條的某個環節產生重大影響,導致技術或者產品演進節奏的放緩,或者導致整個技術體系進行一定的微調,但不會對整個技術演進趨勢產生顛覆式的影響。考慮到這些潛在的變化,本文的分析將盡量采取一種客觀且全面的方式來評估這些可能的技術路徑。我們將以“如果 A 那么 X;如果 B 那么 Y;…”的形式進行思考和分析,旨在涵蓋所有可能影響技術發展的因素,以便提供更準確、更全面的分析結果。此外,本文分析是基于兩到三年各個關鍵技術的路標假設,即2025年之前。當相應的前提條件變化,相應的結論也應該作適當的調整,但是整體的分析思路是普適的。
Nvidia的AI布局
Nvidia在人工智能領域的布局堪稱全面,其以系統和網絡、硬件和軟件為三大支柱,構建起了深厚的技術護城河?[6]。有分析稱Nvidia的H100顯卡有高達90%的毛利率。Nvidia通過扶持像Coreweave這樣的GPU云服務商,利用供貨合同讓他們從銀行獲取資金,然后購買更多的H100顯卡,鎖定未來的顯卡需求量。這種模式已經超出傳統硬件公司的商業模式,套用馬克思在資本論中所述“金銀天然不是貨幣,貨幣天然是金銀。”,有人提出了“貨幣天然不是H100,但H100天然是貨幣”的說法?[7]。這一切的背后在于對于對未來奇點臨近的預期?[8],在于旺盛的需求,同時更在于其深厚的技術護城河。
Nvidia 2019年3月發起對Mellanox的收購?[9],并且于2020年4月完成收購?[10],經過這次收購Nvidia獲取了InfiniBand、Ethernet、SmartNIC、DPU及LinkX互聯的能力。面向GPU互聯,自研NVLink互聯和NVLink網絡來實現GPU算力Scale Up擴展,相比于基于InfiniBand網絡和基于Ethernet的RoCE網絡形成差異化競爭力。NVLink自2014年推出以來,已經歷了四個代際的演進,從最初的2014年20G NVLink 1.0,2018年25G NVLink2.0,2020年50G NVLink 3.0?到2022年的100G NVLink 4.0,預計到2024年,NVLink將進一步發展至200G NVLink 5.0。在應用場景上,NVLink 1.0至3.0主要針對PCIE板內和機框內互聯的需求,通過SerDes提速在與PCIE互聯的競爭中獲取顯著的帶寬優勢。