 電子發燒友App
電子發燒友App


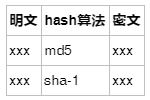
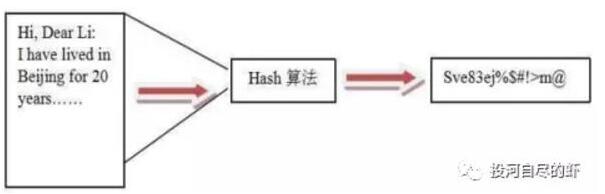
Hash,一般翻譯做“散列”,也有直接音譯為“哈希”的,就是把任意長度的輸入(又叫做預映射, pre-image),通過散列算法,變換成固定長度的輸出,該輸出就是散列值。這種轉換是一種壓縮映射,也就是,散列值的空間通常遠小于輸入的空間,不同的輸入可能會散列成相同的輸出,而不可能從散列值來唯一的確定輸入值。簡單的說就是一種將任意長度的消息壓縮到某一固定長度的消息摘要的函數。
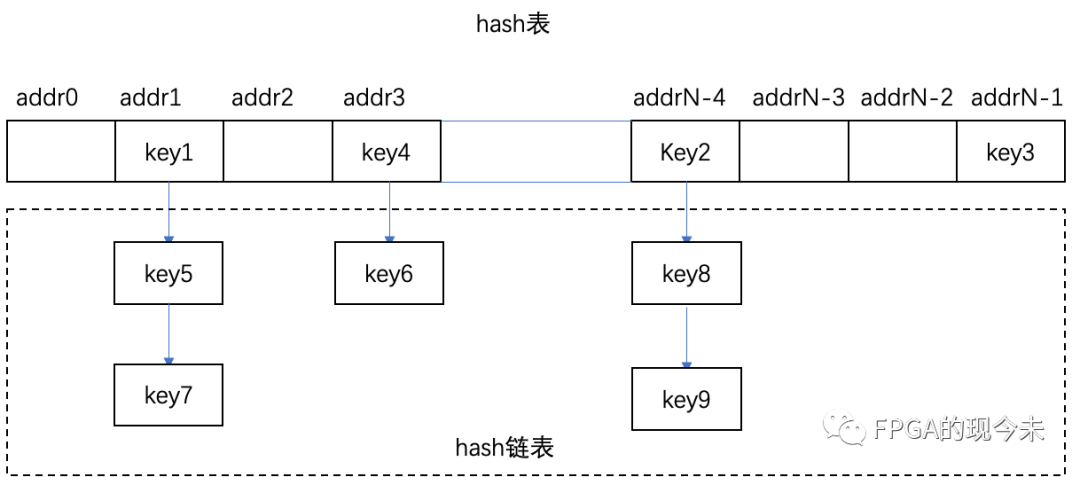
哈希表是根據設定的哈希函數H(key)和處理沖突方法將一組關鍵字映射到一個有限的地址區間上,并以關鍵字在地址區間中的象作為記錄在表中的存儲位置,這種表稱為哈希表或散列,所得存儲位置稱為哈希地址或散列地址。作為線性數據結構與表格和隊列等相比,哈希表無疑是查找速度比較快的一種。
通過將單向數學函數(有時稱為“哈希算法”)應用到任意數量的數據所得到的固定大小的結果。如果輸入數據中有變化,則哈希也會發生變化。哈希可用于許多操作,包括身份驗證和數字簽名。也稱為“消息摘要”。
簡單解釋:哈希(Hash)算法,即散列函數。它是一種單向密碼體制,即它是一個從明文到密文的不可逆的映射,只有加密過程,沒有解密過程。同時,哈希函數可以將任意長度的輸入經過變化以后得到固定長度的輸出。哈希函數的這種單向特征和輸出數據長度固定的特征使得它可以生成消息或者數據。

常用hash算法的介紹:
(1)MD4
MD4(RFC 1320)是 MIT 的Ronald L. Rivest在 1990 年設計的,MD 是 Message Digest(消息摘要) 的縮寫。它適用在32位字長的處理器上用高速軟件實現——它是基于 32位操作數的位操作來實現的。
(2)MD5
MD5(RFC 1321)是 Rivest 于1991年對MD4的改進版本。它對輸入仍以512位分組,其輸出是4個32位字的級聯,與 MD4 相同。MD5比MD4來得復雜,并且速度較之要慢一點,但更安全,在抗分析和抗差分方面表現更好。
(3)SHA-1及其他
