
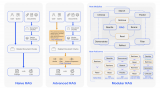


斯坦福繼Flash Attention V1和V2又推出Flash Decoding
斯坦福大學此前提出的FlashAttention算法,能夠在BERT-large訓練中節(jié)省15%,將....

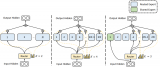
利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(tǒng)(下)
對于語言模型(LLM)幻覺,知識圖譜被證明優(yōu)于向量數(shù)據(jù)庫。知識圖譜提供更準確、多樣化、有趣、邏輯和一....

利用知識圖譜與Llama-Index技術構建大模型驅動的RAG系統(tǒng)(上)
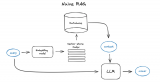
向量數(shù)據(jù)庫是一組高維向量的集合,用于表示實體或概念,例如單詞、短語或文檔。向量數(shù)據(jù)庫可以根據(jù)實體或概....
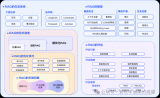
LLaMA 2是什么?LLaMA 2背后的研究工作
Meta 發(fā)布的 LLaMA 2,是新的 sota 開源大型語言模型 (LLM)。LLaMA 2 代....

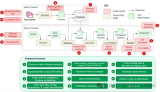
聊聊小公司如何做大模型
通過SFT、DPO、RLHF等技術訓練了領域寫作模型。實測下來,在該領域寫作上,強于國內大多數(shù)的閉源....
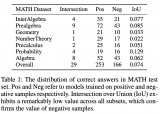
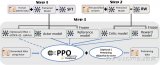
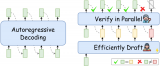
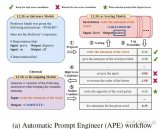
LLM推理加速新范式!推測解碼(Speculative Decoding)最新綜述
這個問題隨著LLM規(guī)模的增大愈發(fā)嚴重。并且,如下左圖所示,目前LLM常用的自回歸解碼(autoreg....
大模型微調實踐心得與認知深化
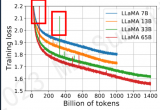
.通常CPT開始的階段會出現(xiàn)一段時間的loss上升,隨后慢慢收斂,所以學習率是一個很重要的參數(shù),這很....
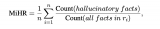

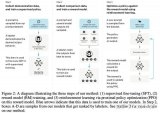

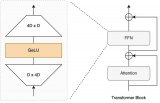
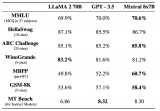
8x7B MoE與Flash Attention 2結合,不到10行代碼實現(xiàn)快速推理
我們都知道,OpenAI 團隊一直對 GPT-4 的參數(shù)量和訓練細節(jié)守口如瓶。Mistral 8x7....
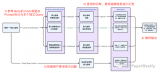
模型與人類的注意力視角下參數(shù)規(guī)模擴大與指令微調對模型語言理解的作用
近期的大語言模型(LLM)在自然語言理解和生成上展現(xiàn)出了接近人類的強大能力,遠遠優(yōu)于先前的BERT等....







 工商網監(jiān)
工商網監(jiān)