值得注意的是,除了NVLink1.0采用了20G特殊速率點以外,NVLink2.0~4.0皆采用了與Ethernet相同或者相近的頻點,這樣做的好處是可以復用成熟的Ethernet互聯生態,也為未來實現連接盒子或機框組成超節點埋下伏筆。NVSwitch 1.0、2.0、3.0分別與NVLink2.0、3.0、4.0配合,形成了NVLink總線域網絡的基礎。NVLink4.0配合NVSwitch3.0組成了超節點網絡的基礎,這一變化的外部特征是NVSwitch脫離計算單板而單獨成為網絡設備,而NVLink則從板級互聯技術升級成為設備間互聯技術。
在計算芯片領域,Nvidia于2020年9月發起ARM收購,期望構建人工智能時代頂級的計算公司?[11],這一收購提案因為面臨重大監管挑戰阻礙了交易的進行,于2022年2月終止?[12]。但是,在同年3月其發布了基于ARM的Grace CPU Superchip超級芯片?[13]。成為同時擁有CPU、GPU和DPU的計算芯片和系統公司。
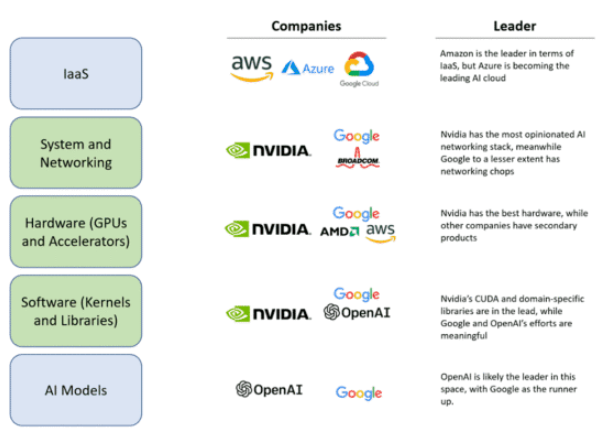
從業務視角看,Nvidia在系統和網絡、硬件、軟件三個方面占據了主導地位?[6]。系統和網絡、硬件、軟件這三個方面是人工智能價值鏈中許多大型參與者無法有效或快速復制的重要部分,這意味著Nvidia在整個生態系統中占據著主導地位。要擊敗Nvidia就像攻擊一個多頭蛇怪。必須同時切斷所有三個頭才有可能有機會,因為它的每個“頭”都已經是各自領域的領導者,并且Nvidia正在努力改進和擴大其護城河。在一批人工智能硬件挑戰者的失敗中,可以看到,他們都提供了一種與Nvidia GPU相當或略好的硬件,但未能提供支持該硬件的軟件生態和解決可擴展問題的方案。而Nvidia成功地做到了這一切,并成功抵擋住了一次沖擊。這就是為什么Nvidia的戰略像是一個三頭水蛇怪,后來者必須同時擊敗他們在系統和網絡、硬件以及軟件方面的技術和生態護城河。目前,進入Nvidia平臺似乎能夠占據先機。OpenAI、微軟和Nvidia顯然處于領先地位。