SHA1是由NIST NSA設計為同DSA一起使用的,它對長度小于264的輸入,產生長度為160bit的散列值,因此抗窮舉(brute-force)性更好。SHA-1 設計時基于和MD4相同原理,并且模仿了該算法。
常見hash算法的原理
散列表,它是基于快速存取的角度設計的,也是一種典型的“空間換時間”的做法。顧名思義,該數據結構可以理解為一個線性表,但是其中的元素不是緊密排列的,而是可能存在空隙。
散列表(Hash table,也叫哈希表),是根據關鍵碼值(Key value)而直接進行訪問的數據結構。也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找的速度。這個映射函數叫做散列函數,存放記錄的數組叫做散列表。
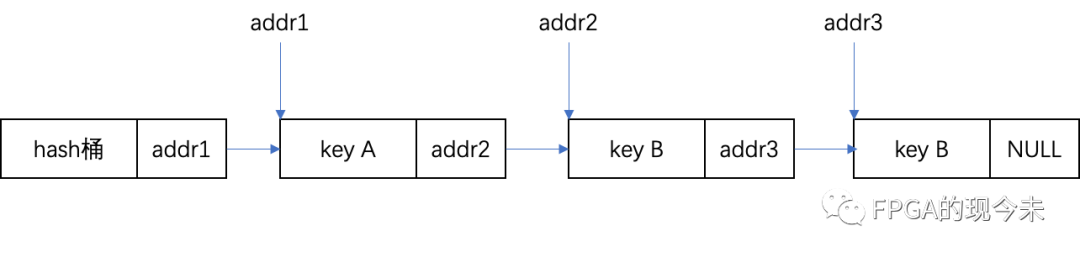
比如我們存儲70個元素,但我們可能為這70個元素申請了100個元素的空間。70/100=0.7,這個數字稱為負載因子。我們之所以這樣做,也是為了“快速存取”的目的。我們基于一種結果盡可能隨機平均分布的固定函數H為每個元素安排存儲位置,這樣就可以避免遍歷性質的線性搜索,以達到快速存取。但是由于此隨機性,也必然導致一個問題就是沖突。所謂沖突,即兩個元素通過散列函數H得到的地址相同,那么這兩個元素稱為“同義詞”。這類似于70個人去一個有100個椅子的飯店吃飯。散列函數的計算結果是一個存儲單位地址,每個存儲單位稱為“桶”。設一個散列表有m個桶,則散列函數的值域應為[0,m-1]。
解決沖突是一個復雜問題。
沖突主要取決于:
(1)散列函數,一個好的散列函數的值應盡可能平均分布。
(2)處理沖突方法。
(3)負載因子的大小。太大不一定就好,而且浪費空間嚴重,負載因子和散列函數是聯動的。
解決沖突的辦法:
(1)線性探查法:沖突后,線性向前試探,找到最近的一個空位置。缺點是會出現堆積現象。存取時,可能不是同義詞的詞也位于探查序列,影響效率。
(2)雙散列函數法:在位置d沖突后,再次使用另一個散列函數產生一個與散列表桶容量m互質的數c,依次試探(d+n*c)%m,使探查序列跳躍式分布。
常用的構造散列函數的方法
散列函數能使對一個數據序列的訪問過程更加迅速有效,通過散列函數,數據元素將被更快地定位:
1. 直接尋址法:取關鍵字或關鍵字的某個線性函數值為散列地址。即H(key)=key或H(key) = a?key + b,其中a和b為常數(這種散列函數叫做自身函數)