盡管Google和Amazon也在努力建立自己的生態系統,但Nvidia提供了更完整的硬件、軟件和系統解決方案,使其成為最具吸引力的選擇。要贏得先機,就必須進入其硬件、軟件和系統級業務生態。然而,這也意味著進一步被鎖定,未來更難撼動其地位。從Google和Amazon等公司的角度來看,如果不選擇接入Nvidia的生態系統,可能會失去先機;而如果選擇接入,則可能意味著失去未來。
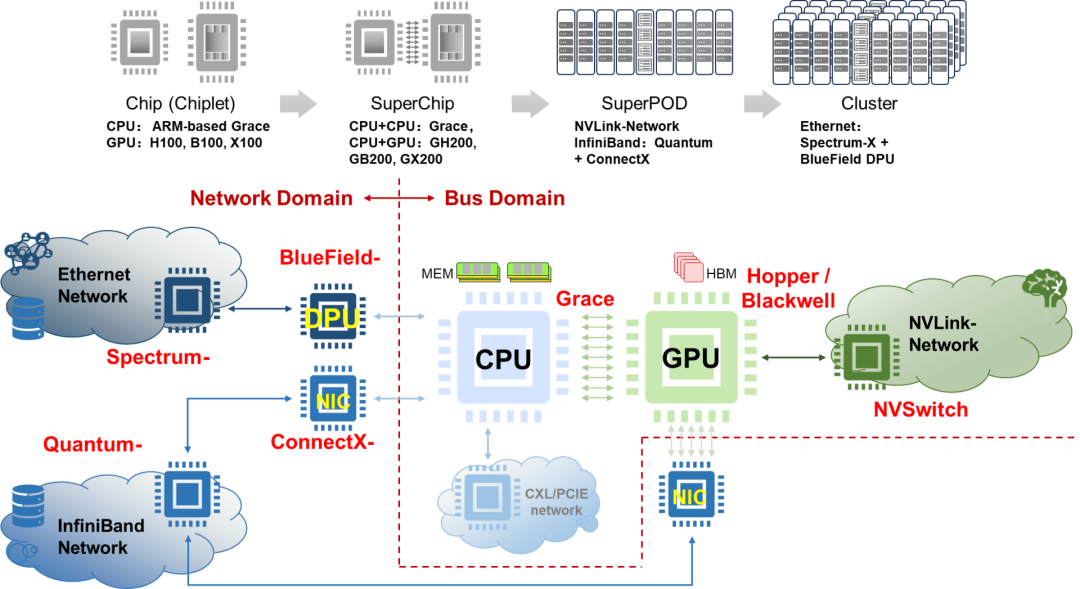
Nvidia布局了兩種類型網絡,一種是傳統InfiniBand和Ethernet網絡,另一種是NVLink總線域網絡。在傳統網絡中,Ethernet面向AIGC Cloud多AI訓練和推理等云服務,而InfiniBand面向AI Factory,滿足大模型訓練和推理的應用需求。在交換芯片布局方面,有基于開放Ethernet增強的Spectrum-X交換芯片和基于InfiniBand的封閉高性能的Quantum交換芯片。當前Ultra Ethernet Consortium (UEC)?正在嘗試定義基于Ethernet的開放、互操作、高性能的全棧架構,以滿足不斷增長的AI和HPC網絡需求?[14],旨在與Nvidia的網絡技術相抗衡。UEC的目標是構建一個類似于InfiniBand的開放協議生態,從技術層面可以理解為將Ethernet進行增強以達到InfiniBand網絡的性能,或者說是實現一種InfiniBand化的Ethernet。從某種意義上說UEC在重走InfiniBand道路。總線域網絡NVLink的主要特征是要在超節點范圍內實現內存語義級通信和總線域網絡內部的內存共享,它本質上是一個Load-Store網絡,是傳統總線網絡規模擴大以后的自然演進。從NVLink接口的演進歷程可以看出,其1.0~3.0版本明顯是對標PCIE的,而4.0版本實際上對標InfiniBand和Ethernet的應用場景,但其主要目標還是實現GPU的Scale Up擴展。
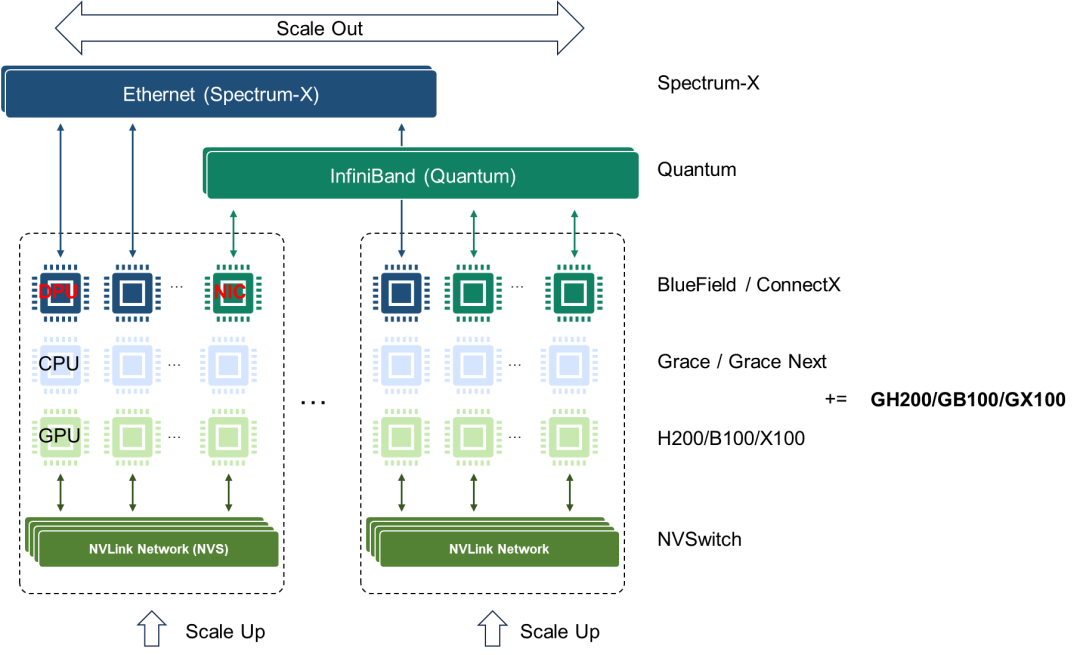
從原始需求的角度來看,NVLink網絡在演進過程中需要引入傳統網絡的一些基本能力,例如編址尋址、路由、均衡、調度、擁塞控制、管理控制和測量等。同時,NVLink還需要保留總線網絡基本特征,如低時延、高可靠性、內存統一編址共享以及內存語義通信。這些特征是當前InfiniBand或Ethernet網絡所不具備的或者說欠缺的。與InfiniBand和Ethernet傳統網絡相比,NVLink總線域網絡的功能定位和設計理念存在著本質上的區別。我們很難說NVLink網絡和傳統InfiniBand網絡或者增強Ethernet網絡最終會殊途同歸。
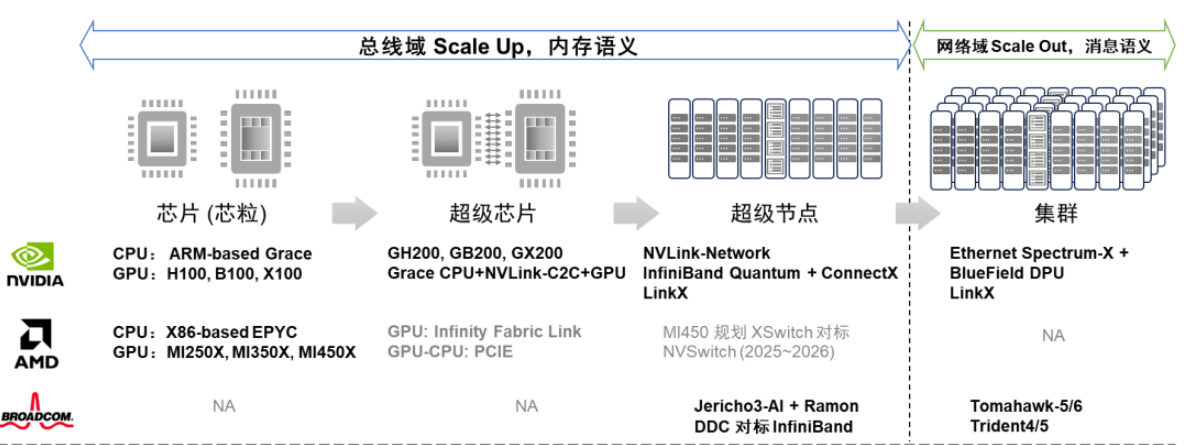
Nvidia在AI集群競爭態勢中展現出了全面布局,涵蓋了計算(芯片、超級芯片)和網絡(超節點、集群)領域。在計算芯片方面,Nvidia擁有CPU、GPU、CPU-CPU/CPU-GPU SuperChip等全面的布局;在超節點網絡層面,Nvidia提供了NVLink和InfiniBand兩種定制化網絡選項;在集群網絡方面,Nvidia有基于Ethernet的交換芯片和DPU芯片布局。AMD緊隨其后,更專注于CPU和GPU計算芯片,并采用基于先進封裝的Chiplet芯粒技術。
與Nvidia不同的是,AMD當前沒有超級芯片的概念,而是采用了先進封裝將CPU和GPU Die合封在一起。AMD使用私有的Infinity Fabric Link內存一致接口進行GPU、CPU、GPU和CPU間的互聯,而GPU和CPU之間的互聯仍然保留傳統的PCIE連接方式。此外,AMD計劃推出XSwitch交換芯片,下一代MI450加速器將利用新的互連結構,其目的顯然是與Nvidia的NVSwitch競爭?[15]。
BRCM則專注于網絡領域,在超節點網絡有對標InfiniBand的Jericho3-AI+Ramon的DDC方案;在集群網絡領域有基于Ethernet的Tomahawk系列和Trident系列交換芯片。近期BRCM推出其新的軟件可編程交換Trident 5-X12集成了NetGNT神經網絡引擎實時識別網絡流量信息,并調用擁塞控制技術來避免網絡性能下降,提高網絡效率和性能?[16]。Cerebras/Telsa Dojo則“劍走偏鋒”,走依賴“晶圓級先進封裝”的深度定制硬件路線。
作者:陸玉春
審核編輯:黃飛

















 工商網監
工商網監
評論