2. 數字分析法:分析一組數據,比如一組員工的出生年月日,這時我們發現出生年月日的前幾位數字大體相同,這樣的話,出現沖突的幾率就會很大,但是我們發現年月日的后幾位表示月份和具體日期的數字差別很大,如果用后面的數字來構成散列地址,則沖突的幾率會明顯降低。因此數字分析法就是找出數字的規律,盡可能利用這些數據來構造沖突幾率較低的散列地址。
3. 平方取中法:取關鍵字平方后的中間幾位作為散列地址。
4. 折疊法:將關鍵字分割成位數相同的幾部分,最后一部分位數可以不同,然后取這幾部分的疊加和(去除進位)作為散列地址。
5. 隨機數法:選擇一隨機函數,取關鍵字的隨機值作為散列地址,通常用于關鍵字長度不同的場合。
6. 除留余數法:取關鍵字被某個不大于散列表表長m的數p除后所得的余數為散列地址。即 H(key) = key MOD p, p《=m。不僅可以對關鍵字直接取模,也可在折疊、平方取中等運算之后取模。對p的選擇很重要,一般取素數或m,若p選的不好,容易產生同義詞。
查找的性能分析
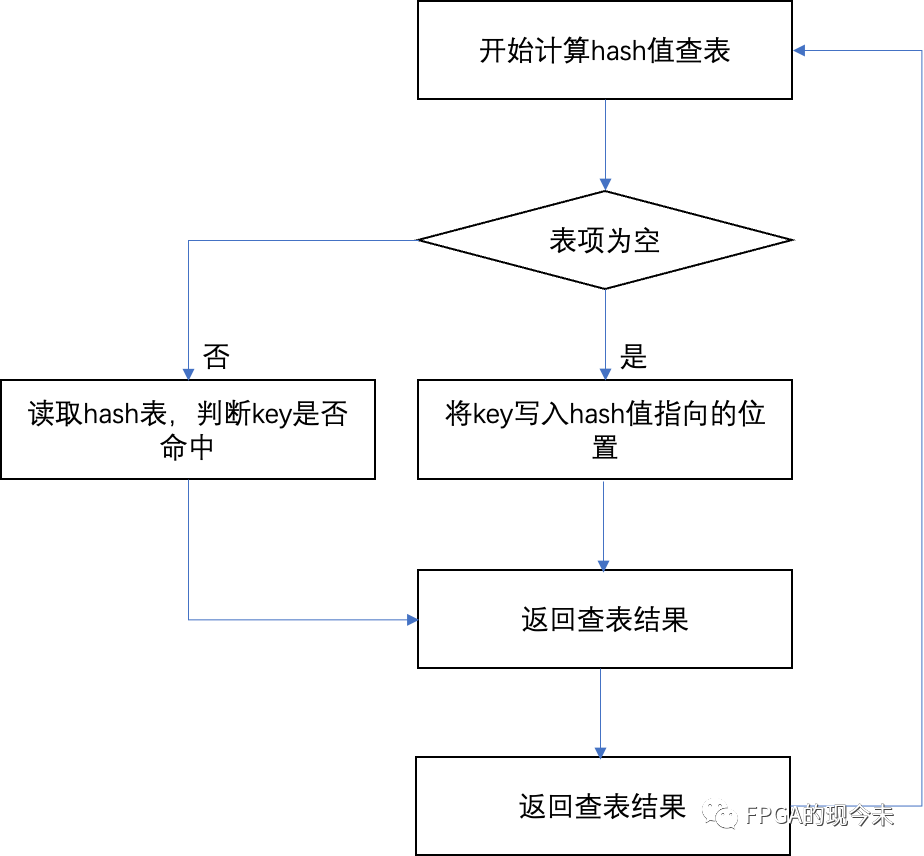
散列表的查找過程基本上和造表過程相同。一些關鍵碼可通過散列函數轉換的地址直接找到,另一些關鍵碼在散列函數得到的地址上產生了沖突,需要按處理沖突的方法進行查找。在介紹的三種處理沖突的方法中,產生沖突后的查找仍然是給定值與關鍵碼進行比較的過程。所以,對散列表查找效率的量度,依然用平均查找長度來衡量。
查找過程中,關鍵碼的比較次數,取決于產生沖突的多少,產生的沖突少,查找效率就高,產生的沖突多,查找效率就低。因此,影響產生沖突多少的因素,也就是影響查找效率的因素。影響產生沖突多少有以下三個因素:
1. 散列函數是否均勻;
2. 處理沖突的方法;
3. 散列表的裝填因子。
散列表的裝填因子定義為:α= 填入表中的元素個數 / 散列表的長度
α是散列表裝滿程度的標志因子。由于表長是定值,α與“填入表中的元素個數”成正比,所以,α越大,填入表中的元素較多,產生沖突的可能性就越大;α越小,填入表中的元素較少,產生沖突的可能性就越小。
實際上,散列表的平均查找長度是裝填因子α的函數,只是不同處理沖突的方法有不同的函數。
了解了hash基本定義,就不能不提到一些著名的hash算法,MD5 和 SHA-1 可以說是目前應用最廣泛的Hash算法,而它們都是以 MD4 為基礎設計的。那么他們都是什么意思呢?
這里簡單說一下:
(1) MD4
MD4(RFC 1320)是 MIT 的 Ronald L. Rivest 在 1990 年設計的,MD 是 Message Digest 的縮寫。它適用在32位字長的處理器上用高速軟件實現--它是基于 32 位操作數的位操作來實現的。
(2) MD5
MD5(RFC 1321)是 Rivest 于1991年對MD4的改進版本。它對輸入仍以512位分組,其輸出是4個32位字的級聯,與 MD4 相同。MD5比MD4來得復雜,并且速度較之要慢一點,但更安全,在抗分析和抗差分方面表現更好
(3) SHA-1 及其他
SHA1是由NIST NSA設計為同DSA一起使用的,它對長度小于264的輸入,產生長度為160bit的散列值,因此抗窮舉(brute-force)性更好。SHA-1 設計時基于和MD4相同原理,并且模仿了該算法。
哈希表不可避免沖突(collision)現象:對不同的關鍵字可能得到同一哈希地址 即key1≠key2,而hash(key1)=hash(key2)。因此,在建造哈希表時不僅要設定一個好的哈希函數,而且要設定一種處理沖突的方法。可如下描述哈希表:根據設定的哈希函數H(key)和所選中的處理沖突的方法,將一組關鍵字映象到一個有限的、地址連續的地址集(區間)上并以關鍵字在地址集中的“象”作為相應記錄在表中的存儲位置,這種表被稱為哈希表。
對于動態查找表而言,1) 表長不確定;2)在設計查找表時,只知道關鍵字所屬范圍,而不知道確切的關鍵字。因此,一般情況需建立一個函數關系,以f(key)作為關鍵字為key的錄在表中的位置,通常稱這個函數f(key)為哈希函數。(注意:這個函數并不一定是數學函數)
哈希函數是一個映象,即:將關鍵字的集合映射到某個地址集合上,它的設置很靈活,只要這個地址集合的大小不超出允許范圍即可。
現實中哈希函數是需要構造的,并且構造的好才能使用的好。
那么這些Hash算法到底有什么用呢?
Hash算法在信息安全方面的應用主要體現在以下的3個方面:

(1) 文件校驗
我們比較熟悉的校驗算法有奇偶校驗和CRC校驗,這2種校驗并沒有抗數據篡改的能力,它們一定程度上能檢測并糾正數據傳輸中的信道誤碼,但卻不能防止對數據的惡意破壞。
MD5 Hash算法的“數字指紋”特性,使它成為目前應用最廣泛的一種文件完整性校驗和(Checksum)算法,不少Unix系統有提供計算md5 checksum的命令。
(2) 數字簽名
Hash 算法也是現代密碼體系中的一個重要組成部分。由于非對稱算法的運算速度較慢,所以在數字簽名協議中,單向散列函數扮演了一個重要的角色。 對 Hash 值,又稱“數字摘要”進行數字簽名,在統計上可以認為與對文件本身進行數字簽名是等效的。而且這樣的協議還有其他的優點。
(3) 鑒權協議
如下的鑒權協議又被稱作挑戰--認證模式:在傳輸信道是可被偵聽,但不可被篡改的情況下,這是一種簡單而安全的方法。
文件hash值
MD5-Hash-文件的數字文摘通過Hash函數計算得到。不管文件長度如何,它的Hash函數計算結果是一個固定長度的數字。與加密算法不同,這一個Hash算法是一個不可逆的單向函數。采用安全性高的Hash算法,如MD5、SHA時,兩個不同的文件幾乎不可能得到相同的Hash結果。因此,一旦文件被修改,就可檢測出來。
Hash函數還有另外的含義。實際中的Hash函數是指把一個大范圍映射到一個小范圍。把大范圍映射到一個小范圍的目的往往是為了節省空間,使得數據容易保存。除此以外,Hash函數往往應用于查找上。所以,在考慮使用Hash函數之前,需要明白它的幾個限制:
1. Hash的主要原理就是把大范圍映射到小范圍;所以,你輸入的實際值的個數必須和小范圍相當或者比它更小。不然沖突就會很多。
2. 由于Hash逼近單向函數;所以,你可以用它來對數據進行加密。
3. 不同的應用對Hash函數有著不同的要求;比如,用于加密的Hash函數主要考慮它和單項函數的差距,而用于查找的Hash函數主要考慮它映射到小范圍的沖突率。
應用于加密的Hash函數已經探討過太多了,在作者的博客里面有更詳細的介紹。所以,本文只探討用于查找的Hash函數。
Hash函數應用的主要對象是數組(比如,字符串),而其目標一般是一個int類型。以下我們都按照這種方式來說明。
一般的說,Hash函數可以簡單的劃分為如下幾類:
1. 加法Hash;
2. 位運算Hash;
3. 乘法Hash;
4. 除法Hash;
5. 查表Hash;
6. 混合Hash;













 工商網監
工商網監
評論